
Abstract
A medication error is an inadvertent failure in the drug therapy process that can cause serious harm to patients by increasing morbidity and mortality and are associated with significant economic costs to the healthcare system. Medication reconciliation is the most cost-effective intervention and can result in a 66% reduction in medication errors. To improve patient safety, we developed a machine learning-based tool that prioritizes patients at risk of medication errors upon admission to the hospital to ensure that they undergo medication reconciliation by clinical pharmacists. The data were collected from the electronic health records of patients admitted to Reims University Hospital who underwent medication reconciliation between 2017 and 2023. The data from 7200 patients were used to train four machine learning-based models based on 52 variables in the development dataset. These models were used to prioritize admitted patients according to their likelihood of being exposed to a medication error. Our models, particularly the voting classifier model, demonstrated good performance (a recall of 0.75, precision of 0.65, F1 score of 0.70, AUROC of 0.74 and AUCPR of 0.75). In a retrospective evaluation simulating real-life use, the voting classifier model successfully identified 45% of the total patients selected who were found to have at least one unintended discrepancy compared to 21% when using the existing tool. The positive experimental results of this tool showed a superior improvement of 113% over the existing tool by targeting patients at risk of medication errors upon admission to Reims University Hospital.
Similar content being viewed by others
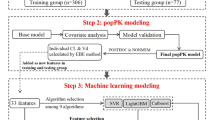

Introduction
A medication error (ME) is an unintentional discrepancy in the medication treatment process. Unintentional discrepancies occur when a prescriber unintentionally changes, adds, or omits a medication that a patient was taking prior to admission to the hospital, resulting in or likely to result in harm to the patient1. Errors in prescribing, dispensing, drug duplication, dosing errors, storing, preparing, and administering medication are the most common preventable causes of unwanted adverse events in the practice of medication. It can occur at any time (most cases occurred on the first day of hospitalization)2. It can occur throughout the patient’s care pathway and can result in a risk or an adverse event for the patient3. However, approximately half of adverse drug events are preventable medication errors4.
There is potential for many medication errors to occur due to the lack of communication between health professionals, insufficient patient information on how to take their medicine, polymedication of the patient and the risk of confusion between his or her different treatments and inadequate information or packaging of the medicine. These MEs can cause an increase in morbidity and mortality, are associated with a significant economic cost and are estimated to cost US$42 billion annually worldwide5. This figure is 0.7% of all global health spending. MEs are the third leading cause of death in the United States and Europe, surpassed only by heart disease and cancer6. Among the various actions taken to prevent the occurrence of these MEs is medication reconciliation (MR). MR refers to the process of avoiding such medication discrepancies across transitions in care (admission, transfer, and discharge) by creating as complete and accurate a list as possible of a patient’s current medications and comparing the list to those in the patient’s record or medication orders7. MR is the most cost-effective intervention8 and can result in a 66% reduction in medication errors9.
Currently, MR is flourishing increasingly in France due to the favorable regulatory environment. In fact, since 2016, a decree has been issued to make clinical pharmacy a compulsory activity for internal use10. In addition, since January 2018, MR has been an indicator of contracts for improving the quality and efficiency of care and has been a binding contract between regional health agencies and health institutions11. Many studies have demonstrated the benefit of MR on patient admission12,13,14. Moreover, in France, MR at patient admission has been developed in many hospitals and, more specifically, in clinical departments such as surgery15,16, geriatrics17,18,19, emergencies20 and internal medicine departments21,22.
At the University Hospital Center (CHU) of Reims, MR is carried out retroactively upon admission to the hospital by 5th -year pharmacy students present in care services. This pharmaceutical activity has been an integral part of their mission since 2014. Students were pretrained on this activity at the College of Pharmacy and were accompanied by a reference pharmacist from the care service. MR is carried out according to a process consisting of 3 stages: actively seeking information on the patient’s healthcare products, carrying out the medication review, and updating the prescription and patient records. However, MR on admission is a time-consuming and expensive process that presents a hospital-wide challenge. MR takes an average of 50 min per patient7, necessitating the deployment of more clinical pharmacists, which many healthcare facilities cannot afford and are unwilling to do. Many previous studies have investigated variables that influence pharmaceutical interventions and can be used as predictors16,23,24. Other studies have discussed developing a score to identify patients at risk of medication errors using a multivariate logistic regression model25,26,27, but to the best of the authors’ knowledge, none have focused on machine learning-based techniques with patients admitted to different hospital wards, making this paper a novel contribution to this field.
At present, at the CHU, no instructions are given to pharmacy students performing MR regarding patient selection. Medication reconciliations are carried out on adult patients admitted to medical, surgical and obstetric wards, as well as in follow-up care and rehabilitation. These procedures were carried out within 72 h of patient admission. Owing to the human resources allocated, it is not possible to carry out MR for all patients admitted to our institution. To increase the efficiency of this activity, we need to be able to identify those patients most at risk of unintentional discrepancies and prioritize the MR of these patients. At the CHU of Reims, we used the software Easily version 7.0.0.13 to computerize the care files for patients. Easily covers a wide range of functionalities, including the visualization of laboratory results, clinical files, care files and prescriptions and the management of medical letters, including digital dictation and the management of appointments. However, at present, no study has identified patients at risk of MEs upon hospitalization at the entire CHU of Reims. Currently, the increase in the number of electronic health records and the development of big data analytics are paving the way for the use of artificial intelligence (AI) and machine learning (ML) techniques to process these data, which makes MR more effective and helps reduce MEs28. Therefore, the aim of this study was to develop a machine learning-based tool to assist clinical pharmacists in selecting patients at high risk of medication errors for medication reconciliation. This approach could improve patient safety, lead to a more efficient process, prevent medication errors, reduce disease complications, and reduce the cost and burden on the healthcare system.
Materials and methods
Data collection
The prediction tool developed in this study was derived based on the data of patients admitted to the CHU (Reims, France). CHU is a 2,382-bed general hospital that receives approximately 93,000 clinical admissions each year and provides both surgical and medical services. In the CHU, all patient files are typically digitized and recorded using Easily software (except for neonatology and intensive care units). Prescription orders and MRs by clinical pharmacists are managed with the same software, which includes all patient details, medical and nursing notes, laboratory results, and vital signs.
Only patients who received MR between 2017 and 2023 were considered. MR consists of a standardized medication interview with the patient conducted by a practitioner (pharmacist or pharmacist-in-training). The data were extracted directly from the Easily software database. In addition, because MR sheets are often poorly linked to the respective hospitalizations in Easily software, relinking was performed using patient identifiers, hospitalization dates, and MR dates (considered reliable information). MRs that could not be associated with hospitalization were excluded. The final cohort was validated in consultation with pharmacists. Throughout this study, all the data were stored on a secure local server, and pseudonymous patient identities were used instead of their names (an identification number for each patient).
Data preprocessing
Data preprocessing is the first step in the ML algorithm and is used to transform the raw data into useful, understandable and efficient formats. Out of 350,540 patients admitted to the hospital between 2017 and 2023, only 12,604 patients were randomly selected for MR, with a total of 52 variables representing each patient’s record.
In this study, the first step in data preprocessing was to improve the data quality, mainly by rectifying outlier values and by filling in possible empty values. To this end, each incorrect or empty numerical value (excluding counters) was filled with the mean of the associated column, while the counter and Boolean values were filled with zeros. In addition, checks on uniqueness (particularly at the level of identifying variables) and correct ordering (particularly at the level of dates, before conversion into numeric variables) were carried out. The second step was data normalization, which was used to adjust the values of variables in the dataset to a common scale. Here, min–max normalization was used where all variable values ranged between [0,1].
The final dataset used included 4361 negative patients and 2839 positive patients. Here, those who were found to have unintended medication discrepancies during medication reconciliation are referred to as positive patients, while those who had no unintended discrepancies are referred to as negative patients. To determine whether handling balanced data contributes to improved performance, training datasets were prepared with/without resampling. The preprocessed dataset was undersampled by the edited nearest neighbor (ENN) method29 and then oversampled by adaptive synthetic sampling (ADASYN)30. The ENN and ADASYN algorithms were applied using the imbalanced-learn library31 in the Python 3.9 language with the default settings.
To develop a comprehensive prediction tool for identifying patients at risk of medication errors, a total of 52 variables (Table 1) were extracted directly or indirectly (by calculation) from the patients’ records. These variables were chosen on the basis of the advice of the pharmacists and according to similar studies on medication reconciliation2,16,22. Table 1 shows the general characteristics of the included patients in this study. It also shows the difference in patient characteristics (regarding the 52 variables) between the positive and negative cohorts (MEs and no-MEs patients). The mean age in the positive and negative cohorts was 73 years. The ratio of men 46.2% and 45.3% was almost equal in the positive and negative cohorts. The same applies to the mean BMI, which was found to be almost equally in both cohorts, 24.8% and 24.2%. The proportion of patients living at home was 74.8% and 83.3% in the positive and negative cohorts compared to 0.2% and 0.4% living in an institution. In Table 1, characteristics were compared between ME and no-ME patients with Student t test for quantitative variables and chi-square test for qualitative variables. The p-value in Table 1 showed whether there was a significant difference between positive and negative cohorts, for each variable. Variables with a p-value < 0.05 can be partially considered more significant than others for the label prediction.
Prediction tool
Four machine learning algorithms—logistic regression (LR), support vector machine (SVM), extreme gradient boosting (XGB), and voting classifier (VC)—were used to develop the prediction models. Python 3.9.6 was used for coding the algorithm, and the scikit-learn library32 was used for all the ML models, except for XGB, for which the xgboost library33 was used. VC is a machine learning model that trains on a set of base models and predicts an output (class) based on hard voting or soft voting criteria. Hard voting aggregates the outputs of each base model and predicts the class label with the highest number of votes, while soft voting aggregates the probabilities of each class label and predicts the class label with the highest average probability. In this study, the SVM, LR, XGB, and random forest models were used as base classifiers for the VC classifier with hard voting criteria. Here, the default settings of the machine learning algorithms were used.
Validation
The proportion of patients with MR data in the database was used as the gold standard, to which the outcomes predicted by the prediction model were compared. To address the problem of overfitting and to determine whether the model is generalizable, internal validation was performed using fivefold stratified cross-validation for each prediction model.
To evaluate model performance, several widely recognized metrics, F1 score, precision, and recall, were selected to measure model performance for predicting patients at risk of medication errors. The F1 score is defined as the harmonic mean of precision and recall. Precision measures the proportion of examples classified as positive that are truly positive, whereas recall measures the proportion of actual positives that are identified correctly. The precision is defined by precision = tp/(tp + fp), and the recall (also known as sensitivity) is defined by recall = tp/(tp + fn), where tp, fp, and fn are the numbers of true positives, false positives, and false negatives, respectively. Further metrics for the statistical performance analysis included the area under the receiver operating characteristic curve (AUROC). The receiver operating characteristic curve describes the trade-off between the true positive rate (TPR), also known as the sensitivity/recall, and the false positive rate (FPR) at various threshold settings. The AUROC is a measure of model performance: the closer the value is to 1, the better the prediction performance. We also used the area under the precision‒recall curve (AUCPR), which provides a more accurate representation of the impact the model can have on the pharmacist’s work34, given that the dataset is imbalanced. The AUCPR describes the trade-off between the positive predictive value (also known as precision) and the TPR at various threshold settings.
Results
Over a period of 7 years, data were collected only for patients who were hospitalized at various hospital departments for at least 24 h. During this period, 12,604 patients were randomly selected to undergo medication reconciliations. Pharmacist intervention was recommended for 2,878 of the 12,604 patients, meaning that 22.8% of patients were at risk of at least one unintended discrepancy.
The results of the different prediction models are shown in Tables 2 and 3, and 4. Table 2 contains the results for the prediction models (LR, SVM, XGB, and VC) based on the original imbalanced dataset. Table 3 contains the corresponding results when the training dataset is resampled (under/oversampled by the ENN and ADASYN), Table 4 contains the corresponding results when the training dataset is resampled (under and oversampled by the ENN and ADASYN) and the validation dataset is undersampled.

Accuracy of the VC model with a balanced training dataset: AUCPR and AUROC.
As with most healthcare datasets, one of the major hurdles when learning from imbalanced data is that the minority class is usually the class of interest. In the training set, having a class with few examples would cause any model to be skewed toward improper classification, as it will not receive enough examples for the class of interest. Therefore, balancing the dataset helps prevent the model from being biased toward the dominant class. Visual inspection of the values in Tables 2, 3 and 4 enables comparisons between the effectiveness of different prediction models. From the analysis of the different metrics used, it can be concluded that resampling the dataset leads to a viable improvement in prediction performance. The results in Tables 3 and 4 show that the prediction models (LR, SVM, XGB, and VC) produced higher recall, precision, F1 score, AUROC, and AUCPR values when the balanced dataset was used than when the imbalanced dataset was used, as shown in Table 2.
Discussion
The main aim of this study was to improve patient safety by developing a tool that prioritizes admitted patients at risk of medication errors to undergo medication reconciliation by clinical pharmacists. To determine the extent to which the objectives underlying this study have been met, first, we will discuss the existing tool used at the CHU of Reims to select patients admitted for medication reconciliation and the extent of its effectiveness. We will later discuss the results obtained using our developed tool and compare them with the existing tool used to determine how efficient our tool is.
At our CHU of Reims, medication reconciliation is performed on a random sample of patients who have been hospitalized for at least 24 h and have had at least one prescription order. Here, we will discuss the results of the existing tool used at our CHU of Reims for selected patients for medication reconciliation in 2022. Out of 47,876 patients admitted to the hospital in 2022, only 2,037 (4.3%) were randomly selected for medication reconciliation. We found that medication reconciliation detected at least one unintended discrepancy in only 26% of the selected patients (536 of 2037 patients), leading to pharmacist intervention. These results can be read from two different points of view. On the one hand, the current procedure has succeeded in intercepting 26% of the positive patients who require pharmaceutical intervention. On the other hand, the presence of 26% of the patients within the selected random sample was considered high, which indicated that a large number of patients were not selected and may need pharmacist intervention. Due to limited resources and capabilities, the number of patients selected for medication reconciliation did not exceed 4.3% of the total patients admitted. Therefore, the presence of 74% of negative cases is considered a waste of the already limited resources that were supposed to be used to examine the files of other patients who may be at risk of medication errors.
The results in Table 2 show that the performance of the ML tools was affected by class imbalance, in which examples in training data belonging to one class greatly outnumber the examples in the other class. Two methods were used to balance the training dataset, allying a known undersampling method (ENN) and the oversampling method (ADASYN), to produce better defined class clusters. Our comparative results in Tables 2 and 3 show that using prediction tools with a balanced dataset provides more accurate results than does using an imbalanced dataset considering the recall metric.
Inspection of the results reported in Tables 2, 3 and 4 enables one to make comparisons between the effectiveness of the various models when used with imbalanced and balanced datasets. However, a more quantitative approach is possible using the Kendall W test of concordance35 to rank the effectiveness of all used models as shown in Table 5. This test was developed to quantify the level of agreement between a set of raters ranking the same set of objects. Here, we used this approach to rank the performance of the proposed models while used with imbalanced and balanced datasets. In the present context, the recall, precision, F1 score, AUROC and AUCPR metrics were used as the raters, and the LR, SVM, XGB and VC models were used as the ranked objects. The results of the Kendall analysis are reported in Table 5 and give the ranking for the various prediction models for each dataset. It is noted that the VC model were ranked first in all datasets. The effectiveness of prediction models is significantly impacted by using balanced datasets instead of imbalanced ones, as shown by the results in Tables 3 and 4. When a balanced training dataset is used (see Table 3), the improvement in the recall rate was 7%, 50%, 15%, and 12% for LR, SVM, XGB, and VC models, respectively, with a slight decrease in precision rate. The same results can be observed when the balanced training and validation dataset is used (see Table 4), but with an improvement in the precision rate of 23%, 12%, 15%, and 18% for the LR, SVM, XGB, and VC models, respectively, compared to the unbalanced dataset. Improvements in recall and precision rates led to improvements in the other related metrics, as demonstrated in Table 4. It is clear from these results (see Tables 3 and 4) that it is advisable to use balanced data to improve the effectiveness of prediction models. In what follows, we will discuss the results of our ML tools and, in particular, the VC model, as it achieved the best results. In what follows, we will discuss the results of the VC model when used with imbalanced and balanced datasets, where it achieved the best results among the other models (see Table 5).
Table 2 shows that the VC model performed the best among the other models for all metrics used (recall of 0.67, F1 score of 0.60, AUROC of 0.71 and AUCPR of 0.65) except for precision (0.55). When the balanced training dataset was utilized, the VC model also achieved the optimal outcomes, with a rise in recall rate to 0.75, despite no enhancement in the remaining metrics (see Table 3). Although the VC model showed a higher recall of 0.75, it showed an F1 score of 0.61. The F1 score was not as good as one might hope due to the low value of the precision metric. Low precision and high recall indicate that the class was detected well but also included observations of other classes (false positives), which can be confirmed by the AUROC curve results in Fig. 1. Table 4 shows the results of the prediction models when a balanced training and validation dataset was used. Table 4 shows a significant improvement for all models, with the best results (recall 0.75, precision 0.65, F1 score 0.70, AUROC score 0.74, and AUCPR 0.75) obtained by the VC model. Using balanced datasets (see Tables 3 and 4), the VC model achieved AUROC rates of 0.71 and 0.74, respectively. Generally, the AUROC results presented here are highly interesting, which means about 71% and 74% of the patients with MEs are correctly predicted by this model, and this is significantly better than chance.

Accuracy of the VC model with balanced training and validation datasets: AUCPR and AUROC.
Due to the imbalance of the dataset used for validation, the AUROC can provide a false impression of the quality of the classifier (Table 2). As shown in Table 2, the AUROC was consider high 0.71, although the recall was 0.67, suggesting that the classifier performed well, which was not the case. However, although most of the negative cases are correctly classified, many of the positives may be misclassified, which is most important for model performance. We also noticed that in Table 3 despite the significant improvement in the recall metric, improvements in other metrics were not noticeable, especially in terms of precision, AUROC and AUCPR. The low precision is due to the increase in false positives, which can be confirmed by examining the AUROC curve in Fig. 1. The ROC curve plots the TPR versus FPR at different classification thresholds, and as the threshold decreases, the recall increases because we identify more patients who have medication errors. However, as our recall increases, our precision decreases because, in addition to increasing the number of true positives, we increase the number of false positives. Therefore, the AUCPR and precision were also used to evaluate the quality of the ML models. Thus, the recall and AUCPR values in Table 2 show that the performance of the ML model is not good, contrary to what the AUROC value reveals. To confirm the above results, we balanced the validation dataset using the undersampled ENN method such that it contained an equal number of positives and negatives, which improved all the metrics used (see Table 4). The results in Table 4 clearly revealed that the improvement in all the metrics was associated with an increase in the number of false positives because of the imbalance of the validation dataset. Figure 2 also shows significant improvement in the AUCPR compared to the AUCPR, as shown in Fig. 1.
Although the above results are very promising compared to those of existing tools, we still need to test our ML tool in a real-life evaluation to confirm its effectiveness. Therefore, to validate our tool, we performed a retrospective evaluation simulating real-life use to confirm its effectiveness. To conduct this evaluation, data from 317 patients who underwent medication reconciliation during the period 11/27/2023 to 02/04/2024 were used. Of the 317 patients, 93 were found to have at least one unintended discrepancy, which led to pharmacist intervention. Our ML tool was used to prioritize the 317 patients in descending order according to their likelihood of experiencing a medication error. A specific number of patient files (110 files) with high scores were subsequently selected. On the other hand, a group of clinical pharmacists was also recruited to carry out a selection process for the same number of patient files (110 files) but randomly. Finally, for each approach, the total number of patients who had at least one unintended discrepancy was recorded.

Comparison of medication reconciliation results using the ML tool (VC model) and the existing tool.
To determine the extent to which the objectives behind this study were met, first, we will discuss the results of the random approach used to select patients admitted for medication reconciliation and its effectiveness. Then, we will discuss the results obtained using our ML tool (VC model) for the same number of patients and compare them with those of the random approach. Figure 3 shows the results for both approaches. Using a random approach, 110 patients were randomly selected for medication reconciliation. Twenty-three of the 110 patients had at least one unintended discrepancy, while 87 patients did not. In other words, the random approach succeeded in identifying only 21% of the total selected patients. When using the ML tool, 110 patients were selected for medication reconciliation, and 45% of the total selected patients were found to have at least one unintended discrepancy, which led to pharmacist intervention, with an improvement of 113% compared to the random approach. These results confirm that the ML tool outperformed the existing tool used at CHU of Reims in terms of its ability to identify a greater number of patients exposed to medication errors. This approach could lead to increased capabilities of the clinical pharmacy department so that the medication reconciliation process would be more efficient and would reduce the burden on clinical pharmacists.
In summary, improving patient safety by reducing medication errors is a top priority in hospital health systems. Currently, medication reconciliation by clinical pharmacists is the standard method for preventing potential adverse drug events. These interventions are often limited by human resources, and patients at high risk for errors in their prescription orders need to be targeted. A strength of this study is that it included patients from internal medicine, surgical, and obstetric wards, as well as follow-up care and rehabilitation units; therefore, the findings are representative of daily clinical practice.
The single-center nature of our study was one of the limitations of this study. In addition, neonatology and intensive care unit patients were not included because these units do not use Easily software for medication prescription. However, due to the specificity of these units, pharmacists work directly on them. Therefore, medication reconciliations are never carried out in this type of services. Thus, there is no evidence of the accuracy of our model in identifying patients at high risk in these units; therefore, our model cannot be generalized to these patients. In fact, our study focused on medication reconciliation, which is mainly carried out in a hospital setting in the current medical practice. This focus limits the immediate applicability to primary care, where the data landscape and workflows differ significantly. In future work, we plan to incorporate data from other hospitals and possibly from primary care settings to improve the generalizability of our model. Our goal is to adapt the model to different healthcare environments, not just hospitals, by incorporating diverse data sources. While our current focus is on hospitalized patients, this work provides a solid foundation for expanding medication reconciliation efforts to other healthcare contexts, especially with a model trained on varied data sources.
It would be interesting in future work to improve the performance of our tool. The performance of an ML tool can be enhanced by obtaining abundant and accurate datasets. However, adding new and accurate data requires carrying out a large number of medication reviews, which is limited by a lack of well-trained human resources. This has motivated us to deploy our tool throughout other hospitals, as this will enable us to benefit from the expertise of a larger number of clinical pharmacists to confirm our findings and as an automated way to produce data that are used to update the model’s learning dataset.
Conclusion
We developed and internally validated a machine learning-based predictive tool to predict patients with a high risk of at least one medication error during admission. Our predictive tool works as a digital tool to improve patient safety by identifying as many patients at risk of medication error as possible using available human resources. The positive experimental results of this tool showed a superior improvement of 113% over the existing tool by targeting patients at risk of medication errors upon admission to Reims University Hospital.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author upon reasonable request.
References
Medication errors | European Medicines Agency. https://www.ema.europa.eu/en/human-regulatory-overview/post-authorisation/pharmacovigilance-post-authorisation/medication-errors (Accessed 28 May 2024).
Nguyen, T-L. et al. Improving medication safety: development and impact of a multivariate model-based strategy to target high-risk patients. PLOS ONE 12, e0171995. https://doi.org/10.1371/journal.pone.0171995 (2017).
Qu’est ce qu’une erreur médicamenteuse ? - ANSM. Agence nationale de sécurité du médicament et des produits de santé. https://archive.ansm.sante.fr/Declarer-un-effet-indesirable/Erreurs-medicamenteuses/Qu-est-ce-qu-une-erreur-medicamenteuse/(offset)/0 (Accessed 23 August 2023).
Santé, A. F. A. Tous impliqués pour signaler les événements indésirables associés aux soins. Fr. Assos Santé. (2022). https://www.france-assos-sante.org/2022/11/18/tous-impliques-pour-signaler-les-evenements-indesirables-associes-aux-soins/ (Accessed 23 August 2023).
Donaldson, L. J. et al. Medication without harm: WHO’s Third Global Patient Safety Challenge. Lancet 389, 1680–1681. https://doi.org/10.1016/S0140-6736(17)31047-4 (2017).
Gøtzsche, P. C. Our prescription drugs kill us in large numbers. Pol. Arch. Med. Wewn 124 11, 628–634 (2014).
Barnsteiner, J. H. Medication Reconciliation. In: (ed Hughes, R. G.) Patient Safety and Quality: An Evidence-Based Handbook for Nurses. Rockville (MD): Agency for Healthcare Research and Quality (US) (2008).
Mekonnen, A. B., McLachlan, A. J. & Brien, J. E. Pharmacy-led medication reconciliation programmes at hospital transitions: a systematic review and meta-analysis. J. Clin. Pharm. Ther. 41, 128–144. https://doi.org/10.1111/jcpt.12364 (2016).
Karnon, J., Campbell, F. & Czoski-Murray, C. Model-based cost-effectiveness analysis of interventions aimed at preventing medication error at hospital admission (medicines reconciliation). J. Eval Clin. Pract. 15, 299–306. https://doi.org/10.1111/j.1365-2753.2008.01000.x (2009).
Décret 2019 – 489 du 21 mai 2019 relatif aux pharmacies à usage intérieur. (2019).
https://www.omedit-grand-est.ars.sante.fr/media/83094/download?inline (Accessed 23 August 2023).
Mueller, S. K. et al. Hospital-based medication Reconciliation practices: a systematic review. Arch. Intern. Med. 172, 1057–1069. https://doi.org/10.1001/archinternmed.2012.2246 (2012).
Anderson, L. J. et al. Effect of medication reconciliation interventions on outcomes: a systematic overview of systematic reviews. Am. J. Health Syst. Pharm. 76, 2028–2040. https://doi.org/10.1093/ajhp/zxz236 (2019).
Deawjaroen, K. et al. Clinical usefulness of prediction tools to identify adult hospitalized patients at risk of drug-related problems: a systematic review of clinical prediction models and risk assessment tools. Br. J. Clin. Pharmacol. 88, 1613–1629. https://doi.org/10.1111/bcp.15104 (2022).
Duval, M. et al. Conciliation médicamenteuse à l’entrée Des patients dans une unité de chirurgie orthopédique: retour d’expérience sur plus de 2 ans de pratique. Ann. Pharm. Fr. 79, 700–709. https://doi.org/10.1016/j.pharma.2021.03.003 (2021).
Vallecillo, T. et al. Development and validation of a ready-to-use score to prioritise medication reconciliation at patient admission in an orthopaedic and trauma department. Eur. J. Hosp. Pharm. 29, 264–270. https://doi.org/10.1136/ejhpharm-2020-002283 (2022).
Boissinot, L. et al. Conciliation Des Traitements médicamenteux en gériatrie: Pertinence et faisabilité. Pharmactuel 47 (2014).
Saint-Germain, P. et al. Impact clinique des divergences de traitement constatées chez 200 patients conciliés dans un service de gériatrie aiguë. Rev. Médecine Interne 37, 667–673. https://doi.org/10.1016/j.revmed.2016.02.017 (2016).
Barbier, G. et al. Sécurisation Du parcours patient en gériatrie: quels facteurs de risque d’erreurs médicamenteuses à L’admission ? Pharm. Hosp. Clin. 55, 275–281. https://doi.org/10.1016/j.phclin.2020.04.011 (2020).
Poinsat, T., Sitbon, J. C. M., Ganansia, O., Gerlier, C. & Bézie, Y. Conciliation médicamenteuse d’entrée en amont des services d’aval des urgences: faisabilité et intérêts. Pharm. Hosp. Clin. 7260, 227–320. https://doi.org/10.1016/j.phclin.2020.11.004 (2020).
Harang, C. et al. Conciliation médicamenteuse à L’admission: un réel impact sur la qualité de notre prise en charge. Rev. Médecine Interne 39, A202. https://doi.org/10.1016/j.revmed.2018.10.192 (2018).
Audurier, Y. et al. Development and validation of a score to assess risk of medication errors detected during medication reconciliation process at admission in internal medicine unit: SCOREM study. Int. J. Clin. Pract. 75, e13663. https://doi.org/10.1111/ijcp.13663 (2020).
Cornuault, L. et al. Identification of variables influencing pharmaceutical interventions to improve medication review efficiency. Int. J. Clin. Pharm. 40, 1175–1179. https://doi.org/10.1007/s11096-018-0668-y (2018).
Hias, J. et al. Predictors for unintentional medication reconciliation discrepancies in preadmission medication: a systematic review. Eur. J. Clin. Pharmacol. 73, 1355–1377. https://doi.org/10.1007/s00228-017-2308-1 (2017).
Falconer, N. et al. Validation of the assessment of risk tool: patient prioritisation technology for clinical pharmacist interventions. Eur. J. Hosp. Pharm. 24, 320. https://doi.org/10.1136/ejhpharm-2016-001165 (2017).
Ebbens, M. M. et al. Prospective validation of a risk prediction model to identify high-risk patients for medication errors at Hospital Admission. Ann. Pharmacother 52, 1211–1217. https://doi.org/10.1177/1060028018784905 (2018).
Bosma, L. B. E. et al. Development of a multivariable prediction model for identification of patients at risk for medication transfer errors at ICU discharge. PLOS ONE 14, e0215459. https://doi.org/10.1371/journal.pone.0215459 (2019).
Jiang, F. et al. Artificial intelligence in healthcare: past, present and future. Stroke Vasc Neurol. 2. https://doi.org/10.1136/svn-2017-000101 (2017).
Batista, G. E. A. P. A., Prati, R. C. & Monard, M. C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 6, 20–29. https://doi.org/10.1145/1007730.1007735 (2004).
He, H. et al. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence). 2008:1322–8. (2008).
Lemaître, G., Nogueira, F. & Aridas, C. K. Imbalanced-learn: a Python Toolbox to tackle the curse of Imbalanced datasets in Machine Learning. J. Mach. Learn. Res. 18, 1–5 (2017).
Pedregosa, F. et al. Scikit-learn: machine learning in Python. J. Mach. Learn. Res. 12, 2825–2830 (2011).
Chen, T., Guestrin, C. & XGBoost: A Scalable Tree Boosting System. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco California USA: ACM :785–94. (2016).
Davis, J. & Goadrich, M. The relationship between Precision-Recall and ROC curves. Proceedings of the 23rd international conference on Machine learning. New York, NY, USA: Association for Computing Machinery. :233–40. (2006).
Siegel, S. & Castellan, N. J. Jr Nonparametric Statistics for the Behavioral Sciences 2nd edn (Mcgraw-Hill Book Company, 1988).
Funding
The authors did not receive support from any organization for the submitted work.
Author information
Authors and Affiliations
Contributions
AA and LG: Data curation, designing, implementing the software, investigating, and experiment. AA, LG, TV, JC, PQ, VV and RM: Conception and interpretation of data. AA: Writing original manuscript. VV and RM: Resources, supervision and project administration. All authors reviewed the manuscript critically for scientific content, and all authors gave final approval of the manuscript for publication.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
The Institut d’Intelligence Artificielle en Santé (IIAS) Research Ethics Committee has confirmed. We confirmed that all experiments in this study were performed in accordance with the relevant guidelines and regulations.
Informed consent
The informed consent was waived by the IIAS research.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Abdo, A., Gallay, L., Vallecillo, T. et al. A machine learning-based clinical predictive tool to identify patients at high risk of medication errors. Sci Rep 14, 32022 (2024). https://doi.org/10.1038/s41598-024-83631-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-83631-w
