A Comprehensive Guide to Pinecone Vector Databases
This blog discusses vector databases, specifically pinecone vector databases. A vector database is a type of database that stores data as mathematical vectors, which represent features or attributes. These vectors have multiple dimensions, capturing complex data relationships. This allows for efficient similarity and distance calculations, making it useful for tasks like machine learning, data analysis, and recommendation systems.
A vector database is a type of database that stores data as mathematical vectors, which represent features or attributes. These vectors have multiple dimensions, capturing complex data relationships. This allows for efficient similarity and distance calculations, making it useful for tasks like machine learning, data analysis, and recommendation systems.
In simple terms, vectors are determined to represent data attributions. For example, a vector could represent the color of an image, the sentiment of a piece of text, or the location of a point on a map.
Pinecone Vector Databases are a specific type of vector database that is designed for high performance and scalability. Applications using vectors mainly include the following:
- Natural language processing
- Computer vision, and
- Machine learning.
Key features of the Pinecone Vector Database
Here are some of the key features of Pinecone Vector Databases:
High-performance: Pinecone Vector Databases can search and retrieve vectors very quickly. This makes them ideal for applications that require real-time or near-real-time processing of data.
Scalability: Pinecone Vector Databases can be scaled to handle large datasets and high query loads. This makes them suitable for enterprise applications.
Flexibility: Pinecone Vector Databases can be used with a variety of programming languages and machine learning frameworks thus making it possible to integrate into existing applications.
Ease of use: Pinecone Vector Databases are easy to use and manage. Therefore, developers prefer to opt for Pinecone vector databases that are not familiar with vector databases.
If you are looking for a high-performance, scalable, and flexible vector database, then Pinecone Vector Databases are a good option to consider.
Applications of Pinecone Vector Databases
Vector databases play a pivotal role in enhancing the accuracy and efficiency of data organization and retrieval for LLMs. Large Language Models, such as GPT-4 and LLaMa, leverage high-dimensional vector embeddings to understand complex relationships between words, sentences, and documents. These vector embeddings, stored and managed by vector databases, enable LLMs to generate insightful and contextually relevant outputs.
Here are some of the applications of Pinecone Vector Databases:
Natural language processing: Pinecone Vector Databases can be used for tasks such as sentiment analysis, text classification, and question answering.
Machine learning: Pinecone Vector Databases can be used to train and deploy machine learning models.
Computer vision: Pinecone Vector Databases can be used for tasks such as object detection, image classification, and face recognition.
Fraud detection: Pinecone Vector Databases can be used to detect fraudulent transactions.
Recommendation systems: Pinecone Vector Databases can be used to recommend products, movies, and other items to users
Challenges of using Pinecone Vector Databases
Here are some of the challenges of using Pinecone Vector Databases:
Dimensionality: Vector databases are designed to store and search for high-dimensional data. Storing and processing high-dimensional data can be computationally expensive for some applications.
Data quality: Accurate vector representations and query accuracy are improved by high-quality data that preserves relationships between data points. Low-quality data adversely affects the accuracy of results.
Privacy: Vector databases can store sensitive data, such as text or images. It is highly recommended to use measures like encryption and access control that can protect the privacy of data.
Complexity: Vector databases can be complex to set up and manage. so, before you deploy vector databases, gain a better understanding of their working mechanism.
Cost: Vector databases can be more expensive than traditional databases. This is because they require more hardware and software resources.
Despite these challenges, Pinecone Vector Databases can be a valuable tool for a variety of applications. If you are considering using a vector database, it is important to weigh the challenges and benefits carefully.
Tips for Mitigating the Challenges of using Pinecone Vector Databases.
Here are some great tips for mitigating the challenges of using Pinecone Vector Databases.
Amongst all the vector databases that are available, choose the right vector database for your needs. Each type of vector database consists of its own strengths and weaknesses. So, pick the one that best suits your specific application.
Use the right hardware and software. Vector databases can be demanding on hardware and software resources. The right tools include but are not limited to efficient database monitoring, replication latency, tracking throughout, and deviations from the norm
Plan for scalability. Vector databases can be scaled to handle large datasets and high query loads. However, one must plan for scalability from the beginning to avoid bottlenecks.
Monitor the database performance. Getting to know about low-par database performance after some time might harm you more, so, monitor the database's performance early on to ensure that it meets your expectations. This way you can mitigate the problems in initial stages and take corrective action.
By following these tips, you can minimize the challenges of using Pinecone Vector Databases and get the most out of this powerful tool.
How does a Pinecone Vector Database work?
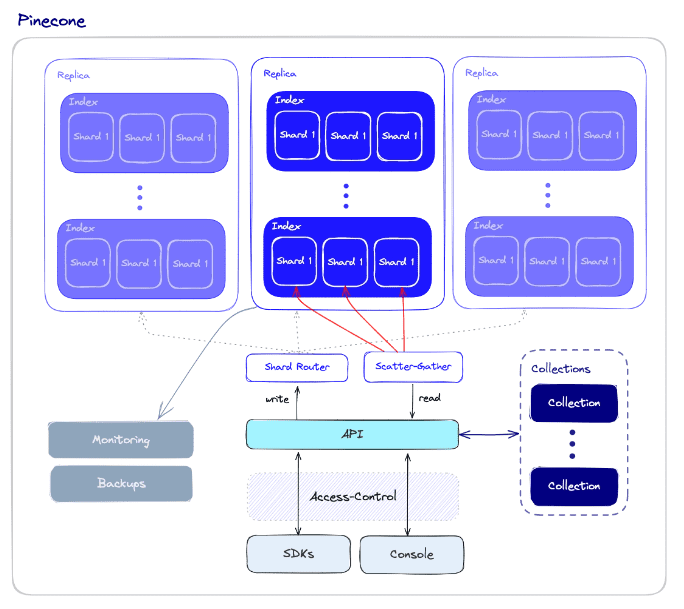
Source: Pinecone.io
Pinecone Vector Databases work by indexing the vectors and then using a variety of algorithms to search for and retrieve vectors that are similar to a query vector. The indexing process is typically done offline, so that the vectors can be quickly searched when needed.
Use cases of Pinecone Vector Databases
Pinecone Vector Databases can be used in a variety of ways. Some of the most common use cases include:
- Natural language processing (NLP): Pinecone Vector Databases can be used for NLP tasks. NLP tasks are tasks that involve understanding and processing human language. Some examples of NLP tasks include sentiment analysis, document clustering, and question answering.
- Image and video analysis: Pinecone Vector Databases can be used for image and video analysis tasks. Image and video analysis tasks are tasks that involve understanding and processing images and videos. Some examples of image and video analysis tasks include object recognition, image similarity search, and video recommendation systems.
- Anomaly detection: Pinecone Vector Databases can be used for anomaly detection. Anomaly detection is the task of finding data points that are unusual or out of place. Pinecone Vector Databases can be used to find anomalies by comparing new data points with existing vectors.
- Recommendation systems: Pinecone Vector Databases can be used to power recommendation systems. Recommendation systems are used to recommend products, movies, or other items to users based on their interests. This is achieved by tracking the user journey, past behavior, and preferences and comparing them to the data stored in the database.
- Natural language processing (NLP): Pinecone Vector Databases can be used for NLP tasks. NLP tasks are tasks that involve understanding and processing human language. It is also commonly used to perform document clustering, sentiment analysis, and question-answering. For example, Pinecone Vector Databases can be used to analyze text data to determine the sentiment of a piece of writing, such as whether it is positive, negative, or neutral.
- Image and video analysis: Pinecone Vector Databases can be used for image and video analysis tasks. Wondering what these tasks are? Well, these are involved in understanding and processing images and videos. This can be used for tasks such as object recognition, image similarity search, and video recommendation systems. For example, Pinecone Vector Databases can be used to identify objects in an image or video, such as faces, cars, or buildings.
- Anomaly detection: Pinecone Vector Databases can be used for anomaly detection. Anomaly detection is the task of finding data points that are unusual or out of place. This also proves useful in identifying suspicious transactions, cybersecurity breaches, and other related concerns. For example, financial transactions are often analyzed to look for patterns that are indicative of fraud.
- Fraud detection: Pinecone Vector Databases are used to detect fraudulent transactions by comparing new transactions to a database of previously identified fraudulent transactions. The vectors representing the new transactions are compared to the vectors representing the known fraudulent transactions.
- Cybersecurity: Pinecone Vector Databases can be used to detect cyberattacks primarily by monitoring network traffic and identifying suspicious patterns highly susceptible to cyberattacks. The vectors representing the network traffic are compared to the vectors representing known cyberattacks. If the vectors are similar, then the network traffic is likely to be malicious.
- Smart cities: Pinecone Vector Databases can be used to build smart cities. Smart cities refer to the modern living conditions that help people elevate their lifestyles. Pinecone Vector Databases help municipalities to manage traffic, energy, and keep the environment sound and safe. As technology advances, more innovative applications arise. As technology advances, more innovative applications arise.
Apart from the above-mentioned ways there are several other methods introduced as the technology continues to develop, we can expect to see even more innovative and creative applications for these powerful databases.
Conclusion
The symbiotic relationship between vector databases and LLMs is driving the evolution of data management, offering faster and more precise similarity searches, which are essential for language understanding and generation. As vector databases and LLMs continue to rise in significance, they are reshaping the landscape of AI-driven applications, ensuring efficient handling and utilization of vast amounts of data.
Ayesha Saleem Possess a passion for revamping the brands with meaningful Content Writing, Copywriting, Email Marketing, SEO writing, Social Media Marketing, and Creative Writing.