The Data Maturity Pyramid: From Reporting to a Proactive Intelligent Data Platform
This article describes the data maturity pyramid and its various levels, from simple reporting to AI-ready data platforms. It emphasizes the importance of data for business and illustrates how data platforms serve as the driving force behind AI.
Today more than ever, organizations rely on data to make informed decisions and gain a competitive edge. The journey to becoming a data-driven organization involves a number of steps, including progressively improving data capabilities, leveraging AI and ML technologies, and adopting robust data governance practices.
This article explores these steps in detail — from reporting and data governance, to data products as a foundation for AI/ML and a proactive intelligent data platform (PIDP). We also delve into the role of Data Engineers in this journey.
Data Maturity in a Corporate Setting
In a corporate environment, multiple tiers of data maturity can be distinguished, signifying varying degrees of a company's advancement in utilizing its data assets. Within this context, the concept of a Data Maturity Model naturally emerges as a hierarchical pyramid composed of different layers. Moreover, the journey toward greater data maturity is an ongoing cycle of enhancements, aimed not only at reaching increasingly advanced levels but also at refining and optimizing the capabilities already attained.
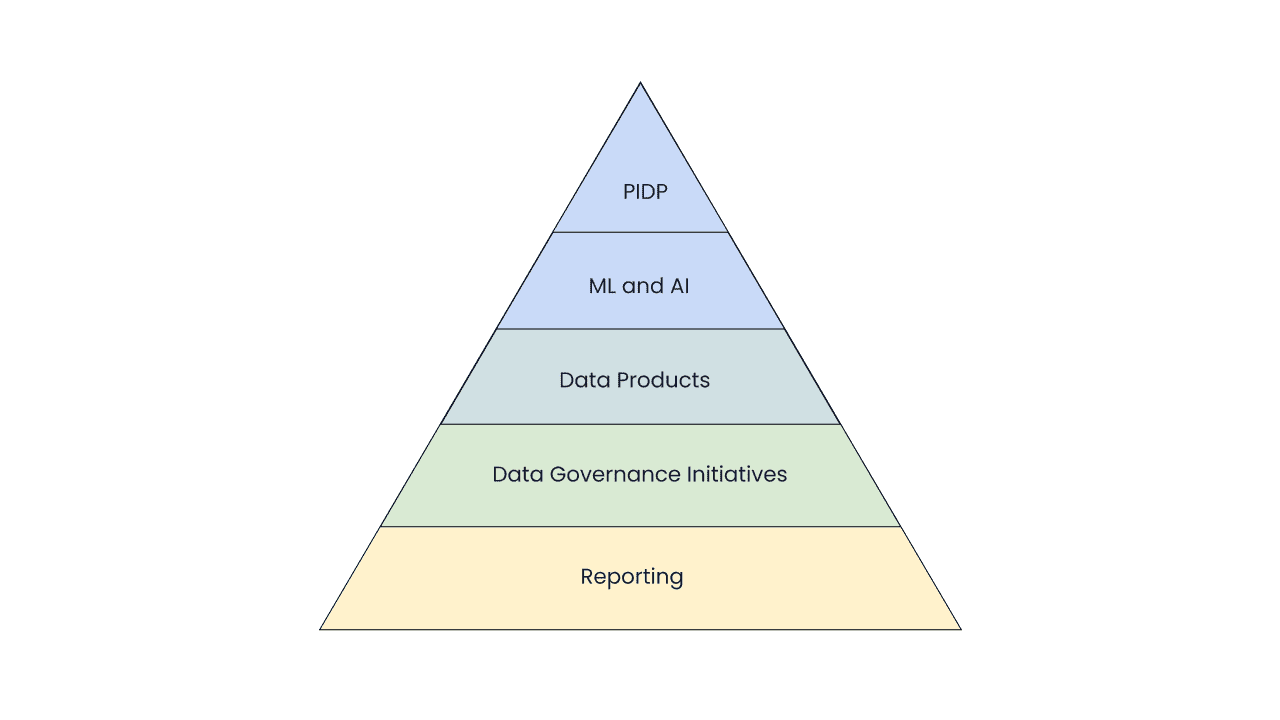
A pyramid lets us demonstrate two features at once:
- Every subsequent level is located above the previous one;
- The expansion of the next level inevitably leads to the expansion of the level below it.
This means that as data products evolve in an organization, the approaches and technologies in data management are also improved. Trust, discoverability, security, consistency, and other characteristics of data are likely to improve, step by step, which leads to improvements at every level.
Let us describe a scenario of a company in the process of adopting and implementing AI and ML.
We have a telecommunications company that:
- Has a deep understanding of its corporate data from various sources;
- Maintains reliable and consistent corporate-level reporting;
- Uses marketing campaign management systems that rely on real-time data.
The company decides to implement an advanced AI/ML-driven system, to offer its customers the best next plan. This move unlocks a new level of data utilization, and also improves all preceding levels of the pyramid: it brings in fresh data for reporting, introduces novel challenges regarding data security and compliance, and provides valuable insights into marketing.
Consider that any data initiative does not necessarily need to start from the bottom up – once your organization has become proficient enough at one level, you can move on to the next. However, some levels of the pyramid may be in completely different data transformation stages. For example, your organization may decide to begin data transformation in the AI space because that appears to be the greatest opportunity from a business perspective.
Suppose your organization wants to use AI and ML to quickly find the least expensive plane tickets, taking into account train and bus transfers, and other trip details. Solving this case requires a fairly specific and limited set of data. However, the level of reporting or data management in the organization may not have evolved enough to support this feature with existing data. In this case, you are not dealing with a data pyramid because the first two levels cannot be used as a foundation for AI/ML — your AI/ML level is afloat. Building analytical systems that “float” is extremely difficult, but possible, as a means to accelerate time-to-market, and to quickly test specific AI use cases in production. Advanced development of the foundational pyramid levels will most likely be delayed, but the system will eventually attain its final and sustainable pyramid form.
Data-Driven Capabilities and Competitive Advantage
When talking about the advantages of improving your data maturity, it's important to note that the more you enhance it, the bigger the rewards. In simple terms, the higher your current data maturity level, the more value you'll get from making even next small improvements. This kind of rapid growth in benefits is similar to what's described as an "exponential function", where the rate of growth is tied to the current state of what you're measuring.
This relationship is easy to notice in analytical systems. Each successive level can and should build upon the previous one, simultaneously unlocking entirely new benefits and features that were not accessible at earlier stages.
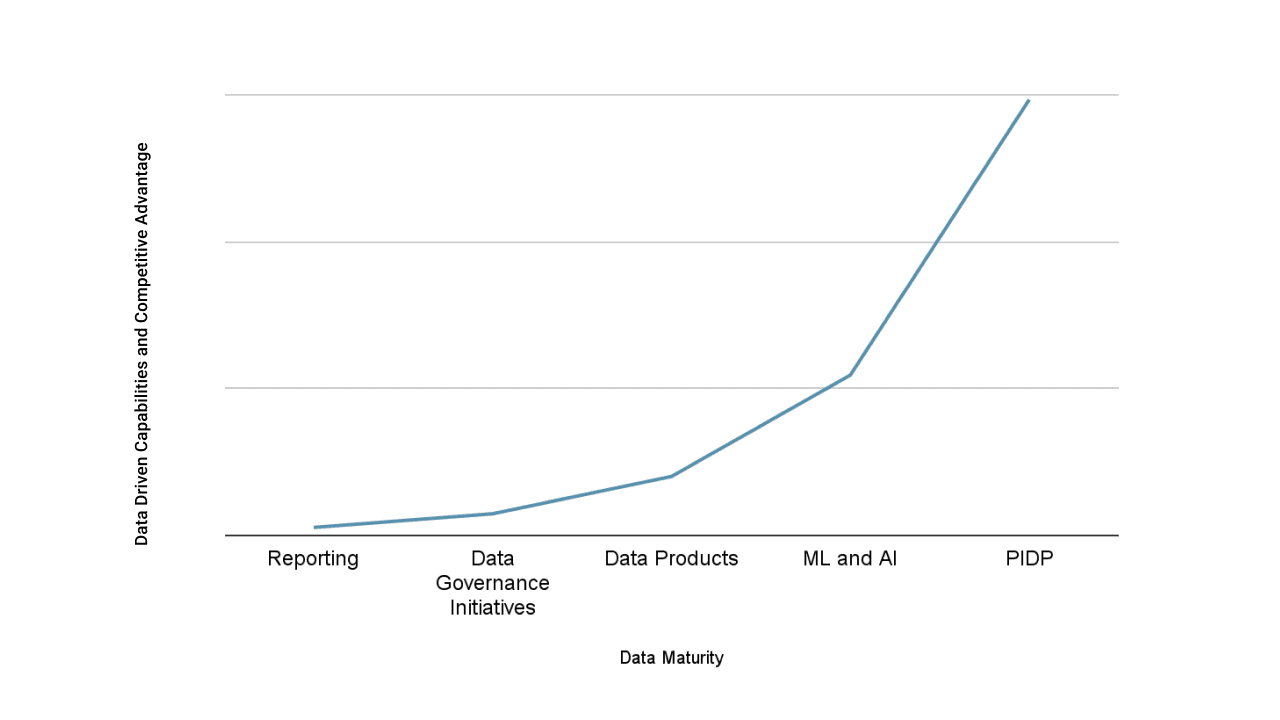
Picture 2. Correlation between data-driven capabilities and competitive advantage across levels of data maturity
To demonstrate how this works, let’s assume your organization has developed a new data product — a customer recommendation engine for an e-commerce platform. The engine processes historical customer behavior data to suggest personalized product recommendations to users. Initially, the system is rule-based and relies on predefined heuristics to make recommendations.
In the transition to the AI/ML level, the team decides to implement a machine learning model. For example, a collaborative filtering model, or a deep learning-based recommendation system. The model can analyze vast amounts of data, identify complex patterns in data, and make accurate and personalized product recommendations for every user.
As the recommendation system is deployed, it continues to collect even more data from user interactions. The more users engage with the platform and receive recommendations, the more data the system accumulates. This data growth allows ML models to continually learn and refine their recommendations, leading to ever-increasing accuracy and effectiveness of the recommendation engine.
Note: Each of these transitions will be discussed in more detail later. At this stage, let’s keep in mind that every transition to a new maturity level is associated with overall growth in the complexity of the system. Such growth means using new tools, acquiring new team skills, building additional connections between systems and teams (while avoiding silos), and, most importantly, gaining a competitive advantage. Your organization gains more benefits at every level while your competitors lag behind.
Complex systems are inherently more challenging to develop than simple ones. Moreover, not all companies have the resources to manage the development process, from ideation to implementation, to at-scale adoption, to support.
Imagine a supply chain management company that has implemented several machine learning models to forecast demand, optimize inventory, and identify inefficiencies in its logistics. Having such a data- and AI/ML-driven solution that leverages advanced analytics and predictive insights is a substantial competitive advantage.
Now, let’s consider that the company wants to take another step forward towards a Proactive Intelligent Data Platform (PIDP) with Geneverative AI capabilities. Such a system would evolve from identifying risks and opportunities from data, to proactively generating actionable plans based on this data, using Large Language Models (LLMs). Now, instead of simply notifying stakeholders about potential issues or providing insights, the system provides them with an intelligent, well-crafted action plan. Generative AI can be harnessed to initiate processes, call internal or third-party APIs, and even execute generated plans autonomously.
In the case of our supply chain management system, this transition could enable it to not only predict potential stock shortages, but also to actively engage with suppliers, place orders, and coordinate logistics, all in real time, without human intervention. Such a system could evaluate results, learn from them, and refine its next action. Human feedback would remain crucial, ensuring alignment with strategic goals, and ensuring continuous improvement.
The incorporation of Generative AI into a Proactive Intelligent Data Platform is not just a technological leap – it is a strategic transformation. In the supply chain domain, this could mean reduced lead times, minimal stockouts, and maximized asset utilization, all of which translate into real business value.
While competitors grapple with rules-based systems or traditional machine learning algorithms, a company operating at the PIDP level is navigating the complexity of modern supply chains with a nimbleness and foresight that sets it apart.
Let’s explore each level of the data pyramid in more detail, to understand its role in the journey from reporting to PIDP.
Level 1 - Reporting
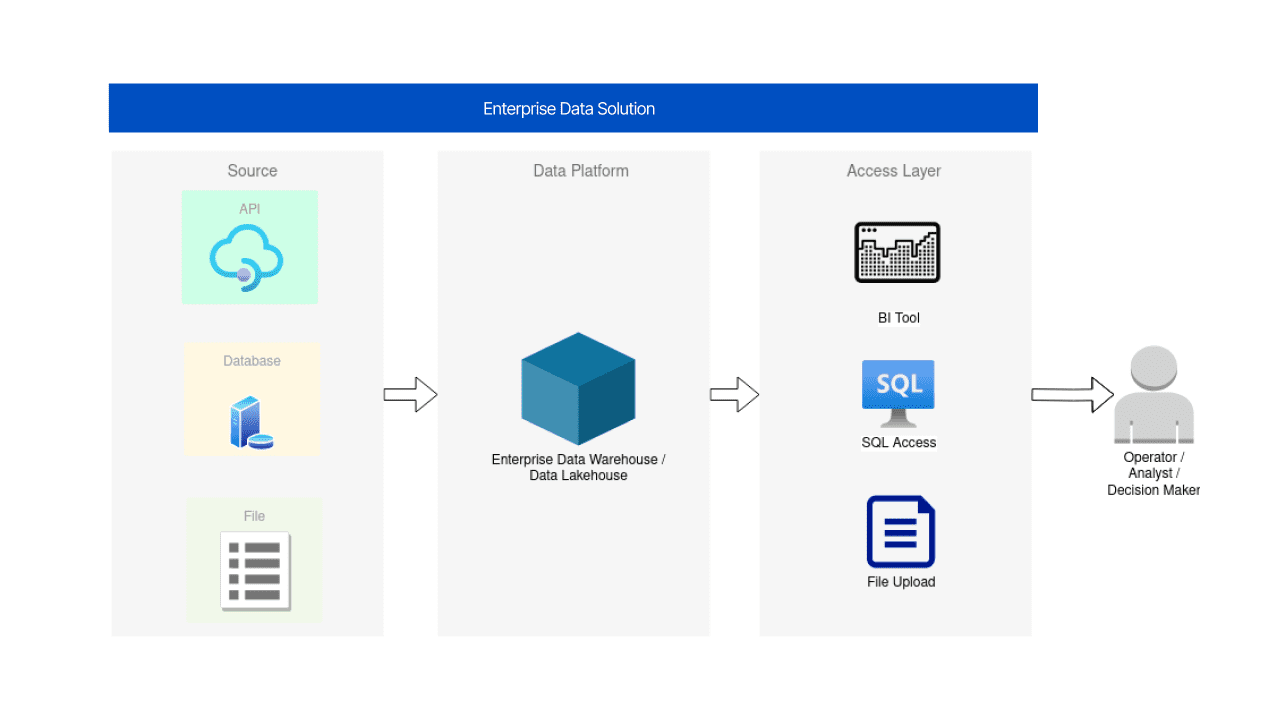
Reporting is an essential domain for data engineers. It involves designing and building fundamental data platforms that can serve as a foundation for analytics and other data-driven subsystems and solutions. Data engineers are responsible for establishing robust data pipelines and infrastructure that can collect, store, and process data efficiently and securely. These foundational data platforms enable data engineers to ensure businesses that their data is easily accessible, well-organized, and prepared for further analysis and reporting.
To add some historical context, consider that only five years ago, the use of real-time tools indicated a more mature data platform, compared to a batch platform. Today, with some exceptions, the boundaries are more blurred. The complexity of batch and streaming processing is not much different; the only exceptions are data lineage, security and discovery – and in general in what we call data governance. In those domains, many changes have occurred due to real-time processing, with expectations of more enhancements in the near future.
Having said that, it's possible to achieve near real-time data integration from almost all sources, and the Event Gateway is a suitable choice for consistent data ingestion. For a few data sources with significantly larger data volumes than others in an organization, batch ingestion might be preferred. For example, raw data from Google Analytics for a medium-sized online company might account for half of all processed data. Whether it's worthwhile to ingest this data at the same speed as transactional system data, potentially at a high cost, is debatable. However, as technology progresses, the need to choose between batch and real-time may decrease.
With real-time data products, there is still a significant gap in data governance capabilities and maintenance overhead of real-time data processing, compared to batch processing. For that reason, it is recommended to only rely on real-time data processing in a limited range of use cases, like ad bidding or fraud detection, where data freshness is more important than data quality.
A number of products benefit more from higher levels of transparency and quality than from speed. They can rely on data processing in micro batches, or in a traditional batch mode (e.g finance reporting). For more details, please read Dan Taylor's post on LinkedIn.
Level 2 - Data Governance Initiatives
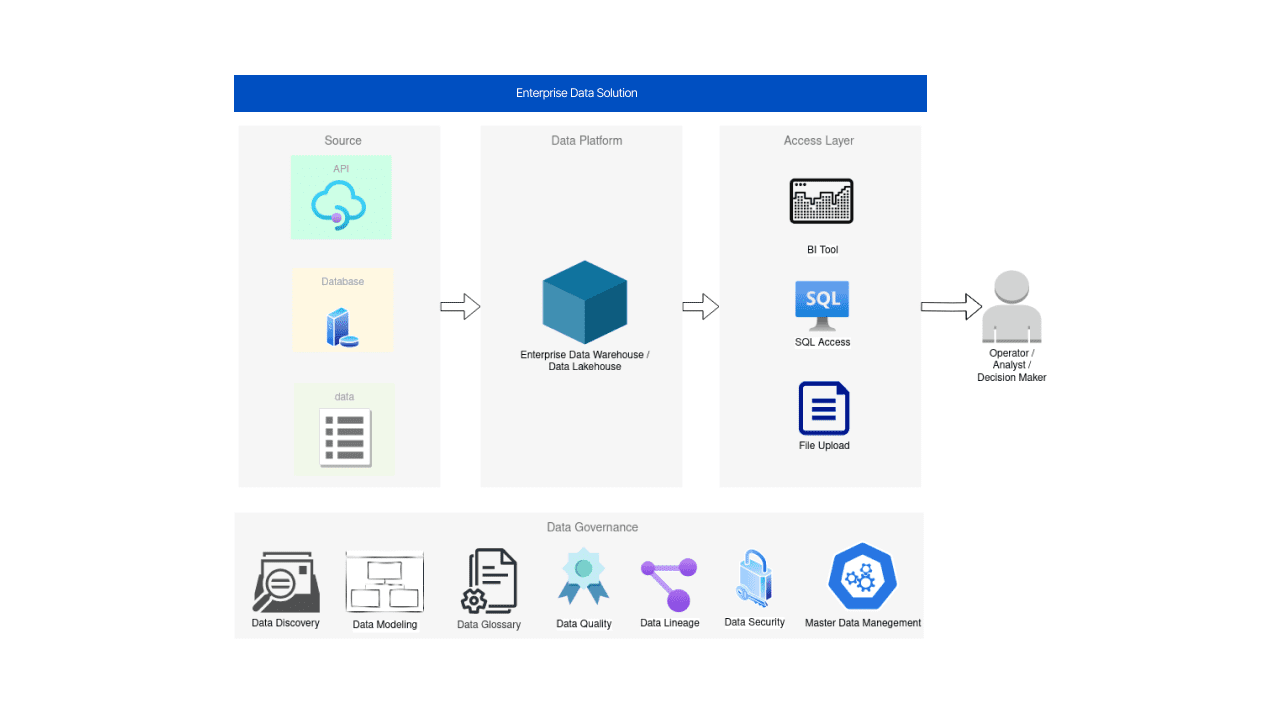
Data governance is a broad term, with varying definitions. But if we try to roughly describe what data governance initiatives are, we will eventually end up referring to its components, features, and practices, such as: data discovery, data modeling, data glossary, data quality, data lineage, data security, and master data management (MDM).
The transition to conscious and systematic practices in data governance can result in a staggering boost in data literacy, speed, reliability, and security. These are only a fraction of benefits that are realized when moving away from simple reporting toward corporate data management systems.
Demand for data democratization inevitably increases the requirement for more efficient data access management. Unification of metrics at the company level leads to the need to create glossaries, unified reports, manage data fragmentation and duplication, and so on — all of which help save time on handling and using data in specific use cases. Such data solutions and products drive the demand for data discoverability, and more detailed cataloging and data usage.
At the data governance level, data engineers usually work in close collaboration with software development teams to build and maintain systems like reference data management tools. The same goes for data observability instrumentation like OpenLineage. Ideally it would be a unified platform for all types of data governance initiatives that, as an example, Open Data Discovery platform aims to become.
Level 3 - Data Products
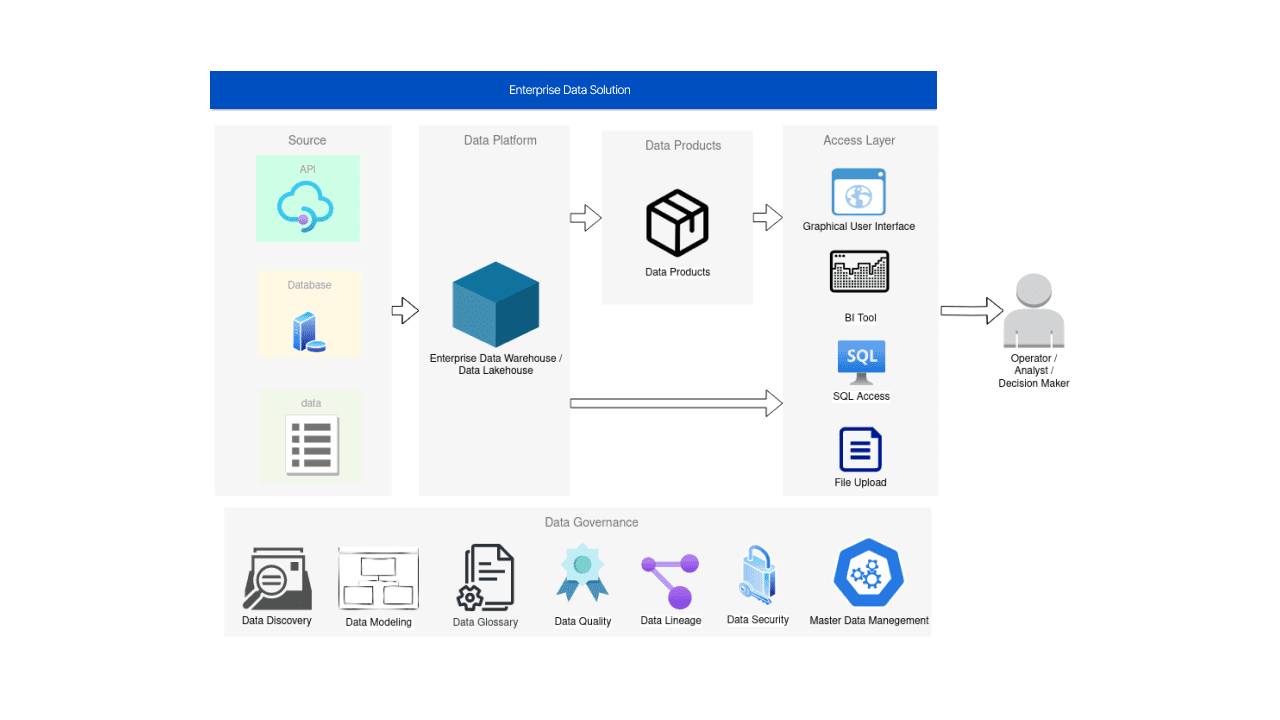
The basic data products are not associated with any AI/ML technologies and use cases. They generally do not require advanced analytics, either. Because a wide range of issues and tasks can be solved just by using consolidated data that is stored in corporate data platforms. These are:
- Almost all operations with historical data;
- Transaction systems support that is achieved by removing data load;
- High-speed, at-scale calculations on large amounts of data.
To name some more specific examples, these are systems and tools that are used in sales & marketing systems, A/B testing, billing systems, and so on.
At the data product stage, software and application development teams also play a vital role. Communicating with them on technology aspects of the data product, while bearing business goals in mind is key to successful use of data for any use case.
Note that the development of APIs or end-to-end solutions should always be part of the general approach to development in corporations. Cross-functional development teams can bring the most benefits to the table and, in relation to data, it makes sense to talk about the concept of Data Mesh.
Data Mesh revolutionizes the way organizations can manage data. Instead of seeing data as a monolithic entity, Data Mesh encourages organizations to treat data as a product. By doing this, it decentralizes data ownership and helps teams develop and maintain their own data products, thus reducing bottlenecks and dependencies on centralized data teams.
Level 4 - AI and ML Solutions
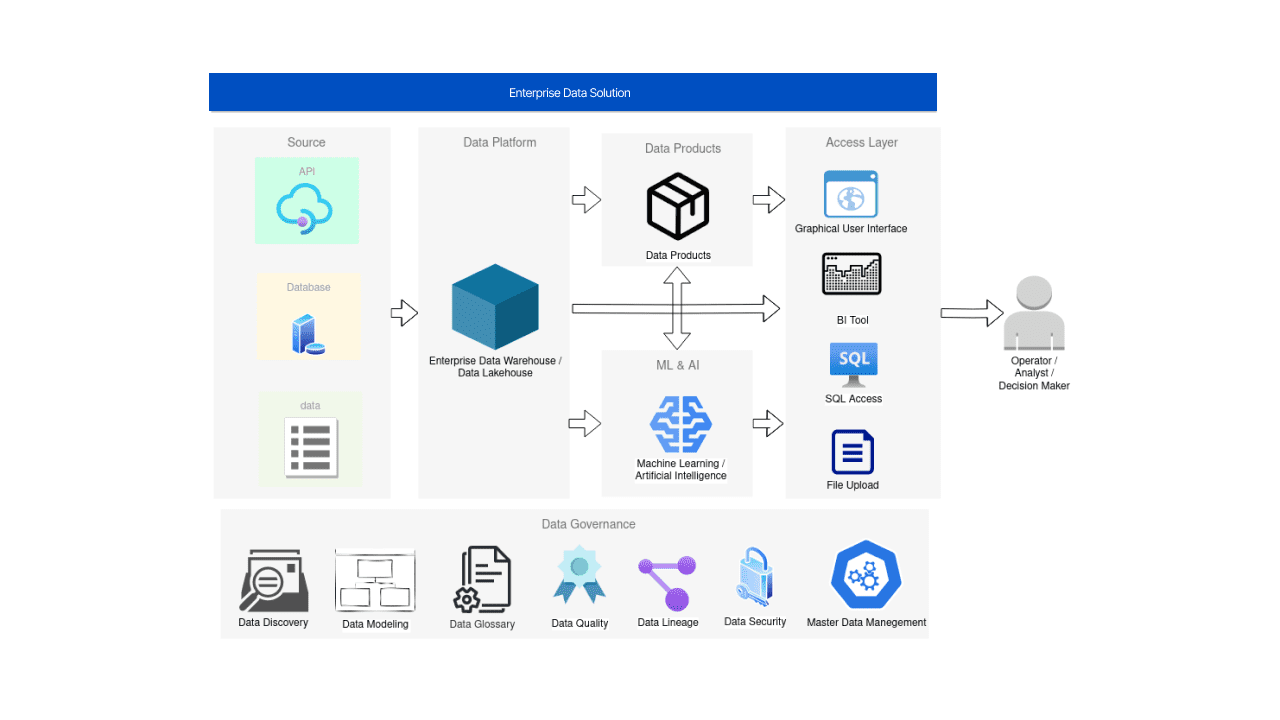
AI is the new electricity. But we are still in the in-between time: the potential of AI is clear, but not that many companies have overhauled their business models enough to take advantage of AI, end-to-end and at scale.
As perfectly said in the speech by Stephen Brobst, the main value of and from AI will be realized when AI is ubiquitous. So far, the final beneficiaries do not pay attention to the ubiquity factor, oftentimes trying to work on use cases that cannot be brought into the real world.
From a data engineering perspective, AI is fueled by data. That is why, we should always remember about feature stores and ML model operationalization — components that help to continuously and repeatedly transform data into AI/ML solutions in production. In more detail, these components and associated roles are described in Databricks’s “The Big Book of MLOps”. This comprehensive guide delineates the specific functions of five key roles – Data Engineer, Data Scientist, ML Engineer, Business Stakeholder, Data Governance Officer – and their interplay across seven pivotal processes – Data Preparation, Exploratory Data Analysis (EDA), Feature Engineering, Model Training, Model Validation, Deployment, and Monitoring.
It’s also worth remembering that AI’s full potential is truly realized only when its modules are integrated into the corporation's overall infrastructure, processes, and even culture. When various systems and individuals seamlessly collaborate as one cohesive unit, that is when the transition to the Proactive Intelligent Data Platform starts to make sense organization-wide.
Level 5 - Proactive Intelligent Data Platform (PIDP)
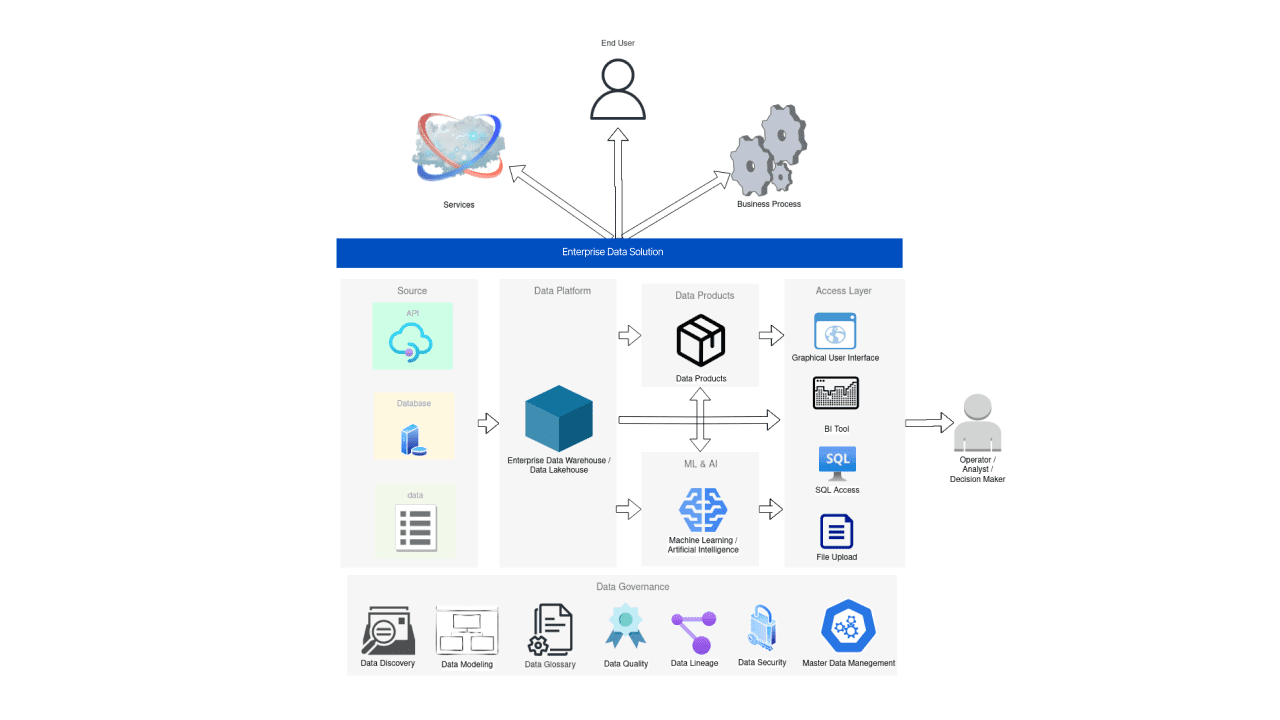
The Proactive Intelligent Data Platform (PIDP) is the top level of the data maturity pyramid. In its core, it involves seamless integration of AI/ML technologies and advanced analytics into business as usual (BAU) processes, organization-wide.
Let’s take a closer look at the PIDP in the context of one of the recently emerged AI niches — Generative AI. Specifically, we will explore three domains – digital twins, control towers, and command centers – in which the transformative potential of Generative AI is most evident.
Consider large factories developing digital twins of their facilities for enhanced operational efficiency. In such an advanced setup, the operator, despite having all essential controls, faces the immense challenge of continuous decision-making. Introducing a Generative AI agent that can help communicate with digital twins in natural language streamlines and automates routine tasks, risk evaluation, opportunity analysis, and assists in informed decision-making.
In a similar fashion, in the telecommunications industry control towers are fitness to the rising trend of operators globally investing in optimization, timely problem detection, and accident prevention. These centers receive vast amounts of data from different authority levels. The human operators are burdened with the responsibility of being highly skilled and informed for effective task management. Incorporating Generative AI could alleviate the routine and intricate aspects of their operations.
Now, consider the command centers, especially within the supply chain sector. Operational decisions here often require multi-departmental collaboration, such as the supply chain unit, and financial and legal departments, among many others. These teams, with different expertise and partial insights, should decide on their actions collaboratively. In this context, the utility of Generative AI as a part of a unified corporate management platform becomes clear. These Gen AI models can identify risks and opportunities, gauge their enterprise-wide impact, analyze potential resolutions, and much more.
Data plays a key role in each of these domains. It is the crown that winds the entire organization, enabling it to operate smoothly, like a clockwork.
The PIDP is a powerful tool that enables organizations to proactively respond to challenges, make data-driven decisions, and stay ahead of the competition.
The role of data engineers at this stage is the most important and, at the same time, probably not so noticeable. Since the corporation already receives main benefits from data-driven products, the seamless integration of AI into the decision-making process, from simple analytics dashboards to well-coordinated interaction of various departments of the corporation, is the key. The organization evolves from raw utility applications powered by data, to ease-of-use apps that can drive business value smoothly in a non-specialized, non-technical environment.
However, it is important to understand that the link in almost every node at this stage is data, its management and its processing.This, of course, is the main merit of the work of data engineers.
Conclusion
The journey to a proactive intelligent data platform is challenging but essential for modern organizations seeking to thrive in a data- and AI-driven world. By progressing through various data maturity levels, embracing data-driven capabilities, establishing robust data governance initiatives, and harnessing the potential of AI and ML, organizations can unlock a whole range of critical competitive advantages, to stay ahead of the curve.
The Proactive Intelligent Data Platform represents the culmination of this journey and the final level of the data maturity pyramid. It can empower organizations to lead, innovate, and succeed in a rapidly evolving business landscape.
Raman Damayeu is proficient in both traditional data warehousing and the latest cloud solutions. A fervent advocate of top-notch data governance, Raman has a special affinity for platforms akin to Open Data Discovery. Within Provectus, he consistently propels data-driven initiatives forward, helping to take the industry to the next level of data processing.