
Abstract
Cancer is a life-threatening disease resulting from a genetic disorder and a range of metabolic anomalies. In particular, lung and colon cancer (LCC) are among the major causes of death and disease in humans. The histopathological diagnoses are critical in detecting this kind of cancer. This diagnostic testing is a substantial part of the patient’s treatment. Thus, the recognition and classification of LCC are among the cutting-edge research regions, particularly in the biological healthcare and medical fields. Earlier disease diagnosis can significantly reduce the risk of fatality. Machine learning (ML) and deep learning (DL) models are used to hasten these cancer analyses, allowing researcher workers to analyze a considerable proportion of patients in a limited time and at a low price. This manuscript proposes the Predictive Analytics of Complex Healthcare Systems Using the DL-based Disease Diagnosis Model (PACHS-DLBDDM) method. The proposed PACHS-DLBDDM method majorly concentrates on the detection and classification of LCC. At the primary stage, the PACHS-DLBDDM methodology utilizes Gabor Filtering (GF) to preprocess the input imageries. Next, the PACHS-DLBDDM methodology employs the Faster SqueezeNet to generate feature vectors. In addition, the convolutional neural network with long short-term memory (CNN-LSTM) approach is used to classify LCC. To optimize the hyperparameter values of the CNN-LSTM approach, the Chaotic Tunicate Swarm Algorithm (CTSA) approach was implemented to improve the accuracy of classifier results. The simulation values of the PACHS-DLBDDM approach are examined on a medical image dataset. The performance validation of the PACHS-DLBDDM model portrays the superior accuracy value of 99.54% over other DL models.
Similar content being viewed by others

Introduction
The World Health Organization (WHO) states that cancer is the leading cause of death all around the globe1. After breast cancer, Lung and colorectal (both rectum and colon) cancers are the most general types globally, with incidence rates of 10% and 11.4%, correspondingly, in 2020. Despite all, the possibility of synchronic occurrence among LCC is less2. So, the exact analysis of these tumour sub-types is critical to determining the treatment process at an earlier stage of the illness3. However, reliable sub-types of these tumours are not possible with non-invasive constant and minimum invasive methods, namely histopathology, which is needed for accurate illness classification and to increase the treatment quality. Additionally, the physical grading of histopathological imageries might be annoying for pathologists4. Furthermore, the exact grading of the LCC sub-types needs experienced pathologists, where the physical grading will lead to fault. So, automatic image processing procedures for LCC sub-type screening are necessary to decrease the trouble for pathologists. Recently, several CAD systems have been launched to automatically check cancer growth symptoms in the colon5.
Artificial intelligence (AI) is an effective method that helps the diagnostic system to identify cancer precisely; the general AI methods for the detection of cancer include recognition of colon cancer utilizing DL methods from the diagnosis of histopathological images (HIs) and recognition of colon cancer utilizing ML methods from the diagnosis of HIs6. At present, technical developments in image processing and medical imaging have provided many cost-effective CAD models. The older method’s aim is to perform pattern-recognition-associated methods for automatic cancer analysis7. This approach mines a normal set of handcrafted features from biology images and trained classifiers’ over-use features to classify the cancerous cells8. Nowadays, medical image processing has obtained everyone’s concern in deep neural networks (DNNs), which unites feature extraction and classification in a combined learning structure. DNN has effectively established outstanding tasks in object detection, image identification, and image segmentation9. Convolutional Neural Networks (CNNs) are DNN methods widely used in computer vision (CV) tasks due to their promising target classification and recognition achievement. The performance mainly depends on the depth of CNN. On the other hand, expanding the CNN depth may produce problems with vanishing gradient and saturated accuracy, which becomes a primary challenge for the network10.
This manuscript proposes the Predictive Analytics of Complex Healthcare Systems Using the DL-based Disease Diagnosis Model (PACHS-DLBDDM) method. The proposed PACHS-DLBDDM method majorly concentrates on the detection and classification of LCC. At the primary stage, the PACHS-DLBDDM methodology utilizes Gabor Filtering (GF) to preprocess the input imageries. Next, the PACHS-DLBDDM methodology employs the Faster SqueezeNet to generate feature vectors. In addition, the CNN with long short-term memory (CNN-LSTM) approach is used to classify LCC. To optimize the hyperparameter values of the CNN-LSTM approach, the Chaotic Tunicate Swarm Algorithm (CTSA) approach was implemented to improve the accuracy of classifier results. The simulation values of the PACHS-DLBDDM approach are examined on a medical image dataset. The key contribution of the PACHS-DLBDDM approach is listed below.
-
The PACHS-DLBDDM technique improves the detection and classification of lung cancer cells (LCC) by incorporating advanced models, resulting in precise and effectual disease detection. It optimizes detecting and classifying cancerous cells, paving the way to more reliable diagnoses. This methodology enhances the precision and efficiency of lung cancer detection.
-
The GF approach implements the PACHS-DLBDDM approach for robust image preprocessing, substantially enhancing data quality and relevance before evaluation. This phase improves the accuracy of subsequent processing phases. Refining the input images confirms more reliable and precise outcomes in subsequent evaluation.
-
phases.
-
Utilizing the Faster SqueezeNet technique for producing feature vectors improves the approach’s capability for extracting and depicting crucial behaviours of cancer cells. This method enhances the accuracy of the feature extraction procedure, paving the way to more precise and informative representations of the data.
-
By incorporating CNN-LSTM for classification and CTSA for hyperparameter tuning, the technique optimizes the accuracy of classifying lung cancer cells and the effectiveness of parameter adjustment. This integrated model improves the overall performance and precision of the predictive model.
-
The PACHS-DLBDDM model incorporates GF, Faster SqueezeNet, CNN-LSTM, and CTSA methods into a unified framework, which enhances the accuracy and effectualness of cancer cell classification. By incorporating these advanced methods, it presents an overall model for preprocessing, feature extraction, and hyperparameter optimization. This innovative incorporation improves both the efficiency and precision of cancer cell evaluation.
Review of literature
Seth and Kaushik11 proposed a technique for identifying LCC with the DL method. The presented method contains three stages. In the first stage, HIs are gathered and preprocessed. For preprocessing, it is essential to utilize an MF. The swim transformers are employed to segment the data. These segment portions are provided in the enhanced cascade CNN (EC2N2) methodology to categorize the image as tumorous or normal. The hyperparameter was optimally chosen using the Adaptive Tasmanian Devil Optimizer (ATDO) technique. In12, DL methods implement, evaluate, and design a diagnostic aid system for non-small cell lung cancer recognition. The classification development is based on AI methods, getting automated classifier outcomes among squamous cell carcinoma adenocarcinoma, and healthy these are delivered as HIs from lung tissue. Additionally, a report method based on Understandable DL methods provides the pathologist data regarding the image areas employed to identify the model. Xiao et al.13 introduced a predictive method utilizing morphologic features of cells in the cancer spot. The feature is extracted initially by the software CellProfiler from the cancer area by selecting the Eff-Unet DL method. Features of various regions are average for every patient as their representation, and the Lasso-Cox method is employed to choose the prognosis-related feature. The prognostic forecast method was finally built by the selected prognosis-related feature and is estimated using cross-validation and KM estimates. Hu et al.14 presented a multilevel threshold image segmentation (MIS) technique based on an improved particle swarm method for splitting COAD imageries. First, this presents a multi-strategy hybrid PSO (DRPSO) by replacement method. The population reorganization framework incorporates MGO to improve people’s diversity and efficiently prevent the method from stagnating prematurely. Next, by uniting the 2D Renyi entropy and non-local mean 2D histogram, this article presents a DRPSO method-based MIS technique that is effectively applied to the sections of the COAD pathology image issue.
Stephen and Sain15 introduced a neural structural search method. This technique utilizes a Bayesian CNN structural search method with Gaussian methods to offer an effective neural network structure for effective lung and colon tumour recognition and classification. The presented method learns through the Gaussian methods to evaluate the essential optimum structural value by selecting a group of parameters over the development of the expected improvement (EI) rates. In16, the authors aim to use a CAD technique to identify histopathological pictures of lung tissues. For the validation and creation of CAD, the method utilized a publicly accessible database. Multilevel processing is used to mine image features. Last, the comparative survey was created based on seven pre-trained CNN methods for identifying lung tumours. Mohamed et al.17 proposed an advanced technique that leverages AI, especially CNN and Fishier Mantis Optimization. The deployment of DL methods, especially CNN, allows the mining of complex features from medicinal imaging data, offering an efficient and robust analytic method. Moreover, the Fishier Mantis Optimization, a bio-inspired optimizer method encouraged by the searching performance of mantis shrimp, has been used to modify the parameters of the CNN, improving its performance and merging speed. Several CNN designs, like RESNET50 and GoogLeNet, are also used.
Jaisakthi et al.18 introduced a DL-based pipeline for multi-class classifications of lung cancer type. The Pseg pipeline was developed to mine the nuclear region with the WSHI patch by an Xception-style UNet-based NN, and these divided areas are classified into cancer types utilizing the similar downstream DCNN structure. Ahamed et al.19 propose a model to anticipate cardiovascular diseases at an early stage utilizing ML approaches and cloud-based storage, focusing on incorporating IoT for real-time prediction through medical sensors. Ahamed, Mir, and Chishti20 develop a prediction model by employing ML methods comprising decision tree (DT), random forest (RF), k-nearest neighbours (kNN), support vector machine (SVM), logistic regression (LR), AdaBoost, and gradient boosting (GB)—improved by hyperparameter optimization and ensemble techniques for enhanced accuracy and mitigated overfitting and underfitting. Mathivanan et al.21 propose an ensemble DL technique by integrating LSTM and CNN models for remote patient monitoring (RPM) in IoT applications, concentrating on early health issue diagnosis and precise real-time data analysis with wearable devices. Shafqat et al.22 introduce a Louvain Mani-Hierarchical Fold Learning healthcare analytics, a hybrid DL method. Ankolekar et al.23 introduce a technique by implementing AI and predictive modelling to improve Learning Health Systems (LHS) by utilizing knowledge, data, and practice. Motwani, Shukla, and Pawar24 propose the Smart Patient Monitoring and Recommendation (SPMR) framework, which utilizes DL and cloud-based analytics for real-time health monitoring and prediction. Kaliappan et al.25 present the HybridNet-NDM methodology to advance neurodegenerative disease prediction and management by incorporating CNNs, LSTMs, and GCNs techniques for detailed evaluation of medical imaging improved by an attention mechanism for enhanced accuracy.
The existing studies encounter several limitations, such as difficulty with computational intensity and real-time implementation due to convolutional hyperparameter tuning and network models. Variability in cancer images and the reliability of feature extraction quality can affect performance. Multilevel image segmentation models may face high computational costs and issues with noisy data. Network structures might only sometimes be optimum, and feature extraction accuracy can be challenging despite utilizing pre-trained techniques. Some methodologies may need to be more effective with smaller datasets or lower-quality images. Sensor inaccuracies in IoT-based techniques can affect data integration issues and real-time prediction accuracy. Managing real-time data processing and incorporating diverse ML approaches can pave the way to an enhanced computational overhead. Practical implementation and scalability threats are also common, impacting adaptability to various patient conditions and large-scale applications. Present cancer detection and patient monitoring techniques often encounter difficulties associated with computational effectualness, real-time data integration, and adaptability to diverse and noisy data. More robust models that balance accuracy with scalability and real-time performance are needed, specifically in handling large-scale and heterogeneous datasets.
Methodology
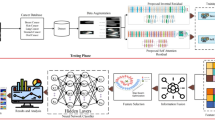
This article introduces the PACHS-DLBDDM methodology. The proposed methodology focuses mainly on the recognition and classification of LCC. It comprises GF, Faster SqueezeNet, CNN-LSTM, and CTSA techniques for preprocessing, feature vector generation, classification, and hyperparameter tuning processes. Figure 1 depicts the entire flow of the PACHS-DLBDDM technique.

Overall flow of PACHS-DLBDDM methodology.
Image preprocessing
At the primary stage, the PACHS-DLBDDM technique employs GF to preprocess the input images26. The GF model is utilized for its efficiency in capturing texture and spatial frequency data, which is significant for evaluating medical images where subtle patterns are crucial. GF method outperforms edge detection and texture characterization, allowing it to accentuate significant features in complex images like those employed for cancer detection. Its capability to filter images with several orientations and scales makes it proficient in discriminating between fine details and noise. This capability safeguards robust preprocessing, improving the accuracy of subsequent feature extraction and classification steps. Furthermore, GF’s well-established mathematical foundation and ease of implementation contribute to its dependable performance across diverse imaging modalities. Figure 2 demonstrates the structure of the GF model.

Overall structure of GF technique.
GF is a popular image preprocessing method applied in medical imaging for LCC recognition. It includes applications of GF to emphasize specific characteristics in medical images, including edge and texture information. GF improves the visibility of tumour structure by filtering images at varying orientations and scales, making detecting malignant areas simple. This technique optimizes the performance of succeeding image analysis and classification methods. The ability of GF to highlight pertinent features assists in earlier detection and treatment planning for LCC patients.
Faster SqueezeNet model
Next, the PACHS-DLBDDM approach employs the Faster SqueezeNet to generate feature vectors27. Faster SqueezeNet is selected for feature vector generation due to its efficient balance between model size and performance. Its compact architecture safeguards fast processing and low computational cost, making it ideal for real-time applications with substantial rapid feature extraction. Despite its small size, SqueezeNet maintains high accuracy in capturing relevant features, which is crucial for precise classification and evaluation. The reduced memory footprint of the technique allows for deployment on devices with limited resources, improving its practical usability. Furthermore, Faster SqueezeNet’s pre-trained models present robust feature extraction capabilities, utilizing extensive training on large datasets to enhance generalization across diverse tasks.
The SqueezeNet architecture was introduced, which has fewer parameters while retaining the performance since AlexNet and VGGNet parameters are ever-increasing. The primary foundation in SqueezeNet is the Fire model. This is broken down into Squeeze and Expand models. Squeeze comprises \(\:S1\)×\(\:1\) convolutional kernels. The Expand layer has \(\:1\)x\(\:1\) and \(\:3\)x\(\:3\) convolutional layers. \(\:{E}_{1\times\:1}\) and \(\:{E}_{3\times\:3}\) are the number of \(\:1\)×\(\:1\) and the count of \(\:3\)×\(\:3\) convolutional layers\(\:.\) This method should satisfy \(\:S<\left({E}_{1\times\:1}+{E}_{3\times\:3}\right)\).
The \(\:\text{M}\text{i}\text{n}\) uses an MLP rather than the linear convolutional layer to improve the network performance. The MLP corresponds to the cascaded cross-channel parametric pooling layer, accomplishing an information integration and linear combination of feature maps.
Once the input and output channels are larger, the convolution layer develops superiorly. A \(\:1\)x\(\:1\) convolutional layer has been added to the inception module, reducing the number of input channels and decreasing the operation complexity and convolution layer. Finally, a \(\:1\)x\(\:1\) convolutional layer is added to enhance feature extraction and increase the number of channels.
SqueezeNet is used to replace \(\:3\)×\(\:3\) with \(\:1\)×\(\:1\) convolutional kernels to reduce the parameter. Once the sampling reduction function is delayed, the convolutional is given a large activation graph; however, the large activation preserves further details, providing a high classifier performance.
Fast SqueezeNet is introduced to improve performance. Residual and BatchNorm designs are included to avoid overfitting. It is the same as DenseNet.
Faster SqueezeNet includes four convolution layers, a global pooling layer, 1 BatchNorm layer, and three block layers.
Fast SqueezeNet is given as follows:
-
(1)
It is derived from the DenseNet architecture, and a connection method has been developed to improve data flow between layers. This includes a pooling layer and a fire module. Lastly, the two concat layers are linked to the next convolution layer. The current layer obtains the mapping feature of the previous layer and applies \(\:{x}_{0},\dots\:,{\:and\:x}_{l-1}\) as input.
In Eq. (1), \(\:[{x}_{0},\:{x}_{1},\:\dots\:,\:{x}_{l-1}]\) denotes the feature map connection at \(\:\text{0,1},\dots\:,l-1\) and \(\:{H}_{l}\) concatenate various inputs. \(\:{x}_{0}\) is the \(\:\text{m}\text{a}\text{x}\)-pooling layer, \(\:{x}_{1}\) is the Fire layer, and \(\:{x}_{l}\) denotes the concat layer.
-
(2)
It is learned from the ResNet design, which includes a fire module and pooling layer to ensure better convergence. Finally, it is connected to the next layer after the two layers are summed.
In ResNet, the shortcut connection applies an identity map directly, signifying that the convolution input has been added straightaway to the output. \(\:H\left(x\right)\) denotes the desired underlying mapping. A stacked non-linear layer fits an alternative mapping of \(\:F\left(x\right):=H\left(x\right)-x.\) A novel mapping is changed into \(\:F\left(x\right)+x.\) The shortcut connection skips multiple layers. As a result, the ResNet model is used to resolve the degradation and vanishing gradient problems without increasing the network parameter.
Classification method using CNN-LSTM
During this stage, the CNN-LSTM approach has been used for LCC classification28. Assuming the spatial feature extractor benefits of the convolution (Conv) layer of CNN and the time-based forming benefits of the LSTM method, this research develops CNN-LSTM that can depict the local feature and retain the long-term dependencies. The CNN-LSTM technique is selected for LCC classification due to its prevailing integration of spatial and temporal feature extraction abilities. The CNN technique outperforms in precisely detecting spatial patterns and textures within images, making them appropriate for extracting detailed features from lung cancer cell images. By incorporating the LSTM networks, which are proficient at capturing temporal dependencies and sequential patterns, the technique can efficiently manage and analyze time-series data or sequential image features, enhancing the accuracy of the classification. This hybrid technique employs the proficiency of the CNN model in feature extraction and the strength of LSTM in sequence learning, giving an overall examination of the cancer cells. It improves the capability of the technique to detect complex patterns and discrepancies over time, paving the way to more precise and reliable LCC classification.
On input to the CNN-LSTM method, which consecutively crosses over Conv block1 and Conv block2, it results in output sizes of \(\:(64,\:26,\:26)\) for Conv block1 and \(\:(128,\:13,\:13)\:\)for Conv block2. Every Conv block has a batch normalization (BN) layer, a Conv layer, ReLU, a dropout layer, and a pooling layer. The BN layer hastens the training and recovers the generality capability of the method. The ReLU relates non-linearity and sparsity to configuration and averts the gradient from vanishing. The ReLU activation function calculation is as follows:
The pooling layer used the largest size of \(\:2\text{x}2\), efficiently decreasing the parameter of model and memory desires; the dropout layer with a definite prospect throughout the system training procedure improves the model’s generality skill. Subsequently, the related features removed by CNN are served into the dual-layer LSTM model to get every time-based feature. The 1st layer LSTM contains 100 HLs, and the 2nd layer LSTM contains 50 HLs. The three gates are accessible in every LSTM framework, with forget, input, and output gates. Figure 3 illustrates the structure of CNN-LSTM.

Architecture of CNN-LSTM.
The LSTM defends and handles the cell state over three gates, recognizing the forgetting, long-term remembering, and state upgrading. The interior processing of LSTM has been calculated as below:
Whereas \(\:{f}_{t},{\:i}_{t}\), and \(\:{\text{o}}_{t}\) signify the gates of forgetting, input and output, correspondingly; \(\:{c}_{t}\) refers to the internal state, which removed from \(\:0\sim\:t\) time denotes the transporter of long-term memory; \(\:{b}_{f},{\:b}_{i},{\:b}_{\text{o}}\), and \(\:{b}_{C}\) denotes the biases; \(\:{h}_{t}\) signifies the long and short-term memory output at the moment \(\:t\); \(\:\left[{W}_{fx},{\:W}_{fh}\right],\left[{\:W}_{ix},{\:W}_{ih}\right],\left[{\:W}_{ox},\:{W}_{oh}\right]\), and \(\:\left[{W}_{\stackrel{\sim}{c}x},\:{W}_{\stackrel{\sim}{c}h}\right]\) represents the weights of forget, input, output gates, and the unitary input, correspondingly; and \(\:\sigma\:\) indicates an activation function of sigmoid.
Fine-tuning the DL model
As a final point, the CTSA approach is performed to enhance the hyperparameter value of the CNN-LSTM model. TSA denotes a novel meta-heuristic technique stimulated by swarm intelligence (SI)29. The CTSA is selected for its greater performance in hyperparameter tuning and optimization due to its capability to escape local optima and explore the solution space more thoroughly. Unlike conventional techniques, the CTSA model utilizes chaotic sequences to improve randomness and avoid premature convergence, which is significant for complex models with high-dimensional parameter spaces. This paves the way for more precise parameter settings and enhanced model performance. Furthermore, CTSA’s integration of swarm intelligence and chaotic behaviour results in improved convergence rates and robustness compared to other optimization methods, making it highly efficient for fine-tuning the classification procedure in cancer detection systems. Its adaptability and efficiency are crucial in optimizing complex techniques and attaining high classification accuracy.
Tunicate is a horde that mainly hunts for its food resources in the ocean. SI and Jet propulsion are the dual dissimilar conducts of tunicate. The 3 phases of the jet propulsion performance are described below. At first, they evade crashes among the hunting agents. Then, they travel to the optimal search agent location. At last, they stay nearer to the optimal searching agent. It upgrades the other searching agents to a superior solution.
The \(\:\overrightarrow{A}\) vector is employed to compute the upgraded position of searching agents to avoid crashes among search agents:
Here, the water movement advection is denoted by \(\:\:\overrightarrow{F}\), and \(\:\overrightarrow{G}\) represents the gravity force. \(\:{c}_{1},{c}_{2}\) and \(\:{c}_{3}\) signify the variables within the range of \(\:\left[\text{0,1}\right].\)\(\:\overrightarrow{M}\) indicates the social force among the search agents as given below:
\(\:{P}_{\text{m}\text{a}\text{x}}\) and \(\:{P}_{\text{m}\text{i}\text{n}}\) represent the first and second velocities for creating social communication, respectively. The \(\:1\) and \(\:4\) are fixed values. Figure 4 depicts the architecture of the CTSA model.

Architecture of CTSA model.
The searching agent moves to the finest neighbour way after avoiding the crash among adjoining locals. The mathematical calculation of this method is given below:
Where\(\:\:\overrightarrow{P}D\) indicates the distance between the source of food and the search agent, viz., tunicate, \(\:F\overrightarrow{S}\) epitomizes the position of the food source. \(\:{\overrightarrow{X}}_{i}\left(t\right)\) signifies the position of the tunicate, and \(\:rand\) denotes the random integer in the range of [0 and 1].
The agents uphold the position near the optimal searching agents is stated as below:
In Eq. (14), \(\:\overrightarrow{X}\left(t\right)\) displays the tunicate position after upgrading \(\:the\:F\overrightarrow{S}\) position. The initial dual optimal solutions are kept and upgraded with other searching agents depending upon the optimal searching agent’s place to demonstrate the tunicate’s group behaviours arithmetically.
Initialization of population is crucial in meta-heuristic techniques since the excellence of solution and velocity of convergence are influenced by it. So, the initialization of the population is produced at random because there is no preceding knowledge accessible for the solution, and it is frequently used in meta-heuristic techniques. Likewise, TSA exploits the early arbitrary population of \(\:X\) utilizing normal distribution as set below:
In Eq. (16), \(\:{x}_{ij}\left(t\right)\) denotes the \(\:jth\) module of\(\:\:ith\) individual solution at \(\:th\) iteration\(\:.\) The search region’s upper and lower limits are \(\:{x}_{\:\text{m}\text{a}\text{x}}\) and \(\:{x}_{m\dot{m}},\:\)respectively. \(\:r\) signifies the random value in the range of [\(\:\text{0,1}\)].
If the initialization of the population is nearer to the global targets, the rate of convergence turns fast, and it can achieve improved solutions; however, the early population is less frequently the finest randomly. The chaotic-based method enhances efficiency and improves the variety of the population.
In Eq. (17), \(\:c{h}_{ij}\) denotes the value of chaotic that is formed by the logistic chaotic mapping:
The OBL technique computes the reverse solution \(\check{X}\) of \(\:{X}_{i}\). The \(\:n\) best solutions were selected from \(\:[X,\:x]\) as per the fitness value. Eventually, the technique drives to the phase of jumping.
The CTSA model develops an FF to improve the classifier’s effectiveness. It designates an optimistic numeral to signify the candidate solution’s amended performance. In this paper, the reduction of the classifier’s rate of error is measured as FF, which is shown in Eq. (19).
Experimental analysis and results
In this section, the experimental validation results of the PACHS-DLBDDM model are examined utilizing the LC25000 dataset30. The dataset covers 25,000 samples with five classes, as delivered in Table 1. Figure 5 establishes the sample imageries of lung and colon cancers.

Sample Images of (a) Lung cancer and (b) Colon cancer.
Figure 6 establishes the confusion matrices formed by the PACHS-DLBDDM technique under 80:20 and 70:30 of TRAP/TESP. The results indicate that the PACHS-DLBDDM approach efficiently detects and precisely identifies all five class labels.

Confusion matrices of PACHS-DLBDDM technique (a,b) 80%TRAP and 20%TESP and (c,d) 70%TRAP and 30%TESP.
Table 2; Fig. 7 indicate the overall cancer detection results of the PACHS-DLBDDM technique under 80%TRAP and 20%TESP. The results inferred that the PACHS-DLBDDM technique properly recognized five different classes. With 80% TRAP, the PACHS-DLBDDM model delivers an average \(\:acc{u}_{y},\) \(\:pre{c}_{n},\) \(\:rec{a}_{l},\) \(\:{F}_{score},\) and \(\:AU{C}_{score}\) of 99.40%, 98.50%, 98.50%, 98.50%, and 99.06%, correspondingly. Also, with 20% TESP, the PACHS-DLBDDM approach delivers average \(\:acc{u}_{y},\) \(\:pre{c}_{n},\) \(\:rec{a}_{l},\) \(\:{F}_{score},\) and \(\:AU{C}_{score}\) of 99.54%, 98.84%, 98.85%, 98.85%, and 99.28%, correspondingly.

Average of PACHS-DLBDDM technique under 80%TRAP and 20%TESP.
Figure 8 demonstrates the training and validation accuracy outcomes of the PACHS-DLBDDM method under 80%TRAP and 20%TESP. The accuracy values are calculated over a range of 0–25 epochs. The outcome highlighted that the training and validation accuracy values have a rising tendency, which advises the aptitude of the PACHS-DLBDDM technique with enhanced performance over many iterations. Also, the training and validation accuracy remains nearer over the epochs, which specifies low least overfitting and shows improved performance of the PACHS-DLBDDM technique, guaranteeing consistent forecasts on hidden samples.

\(\:Acc{u}_{y}\) curve of PACHS-DLBDDM technique under 80%TRAP and 20%TESP
Figure 9 displays the training and validation loss graph of the PACHS-DLBDDM methodology under 80%TRAP and 20%TESP. The loss values are computed over a range of 0–25 epochs. The training and validation accuracy values demonstrate a declining tendency, notifying the PACHS-DLBDDM methodology’s ability to balance a trade-off between data fitting and generalization. The frequent reduction in loss values also guarantees the boosted performance of the PACHS-DLBDDM approach and tunes the prediction outcomes over time.

Loss curve of PACHS-DLBDDM technique under 80%TRAP and 20%TESP.
In Fig. 10, the precision-recall (PR) curve analysis of the PACHS-DLBDDM method under 80%TRAP and 20%TESP provides interpretation into its performance by plotting Precision against Recall for every class. The figure displays that the PACHS-DLBDDM method continuously completes upgraded PR values across dissimilar class labels, demonstrating its ability to uphold a significant part of true positive predictions between every positive prediction (precision) while taking a large ratio of actual positives (recall). The secure rise in PR outcomes between every class depicts the efficiency of the PACHS-DLBDDM approach in the classification procedure.
In Fig. 11, the ROC curve of the PACHS-DLBDDM approach under 80%TRAP and 20%TESP is studied. The results indicate that the PACHS-DLBDDM approach attains higher ROC results over each class, representing a significant skill in discerning the classes. This reliable trend of amended ROC values over numerous classes indicates the proficient performance of the PACHS-DLBDDM method in predicting classes, highlighting the strong nature of the classification method.

PR curve PACHS-DLBDDM technique under 80%TRAP and 20%TESP.

ROC curve of PACHS-DLBDDM technique under 80%TRAP and 20%TESP.
Table 3; Fig. 12 indicate the overall cancer recognition results of the PACHS-DLBDDM technique under 70%TRAP and 30%TESP. The results inferred that the PACHS-DLBDDM technique properly recognized five different classes. With 70%TRAP, the PACHS-DLBDDM model delivers an average \(\:acc{u}_{y}\), \(\:pre{c}_{n}\), \(\:rec{a}_{l}\), \(\:{F}_{score}\), and \(\:AU{C}_{score}\) of 99.20%, 98.01%, 98.01%, 98.01%, and 98.76%, correspondingly. Also, with 30% TESP, the PACHS-DLBDDM model delivers average \(\:acc{u}_{y}\), \(\:pre{c}_{n}\), \(\:rec{a}_{l}\), \(\:{F}_{score}\), and \(\:AU{C}_{score}\) of 99.26%, 98.15%, 98.14%, 98.14%, and 98.84%, correspondingly.

Average of PACHS-DLBDDM technique under 70%TRAP and 30% TESP.
Figure 13 demonstrates the training and validation accuracy results of the PACHS-DLBDDM model under 70%TRAP and 30%TESP. The accuracy values are computed throughout 0–25 epochs. The outcome highlighted that the training and validation accuracy values display a rising trend, which informed the skill of the PACHS-DLBDDM model and improved performance over several iterations. Moreover, the training and validation accuracy stays closer over the epochs, which specifies low minimum overfitting and reveals the superior performance of the PACHS-DLBDDM technique, guaranteeing steady prediction on unseen samples.
Figure 14 presents the training and validation loss graph of the PACHS-DLBDDM methodology under 70%TRAP and 30%TESP. The loss values are calculated throughout 0–25 epochs. The training and validation accuracy values demonstrate a reducing tendency, notifying the PACHS-DLBDDM methodology’s ability to balance a trade-off between data fitting and generalization. The continual reduction in loss values assures the PACHS-DLBDDM technique’s higher performance and tunes the prediction outcomes over time.

\(\:Acc{u}_{y}\) curve of PACHS-DLBDDM technique under 70%TRAP and 30%TESP

Loss curve of PACHS-DLBDDM method under 70%TRAP and 30%TESP.
In Fig. 15, the PR curve analysis of the PACHS-DLBDDM approach under 70%TRAP and 30%TESP interprets its performance by plotting Precision against Recall for every class. The outcome displays that the PACHS-DLBDDM approach continuously accomplishes enhanced PR values across diverse classes, representing its ability to preserve a significant part of true positive predictions among every positive prediction (precision) while capturing a huge amount of actual positives (recall). The stable rise in PR results among all classes depicts the efficiency of the PACHS-DLBDDM technique in the classification manner.
In Fig. 16, the ROC curve of the PACHS-DLBDDM approach under 70%TRAP and 30%TESP is studied. The results imply that the PACHS-DLBDDM approach reaches enhanced ROC outcomes over every class, demonstrating its significant capability of discriminating classes. This reliable trend of improved ROC values over numerous classes indicates the proficient performance of the PACHS-DLBDDM method in forecasting classes, highlighting its robust nature under the classification model.

PR curve PACHS-DLBDDM technique under 70%TRAP and 30%TESP.

ROC curve of PACHS-DLBDDM technique under 70%TRAP and 30%TESP.
To demonstrate the proficiency of the PACHS-DLBDDM method, a detailed comparison study of the PACHS-DLBDDM technique with present methods is made in Table 4; Fig. 1731. The outcomes specify that the m-SRC model has shown ineffective performance. The RESNET50, CNN, and DAEL-GNN models have also exhibited slightly boosted results. Meanwhile, the Faster RCNN, MPA-DLLC3, and BERTLHI-ALCC methods have demonstrated moderately closer results. However, the PACHS-DLBDDM approach outperforms the other methodologies with an increased \(\:acc{u}_{y}\) of 99.54%, \(\:pre{c}_{n}\) of 98.84%, \(\:rec{a}_{l}\) of 98.85%, and \(\:{F}_{score}\) of 98.85%.

Comparative outcome of PACHS-DLBDDM technique with other models.
Figure 18 depicts a comparison computation time (CT) study of the PACHS-DLBDDM method with present methods. The outcomes showed that the PACHS-DLBDDM technique attains a minimal CT of 35s. On the other hand, the BERTLHI-ALCC, MPA-DLLC3, m-SRC, Faster RCNN, DAEL-GNN, RESNET50, and CNN models obtain increased CT values of 45s, 55s, 65s, 60s, 57s, 62s, and 55s, correspondingly. Thus, the PACHS-DLBDDM technique can be employed to identify LCC.

CT outcome of PACHS-DLBDDM technique with existing models.
Conclusion
In this work, the PACHS-DLBDDM approach is proposed. The projected PACHS-DLBDDM approach mainly focuses on the identification of LCC. At the primary stage, the PACHS-DLBDDM technique applies GF to preprocess the input images. Next, the PACHS-DLBDDM technique utilizes the Faster SqueezeNet to generate a feature vector. In addition, the CNN-LSTM approach is employed for LCC classification. The CTSA approach was executed to optimize the hyperparameter value of the CNN-LSTM approach so that the classifier outcomes could be improved. The experimentation outcome analysis of the PACHS-DLBDDM approach is verified on a medical imaging dataset. The performance validation of the PACHS-DLBDDM model portrays the superior accuracy value of 99.54% over other DL models. The PACHS-DLBDDM model, while efficiently detecting and classifying LCC using GF, Faster SqueezeNet, CNN-LSTM, and CTSA methods, encounters limitations in handling highly variable or noisy data and may need help with real-time processing. Furthermore, the performance of the model could be affected by the quality and diversity of input data. Future studies should improve the technique’s robustness to diverse data sources, enhance real-time processing capabilities, and incorporate more advanced models for dynamic adaptation and scalability to confirm broader applicability and efficiency. Future work should also explore the incorporation of transfer learning and domain adaptation models to improve the performance of the approach across diverse datasets and conditions, enabling more precise classification and detection of LCC in various clinical scenarios.
Data availability
The datasets used and analyzed during the current study available from the corresponding author on reasonable request.
Change history
17 December 2024
A Correction to this paper has been published: https://doi.org/10.1038/s41598-024-82835-4
References
Kumar, N., Sharma, M., Singh, V. P., Madan, C. & Mehandia, S. An empirical study of handcrafted and dense feature extraction techniques for lung and colon cancer classification from histopathological images. Biomed. Signal. Process. Control 75, 103596 (2022).
Ding, K. et al. Feature-enhanced graph networks for genetic mutational prediction using histopathological images in colon cancer. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2020: 23rd International Conference, Lima, Peru, 4–8 October 294–304 (Springer International Publishing, 2020).
Mangal, S., Chaurasia, A. & Khajanchi, A. Convolution neural networks for diagnosing colon and lung cancer histopathological images. arXiv. arXiv:2009.03878 (2020).
Tummala, S., Kadry, S., Nadeem, A., Rauf, H. T. & Gul, N. An explainable classification method based on Complex Scaling in Histopathology images for lung and Colon cancer. Diagnostics 13, 1594 (2023).
Ali, M. & Ali, R. Multi-input dual-stream capsule network for improved lung and colon cancer classification. Diagnostics 11, 1485 (2021).
Dabass, M., Vashisth, S. & Vig, R. A convolution neural network with multilevel convolutional and attention learning for classification of cancer grades and tissue structures in colon histopathological images. Comput. Biol. Med. 147, 105680 (2022).
Kassani, S. H., Kassani, P. H., Wesolowski, M. J., Schneider, K. A. & Deters, R. Deep transfer learning based model for colorectal cancer histopathology segmentation: A comparative study of deep pre-trained models. Int. J. Med. Inf. 159, 104669 (2022).
Naga Raju, M. S. & Srinivasa Rao, B. Lung, and colon cancer classification using hybrid principle component analysis network extreme learning machine. Concurr Comput. Pract. Exp. 35, e7361. (2023).
Talukder, M. A. et al. Machine learning-based lung and colon cancer detection using deep feature extraction and ensemble learning. Expert Syst. Appl. 205, 117695 (2022).
Hamida, A. B. et al. Deep learning for colon cancer histopathological images analysis. Comput. Biol. Med. 136, 104730 (2021).
Seth, A. & Kaushik, V. D. Automatic lung and colon cancer detection using enhanced cascade convolution neural network. Multimed.Tools Appl. 1–22 (2024).
Civit-Masot, J. et al. Non-small cell lung cancer diagnosis aid with histopathological images using Explainable Deep Learning techniques. Comput. Methods Progr. Biomed. 226, 107108 (2022).
Xiao, X., Wang, Z., Kong, Y. & Lu, H. Deep learning-based morphological feature analysis and the prognostic association study in colon adenocarcinoma histopathological images. Front. Oncol. 13, 1081529 (2023).
Hu, G., Zheng, Y., Houssein, E. H. & Wei, G. DRPSO: A multi-strategy fusion particle swarm optimization algorithm with a replacement mechanisms for colon cancer pathology image segmentation. Comput. Biol. Med. 178, 108780 (2024).
Stephen, O. & Sain, M. Using deep learning with bayesian–Gaussian inspired convolutional neural architectural search for cancer recognition and classification from histopathological image frames. J. Healthc. Eng. 2023(1), 4597445 (2023).
Shandilya, S. & Nayak, S. R. Analysis of lung cancer by using deep neural network. In Innovation in Electrical Power Engineering, Communication, and Computing Technology: Proceedings of Second IEPCCT 2021 427–436 (Springer Singapore, 2022).
Mohamed, A. A. A., Hançerlioğullari, A., Rahebi, J., Rezaeizadeh, R. & Lopez-Guede, J. M. Colon cancer disease diagnosis based on convolutional neural network and fishier mantis optimizer. Diagnostics 14(13), 1417 (2024).
Jaisakthi, S. M., Desingu, K., Mirunalini, P., Pavya, S. & Priyadharshini, N. A deep learning approach for nucleus segmentation and tumor classification from lung histopathological images. Netw. Model. Anal. Health Inform. Bioinform. 12(1), 22 (2023).
Ahamed, J., Manan Koli, A., Ahmad, K., Jamal, A. & Gupta, B. B. CDPS-IoT: cardiovascular disease prediction system based on IoT using machine learning (2022).
Ahamed, J., Mir, R. N. & Chishti, M. A. Industry 4.0 oriented predictive analytics of cardiovascular diseases using machine learning, hyperparameter tuning and ensemble techniques. Ind. Robot.: Int. J. Rob. Res. Appl. 49(3), 544–554 (2022).
Mathivanan, S. K., Shivahare, B. D., Chandan, R. R. & Shah, M. A. A comprehensive health assessment approach using ensemble deep learning model for remote patient monitoring with IoT. Sci. Rep. 14(1), 15661 (2024).
Shafqat, S. et al. Leveraging deep learning for designing healthcare analytics heuristic for diagnostics. Neural Process. Lett. 1–27 (2023).
Ankolekar, A. et al. Using artificial intelligence and predictive modelling to enable learning healthcare systems (LHS) for pandemic preparedness. Comput. Struct. Biotechnol. J. (2024).
Motwani, A., Shukla, P. K. & Pawar, M. Novel framework based on deep learning and cloud analytics for smart patient monitoring and recommendation (SPMR). J. Ambient Intell. Humaniz. Comput. 14(5), 5565–5580 (2023).
Kaliappan, S., Kamal, M. R., Balaji, V. & Kumar, G. R. January. Advanced neural network models for predictive analytics and healthcare management in neurodegenerative diseases. In 2024 International Conference on Advancements in Smart, Secure and Intelligent Computing (ASSIC) 1–6 (IEEE, 2024).
Qi, K. & Sun, J. Gabor-filtered fourier neural operator for solving partial differential equations. Comput. Fluids 274, 106239 (2024).
Xu, Y., Yang, G., Luo, J. & He, J. An electronic component recognition algorithm based on deep learning with a faster SqueezeNet. Math. Probl. Eng. 2020(1), 2940286 (2020).
Shen, Z., Liu, X., Li, W., Li, X. & Wang, Q. Classification of visually induced motion sickness based on phase-locked value functional connectivity matrix and CNN-LSTM. Sensors 24(12), 3936 (2024).
Si, T. et al. Opposition-based chaotic tunicate swarm algorithms for global optimization. IEEE Access (2024).
https://www.kaggle.com/datasets/andrewmvd/lungand-colon-cancerhistopathological-images.
AlGhamdi, R., Asar, T. O., Assiri, F. Y., Mansouri, R. A. & Ragab, M. Al-biruni Earth radius optimization with transfer learning based histopathological image analysis for lung and colon cancer detection. Cancers 15(13), 3300 (2023).
Acknowledgments
The authors extend their appreciation to the Deanship of Research and Graduate Studies at King Khalid University for funding this work through Large Research Project under grant number RGP2/32/45. Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2024R510), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Author information
Authors and Affiliations
Contributions
Conceptualization: Muhammad Kashif SaeedData curation and Formal analysis: Alanoud Al MazroaInvestigation and Methodology: Muhammad Kashif SaeedProject administration and Resources: Supervision; Bandar M. AlghamdiValidation and Visualization: Fouad Shoie Alallah, Abdulrhman AlshareefWriting—original draft, Muhammad Kashif SaeedWriting—review and editing, Ahmed MahmudAll authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this Article was revised: The original version of this Article contained an error in the Acknowledgements section. Full information regarding the correction made can be found in the correction for this article.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Saeed, M.K., Al Mazroa, A., Alghamdi, B.M. et al. Predictive analytics of complex healthcare systems using deep learning based disease diagnosis model. Sci Rep 14, 27497 (2024). https://doi.org/10.1038/s41598-024-78015-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-78015-z
