How to Finetune Mistral AI 7B LLM with Hugging Face AutoTrain
Learn how to fine-tune the state-of-the-art LLM.

Image by Editor
With the progress of LLM research worldwide, many models have become more accessible. One of the small yet powerful open-source models is Mistral AI 7B LLM. The model boasts adaptability on many use cases, showing better performance than LlaMA 2 13B on all benchmarks, employing a sliding window attention (SWA) mechanism and being easy to deploy.
Mistral 7 B's overall performance benchmark can be seen in the image below.
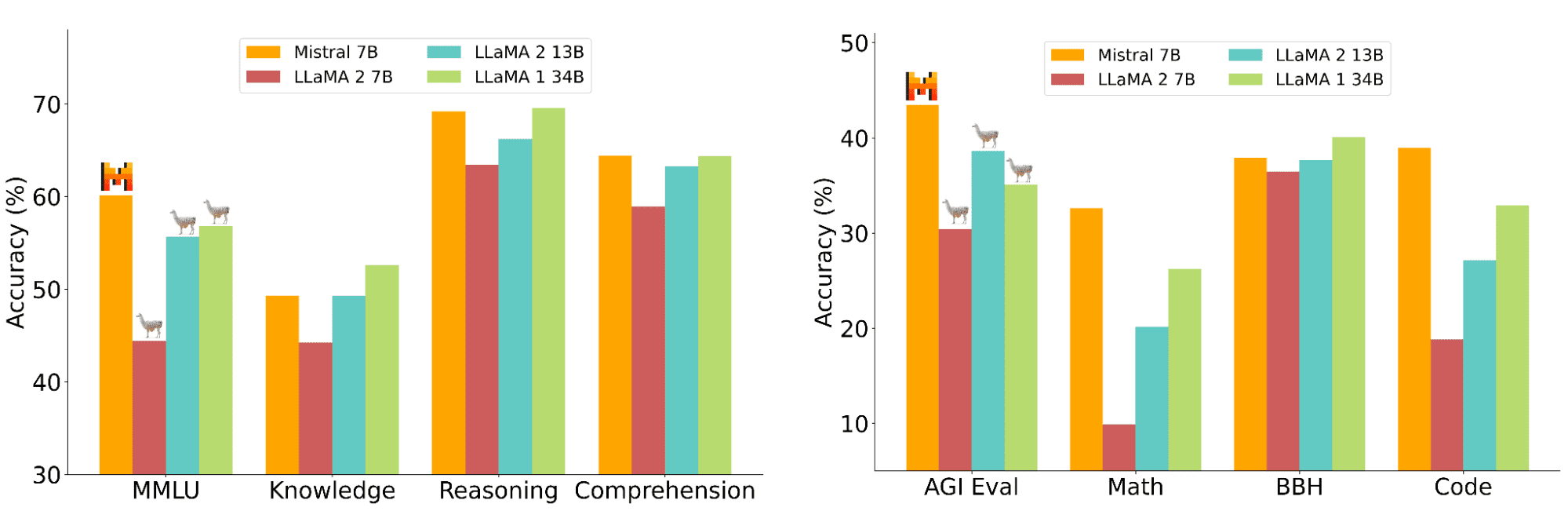
Mistral 7B Performance Benchmark (Jiang et al. (2023))
The Mistral 7B model is available in the HuggingFace as well. With this, we can use the Hugging Face AutoTrain to fine-tune the model for our use cases. Hugging Face’s AutoTrain is a no-code platform with Python API that we can use to fine-tune any LLM model available in HugginFace easily.
This tutorial will teach us to fine-tune Mistral AI 7B LLM with Hugging Face AutoTrain. How does it work? Let’s get into it.
Environment and Dataset Preparation
To fine-tune the LLM with Python API, we need to install the Python package, which you can run using the following code.
pip install -U autotrain-advanced
Also, we would use the Alpaca sample dataset from HuggingFace, which required datasets package to acquire and the transformers package to manipulate the Hugging Face model.
pip install datasets transformers
Next, we must format our data for fine-tuning the Mistral 7B model. In general, there are two foundational models that Mistral released: Mistral 7B v0.1 and Mistral 7B Instruct v0.1. The Mistral 7B v0.1 is the base foundation model, and the Mistral 7B Instruct v0.1 is a Mistral 7B v0.1 model that has been fine-tuned for conversation and question answering.
We would need a CSV file containing a text column for the fine-tuning with Hugging Face AutoTrain. However, we would use a different text format for the base and instruction models during the fine-tuning.
First, let’s look at the dataset we used for our sample.
from datasets import load_dataset
import pandas as pd
# Load the dataset
train= load_dataset("tatsu-lab/alpaca",split='train[:10%]')
train = pd.DataFrame(train)
The code above would take ten percent samples of the actual data. We would only need that much for this tutorial as it would take longer to train for bigger data. Our data sample looks like the image below.

Image by Author
The dataset already contains the text columns with a format we need to fine-tune our LLM model. That’s why we don’t need to perform anything. However, I would provide a code if you have another dataset that needs the formatting.
def text_formatting(data):
# If the input column is not empty
if data['input']:
text = f"""Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.\n\n### Instruction:\n{data["instruction"]} \n\n### Input:\n{data["input"]}\n\n### Response:\n{data["output"]}"""
else:
text = f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{data["instruction"]}\n\n### Response:\n{data["output"]}"""
return text
train['text'] = train.apply(text_formatting, axis =1)
For the Hugging Face AutoTrain, we would need the data in the CSV format so that we would save the data with the following code.
train.to_csv('train.csv', index = False)
Then, move the CSV result into a folder called data. That’s all you need to prepare the dataset for fine-tuning Mistral 7B v0.1.
If you want to fine-tune the Mistral 7B Instruct v0.1 for conversation and question answering, we need to follow the chat template format provided by Mistral, shown in the code block below.
<s>[INST] Instruction [/INST] Model answer</s>[INST] Follow-up instruction [/INST]
If we use our previous example dataset, we need to reformat the text column. We would use only the data without any input for the chat model.
train_chat = train[train['input'] == ''].reset_index(drop = True).copy()
Then, we could reformat the data with the following code.
def chat_formatting(data):
text = f"<s>[INST] {data['instruction']} [/INST] {data['output']} </s>"
return text
train_chat['text'] = train_chat.apply(chat_formatting, axis =1)
train_chat.to_csv('train_chat.csv', index =False)
We will end up with a dataset appropriate for fine-tuning the Mistral 7B Instruct v0.1 model.

Image by Author
With all the preparation set, we can now initiate the AutoTrain to fine-tune our Mistral model.
Training and Fine-tuning
Let’s set up the Hugging Face AutoTrain environment to fine-tune the Mistral model. First, let’s run the AutoTrain setup using the following command.
!autotrain setup
Next, we would provide the information required for AutoTrain to run. For this tutorial, let’s use the Mistral 7B Instruct v0.1.
project_name = 'my_autotrain_llm'
model_name = 'mistralai/Mistral-7B-Instruct-v0.1'
Then, we would add the Hugging Face information if you want to push your model to the repository.
push_to_hub = False
hf_token = "YOUR HF TOKEN"
repo_id = "username/repo_name"
Lastly, we would initiate the model parameter information in the variables below. You can change them to see if the result is good.
learning_rate = 2e-4
num_epochs = 4
batch_size = 1
block_size = 1024
trainer = "sft"
warmup_ratio = 0.1
weight_decay = 0.01
gradient_accumulation = 4
use_fp16 = True
use_peft = True
use_int4 = True
lora_r = 16
lora_alpha = 32
lora_dropout = 0.045
We can tweak many parameters but will not discuss them in this article. Some tips to improve the LLM fine-tuning include using a lower learning rate to maintain pre-learned representations and vice versa, avoiding overfitting by adjusting the number of epochs, using larger batch size for stability, or adjusting the gradient accumulation if you have a memory problem.
When all the information is ready, we will set up the environment to accept all the information we have set up previously.
import os
os.environ["PROJECT_NAME"] = project_name
os.environ["MODEL_NAME"] = model_name
os.environ["PUSH_TO_HUB"] = str(push_to_hub)
os.environ["HF_TOKEN"] = hf_token
os.environ["REPO_ID"] = repo_id
os.environ["LEARNING_RATE"] = str(learning_rate)
os.environ["NUM_EPOCHS"] = str(num_epochs)
os.environ["BATCH_SIZE"] = str(batch_size)
os.environ["BLOCK_SIZE"] = str(block_size)
os.environ["WARMUP_RATIO"] = str(warmup_ratio)
os.environ["WEIGHT_DECAY"] = str(weight_decay)
os.environ["GRADIENT_ACCUMULATION"] = str(gradient_accumulation)
os.environ["USE_FP16"] = str(use_fp16)
os.environ["USE_PEFT"] = str(use_peft)
os.environ["USE_INT4"] = str(use_int4)
os.environ["LORA_R"] = str(lora_r)
os.environ["LORA_ALPHA"] = str(lora_alpha)
os.environ["LORA_DROPOUT"] = str(lora_dropout)
We would use the following command to run the AutoTrain in our notebook.
!autotrain llm \
--train \
--model ${MODEL_NAME} \
--project-name ${PROJECT_NAME} \
--data-path data/ \
--text-column text \
--lr ${LEARNING_RATE} \
--batch-size ${BATCH_SIZE} \
--epochs ${NUM_EPOCHS} \
--block-size ${BLOCK_SIZE} \
--warmup-ratio ${WARMUP_RATIO} \
--lora-r ${LORA_R} \
--lora-alpha ${LORA_ALPHA} \
--lora-dropout ${LORA_DROPOUT} \
--weight-decay ${WEIGHT_DECAY} \
--gradient-accumulation ${GRADIENT_ACCUMULATION} \
$( [[ "$USE_FP16" == "True" ]] && echo "--fp16" ) \
$( [[ "$USE_PEFT" == "True" ]] && echo "--use-peft" ) \
$( [[ "$USE_INT4" == "True" ]] && echo "--use-int4" ) \
$( [[ "$PUSH_TO_HUB" == "True" ]] && echo "--push-to-hub --token ${HF_TOKEN} --repo-id ${REPO_ID}" )
If the fine-tuning process succeeds, we will have a new directory of our fine-tuned model. We would use this directory to test our newly fine-tuned model.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "my_autotrain_llm"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path)
With the model and tokenizer ready to use, we would try the model with an input example.
input_text = "Give three tips for staying healthy."
input_ids = tokenizer.encode(input_text, return_tensors="pt")
output = model.generate(input_ids, max_new_tokens = 200)
predicted_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(predicted_text)
Output:
Give three tips for staying healthy.
- Eat a balanced diet: Make sure to include plenty of fruits, vegetables, lean proteins, and whole grains in your diet. This will help you get the nutrients you need to stay healthy and energized.
- Exercise regularly: Aim for at least 30 minutes of moderate exercise, such as brisk walking or cycling, every day. This will help you maintain a healthy weight, reduce your risk of chronic diseases, and improve your overall physical and mental health.
- Get enough sleep: Aim for 7-9 hours of quality sleep each night. This will help you feel more rested and alert during the day, and it will also help you maintain a healthy weight and reduce your risk of chronic diseases.
The output from the model has been close to the actual output from our training data, shown in the image below.
- Eat a balanced diet and make sure to include plenty of fruits and vegetables.
- Exercise regularly to keep your body active and strong.
- Get enough sleep and maintain a consistent sleep schedule.
Mistral models certainly are powerful for their size, as simple fine-tuning has already shown a promising result. Try out your dataset to see if it suits your work.
Conclusion
The Mistral AI 7B family model is a powerful LLM model that boasts higher performance than LLaMA and great adaptability. As the model is available in the Hugging Face, we can employ HuggingFace AutoTrain to fine-tune the model. There are two models currently available to fine-tune in the Hugging Face; Mistral 7B v0.1 for the base foundation model, and the Mistral 7B Instruct v0.1 for conversation and question answering. The fine-tuning showed promising results even with a quick training process.
Cornellius Yudha Wijaya is a data science assistant manager and data writer. While working full-time at Allianz Indonesia, he loves to share Python and data tips via social media and writing media. Cornellius writes on a variety of AI and machine learning topics.