
Abstract
Metabolic syndrome (Mets) in adolescents is a growing public health issue linked to obesity, hypertension, and insulin resistance, increasing risks of cardiovascular disease and mental health problems. Early detection and intervention are crucial but often hindered by complex diagnostic requirements. This study aims to develop a predictive model using NHANES data, excluding biochemical indicators, to provide a simple, cost-effective tool for large-scale, non-medical screening and early prevention of adolescent MetS. After excluding adolescents with missing diagnostic variables, the dataset included 2,459 adolescents via NHANES data from 2007–2016. We used LASSO regression and 20-fold cross-validation to screen for the variables with the greatest predictive value. The dataset was divided into training and validation sets in a 7:3 ratio, and SMOTE was used to expand the training set with a ratio of 1:1. Based on the training set, we built eight machine learning models and a multifactor logistic regression model, evaluating nine predictive models in total. After evaluating all models using the confusion matrix, calibration curves and decision curves, the LGB model had the best predictive performance, with an AUC of 0.969, a Youden index of 0.923, accuracy of 0.978, F1 score of 0.989, and Kappa value of 0.800. We further interpreted the LGB model using SHAP, the SHAP hive plot showed that the predictor variables were, in descending order of importance, BMI age sex-specific percentage, weight, upper arm circumference, thigh length, and race. Finally, we deployed it online for broader accessibility. The predictive models we developed and validated demonstrated high performance, making them suitable for large-scale, non-medical primary screening and early warning of adolescent Metabolic syndrome. The online deployment of the model allows for practical use in community and school settings, promoting early intervention and public health improvement.
Similar content being viewed by others

Introduction
Metabolic syndrome (MetS) is a comprehensive manifestation of a group of metabolic abnormalities characterized by insulin resistance, including abdominal obesity, hypertension, hyperglycemia, high serum triglycerides and low serum high-density-lipoprotein-cholesterol (HDL-C)1. In recent years, several epidemiological studies have shown that the prevalence of MetS in adolescents has increased significantly worldwide, reaching 3%−10% in developed regions2,3. This shows that the high prevalence of adolescent MetS has become an important public health problem that urgently needs to be solved.
Insulin resistance due to visceral adiposity is usually at the core of MetS. Visceral adipocytes release various inflammatory mediators and free fatty acids, such as tumor necrosis factor-alpha (TNF-α), interleukin-6 (IL-6), and adiponectin, which trigger a systemic inflammatory response and promote insulin resistance4,5. Moreover, high levels of free fatty acids (e.g. non-esterified fatty acids) entering the bloodstream cause mitochondrial dysfunction and oxidative stress, inhibiting insulin signaling6. In addition, oxidative stress and the action of inflammatory mediators can cause endothelial dysfunction and atherosclerosis, thereby increasing the risk of cardiovascular disease7.
MetS poses a serious threat to the physical and mental health of adolescents today. High blood pressure can lead to headaches, fatigue, and poor concentration, whereas obesity and high blood sugar significantly increase the risk of type 2 diabetes in adolescents8,9. Adolescents with MetS are also thought to be more likely to develop non-alcoholic fatty liver disease, which can lead to liver damage and dysfunction10,11. In addition, MetS has been associated with a range of mental health problems, and adolescents with this disease are more likely to experience psychological problems including depression and anxiety12,13. The impact of MetS on the health of adolescents in the future is even more profound. A history of metabolic syndrome in adolescence is a significant predictor of cardiovascular disease and type 2 diabetes in adulthood. This means that adolescents with MetS face greater risks of heart attack, stroke, and diabetes than adults do14,15,16. Additionally, studies have shown that MetS is associated with other chronic diseases in adulthood. For example, obesity and insulin resistance increase the risk of polycystic ovary syndrome and certain types of cancer, while the long-term systemic inflammation caused by MetS is also thought to underlie chronic diseases such as fatty liver and autoimmune disorders17,18,19,20.
If we can achieve early detection, early control and early treatment of metabolic syndrome in adolescents, we can significantly improve the current health level and quality of life of adolescent patients, and reduce their risk of more chronic diseases in the future.
Currently, several studies have developed predictive models for metabolic syndrome that include methods such as normograms and machine learning algorithms21,22,23. However, there are still several problems with these models. Some studies are based primarily on data from adults and lack consideration of the specific physiologic and metabolic characteristics of adolescents. Other studies include fewer variables or populations and have limited predictive power for metabolic syndrome. Existing diagnostic criteria often require blood tests and blood pressure measurements to obtain appropriate data. The basic equipment required for blood collection and testing, as well as blood pressure measurement, is usually only available in healthcare facilities, which is not conducive to large-scale rapid screening of populations in schools, neighborhoods, or even homes. The key point of MetS management is early detection and intervention, which may be delayed by having to visit a healthcare facility for screening. Therefore, we hope to find a simpler and easier way to obtain indicators, such as weight, length and other indicators, that can be objectively quantified, but can also be realized through simple operations, do not need special equipment, and are economical and convenient.
Therefore, we are committed to including a larger population of adolescent participants and more variable data from the National Health and Nutrition Examination Survey (NHANES). To develop a model that facilitates self-assessment of MetS risk in the youth population and their families and is deployed online as a web tool, after biochemical indicators are excluded to enable earlier prevention and intervention of metabolic syndrome in the youth population.
Methods
Data sources
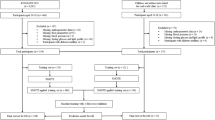
The data for this study were derived from the NHANES, which is sponsored by the Centers for Disease Control and Prevention (CDC). The NHANES data are nationally representative through the design of a complex multistage sample. As shown in Fig. 1, we counted data from 5 cycles from 2007–2016, with a total of 50,588 participants. After excluding participants aged outside the range of 12 to 19 years and those whose waist circumference data, fasting glucose data, serum HDL data, triglyceride data, and blood pressure measurements were missing, 2459 eligible participants were included. Owing to missing NHANES data, we used the predictive mean matching (PMM) method for variables other than diagnostic variables to fill in the gaps based on data from other variables.

Flow chart for patient inclusion. Flow chart of the selection of participants from NHANES 2007–2016. BP, blood pressure; LDL-C, high density BP, blood pressure; LDL-C, high density lipoprotein cholesterol; GLU, fasting glucose.
Diagnostic
MetS in adolescents remains somewhat controversial, so we defined the diagnosis of MetS as meeting any three of the following five criteria, on the basis of the recommendations of the American Heart Association (AHA) and the National Heart, Lung, and Blood Institute (NHLBI)24, as well as the Comprehensive Guidelines for Cardiovascular Health and Risk Reduction in Young People25:
I. Waist circumference ≥ 102 cm in men and ≥ 88 cm in women; II. Serum triglycerides ≥ 130 mg/dl; III. HDL-C < 40 for men and < 50 for women; IV. Systolic blood pressure ≥ 130 mmHg or diastolic blood pressure ≥ 85 mmHg; V. Fasting blood glucose ≥ 5.6 mg/dl.
Variable definition and variable selection
The variables we screened from the NHANES database consisted of four parts: I. Diagnostic variables of MetS. II. The participants’ demographic data included race, age, sex, the household poverty income ratio (PIR), family history of diabetes, physical activity, and sedentary time. III. Participant physical measurement data, including height, weight, body mass index (BMI), upper arm length, upper wall arm circumference, and thigh length. IV. Participant consumer behavior questionnaire data.
Physical activity was defined according to the NHANES questionnaire, and adolescents who performed less than 10 min of vigorous or moderate physical activity per week were defined as inactive. PIR was the ratio of household income to the poverty line, with ≤ 1 indicating that the participant's household was in poverty. The BMI sex-age-specific percentage (BMI_PERC) was defined according to the CDC2000 growth charts, which better reflects the physical development of adolescents.
Baseline analysis
In the baseline analysis, considering the complex sampling design and varying sampling weights of NHANES, we applied appropriate NHANES weight settings to calculate the weighted means of continuous variables along with their corresponding standard errors, and determined the weighted percentage shares of categorical variables. Weighted t-tests and chi-square tests were then used to evaluate the differences in the distribution of continuous and categorical variables between the MetS group and the non-MetS group.
Feature selection
We developed a Least Absolute Shrinkage and Selection Operator (LASSO) regression model to explore the relationships between all nonbiochemical indicator variables, excluding diagnostic variables, and the prevalence of MetS. LASSO regression controls the complexity of the model by introducing a regularization parameter, lambda. Through L1 regularization of the feature coefficients, LASSO regression can compress the coefficients of some features to zero, which enables feature selection. We subsequently optimized the LASSO model via 20-fold cross-validation and selected lambda.1se as the regularization parameter for the final model.
Modeling
To build the MetS prediction model and test its predictive ability, we divided all the participant data into a training set and a validation set at a ratio of 7:3.
To solve the problem of category imbalance and improve model performance, we performed sample augmentation using the SMOTE algorithm on the training set data before model building, with an augmentation ratio of 1:1. After that, we used these variables as independent variables to build models based on the expanded training set data. Including Decision Tree, Random Forest (RF), Extreme Gradient Boosting (XGB), Gradient Boosting Machine (GBM), Light Gradient Boosting Machine (LGB), Support Vector Machine (SVM), Plain Bayes, and Multilayer Perceptron (MLP). In total, eight machine learning models and a multivariate logistic regression model were constructed.
Model evaluation and interpretation
For the validation set, we constructed ROC curves and confusion matrices and evaluated the 9 models via the C-index, Youden's index, F1 scores, and Kappa scores to identify the model with the best discriminative power. We then plotted calibration curves and decision curves to further validate the predictive ability and application value of the models. The models were interpreted via Shapley Additive exPlanations (SHAP).
All analyses and modeling in this study were performed with the statistical software R 4.3.3 and RStudio. All tests were two sided and considered statistically significant with a p-value of < 0.05.
Results
Baseline analysis
Based on the diagnostic criteria, 139 out of 2459 adolescents from 5 NHANES-cycles were diagnosed with MetS, as detailed in Table 1. Compared with adolescents without metabolic syndrome, those with metabolic syndrome had a greater waist circumference (109.59 cm, P < 0.0001), upper arm length (38.15 cm, P < 0.0001), upper arm circumference (36.74 cm, P < 0.0001), age (16.03 years, P = 0.0103), percentage of family history of diabetes (23.78%, P = 0.0001), and BMI_PERC (0.97, P < 0.0001) values were significantly greater. In contrast, the PIR (1.98, P = 0.0046) was lower. There was also a significant difference in the racial distribution of patients in the two groups. In the MetS group, the proportion of Mexican Americans was significantly greater (28.24%), whereas the proportions of non-Hispanic blacks (9.92%), non-Hispanic whites (53.15%), and other ethnic groups (1.81%) were significantly lower.
Predictor screening and modeling
After excluding laboratory biochemical indicators and diagnostic criteria, we built a LASSO regression model and performed 20-fold cross-validation, and the results are shown in Figs. 2 and 3. We selected lambda.1 se and screened a total of five highly effective predictors of whether MetS was prevalent, including BMI_PERC, weight, upper arm circumference, thigh length and race.

Path diagram for selecting variables for the LASSO regression model. The horizontal axis is the logarithmized penalty parameter log(λ), and the vertical axis is the corresponding regression coefficient value. The horizontal axis is the logarithmized penalty parameter log(λ), and the vertical axis is the corresponding regression coefficient value. As the penalty parameter increases, the regression coefficients of each variable will eventually approach zero, and thus, as the penalty parameter increases, the regression coefficients of each variable will eventually approach zero; LASSO regression can filter out the variables with the greatest predictive value. Variable coding is from the NHANES.

Results of the 20-fold cross-validation of the LASSO regression model. The horizontal axis is the penalty parameter log (λ), and the vertical axis is the binomial deviation. The red solid dots represent each λ value corresponding to the mean deviation, and the vertical gray error bars indicate the standard error of that deviation. The red solid dots represent each λ value corresponding to the mean deviation, and the vertical gray error bars indicate the standard error of that deviation. The red solid dots represent each λ value corresponding to the mean deviation, and the vertical gray error bars indicate the standard error of that deviation. The upper numbers indicate the number of nonzero coefficients under each value. This figure is used to evaluate the performance of the model at different values of λ and to select the model for each value. This figure is used to evaluate the performance of the model at different values of λ and to select the corresponding variables for model construction.
The overall data were divided into a training set and a testing set at a ratio of 7:3. The difference in the data distributions between the two datasets is demonstrated in Table 2. Because the prevalence of MetS was not high in the original dataset, differences in the distribution of race variables became evident after the division. The remaining variables did not significantly differ in distribution between groups.
Model evaluation
We plotted the ROC curve (Fig. 4) and built a confusion matrix based on the validation set data, and the results are shown in Table 3. After combining the Youden index, AUC, accuracy, F1 score, and Kappa score, we comprehensively evaluated the model performance and concluded that the LGB model had the best model performance.

Receiver operating characteristic curves for 9 models. The values of the receiver operating characteristic curve (ROC) and its corresponding area under the curve (AUC) for nine different machine learning models. The horizontal axis is 1-Specificity, and the vertical axis is Sensitivity. The closer the curve is to the upper left corner, the better the model's classification performance.
After that, we plotted the calibration curves of each model, and the results are shown in Fig. 5. The results show that the calibration curves of the models are incomplete except for three models, XGB, LGB and Random Forest. Among them, the LGB model mean absolute error (MAE) is the lowest (0.004), the Random Forest model is second (0.007), and the XGB model is the highest (0.012). However, the MAEs of all three models are lower than 0.05, which proves that the models have relatively good predictive ability and less deviation from the actual probability.

Calibration curves for 9 predictive models. The horizontal axis (X-axis) represents the probability of illness predicted by the model, and the vertical axis (Y-axis) represents the actual observed proportion of illness.
In addition, we plotted the decision curve. The results are shown in Fig. 6, where the LGB model, the XGB model, and the Random Forest model all yield high net benefits under a wider range of thresholds, with significant clinical decision benefits. In summary, our evaluation results demonstrate that our machine learning model can identify adolescent MetS patients well and benefit them.

Decision curves for nine forecasting models. The horizontal axis (X-axis) represents the threshold probability of the model prediction, i.e., individuals with a predicted probability greater than this threshold are categorized as positive. The vertical axis (Y-axis) represents Net Benefit, whose value combines true positives and false positives predicted by the model. The “All” line (All): scenario in which all patients are assumed to receive treatment. The “No Treatment” line (None): a scenario in which all patients are assumed to receive no treatment.
Finally, we plotted SHAP hive plots (Fig. 7) showing the effects of different features on the model output. BMI_PERC had the greatest impact on model output, with a high percentage of individuals contributing positively towards the predictions; the higher the percentage was, the greater the contribution. Weight (BMXWT) and arm circumference (BMXARMC) subsequently contributed negatively to the prediction, mainly in individuals with low values. Thigh length (BMXLEG) had the fourth highest effect on model output, with high value individuals providing primarily negative contributions, whereas low value individuals provided positive contributions. Race contributed the least to model predictions, with non-Hispanic blacks and other races providing predominantly negative contributions and Mexican Americans and other Hispanics providing predominantly positive contributions.

SHAP Beehive Diagrams for Random Forest Models. The horizontal axis (X-axis) represents the SHAP value (how much the feature affects the prediction) for each sample. The vertical axis (Y-axis) lists the important features in the model, which are sorted from top to bottom in order of importance. Each point represents the SHAP value for one sample, where yellow dots indicate high individual values and blue dots indicate low individual values.
Online deployment of the model
Finally, to utilize our predictive model in real-world scenarios, we performed an online deployment of the LGB model26.
Discussion
Our study analyzed five cycles of NHANES data, covering all adolescent participants during the period, with the aim of building reliable and robust predictive models of adolescent MetS. We built LASSO regression models using a total of 27 variables across three dimensions: demographic data, physical measurements, and consumer behavior questionnaire data. A machine learning model was also built using significant variables screened by 20-fold cross-validation, allowing the model to capture complex interactions between variables at multiple levels.
The effective identification of predictors is key to establishing an early prediction mechanism for MetS in high-risk adolescents. After excluding diagnostic criteria and biochemical indicators, by building a LASSO regression model and cross-validation with lambda.1 se, we screened five body measures with significant predictive value for MetS, including BMI_PERC, body weight, upper arm circumference, thigh length, and ethnicity.
Our study revealed that the racial distribution of MetS patients is dramatically different from that of normal adolescents and has a significant role in the prediction of MetS. Racial differences are reflected in genetics, culture, dietary habits and lifestyles, which affect metabolic health. Some studies have shown that certain races, such as Mexican Americans and African Americans, are more likely to develop MetS27. This may be related to genetic susceptibility, dietary habits, the living environment, and culture. For example, Mexican–American and African-American children have significantly greater intakes of high-sugar beverages and fast food than other races, and these dietary habits are associated with a greater risk of obesity and MetS28.
In addition, body weight, BMI_PERC and upper arm circumference serve as indicators of the degree of abdominal obesity and visceral fat accumulation in participants, and the core of metabolic syndrome is usually insulin resistance caused by visceral fat. They have been well documented in previous studies as key predictors of MetS27,28. However, thigh length is generally not considered a traditional indicator of metabolic health. It has been suggested that longer thigh length may be associated with greater muscle mass and lower levels of visceral fat, and that these factors all contribute to a lower risk of MetS29,30. In our study, thigh length, as a new indicator, played an important role in the prediction of MetS.
After a side-by-side comparison, we found that the LGB model (AUC: 0.969, Youden's: 0.923, Accuracy: 0.978, F1: 0.989, Kappa: 0.800) had the best predictive performance. Subsequent evaluation of the plotted calibration curves and decision curves indicated that the LGB model, as a tool with strong identification ability, can effectively identify the group of adolescents at high risk of MetS and help for further early intervention. We also plotted SHAP hive plots to interpret the random forest model, and the five variables were ranked in descending order of importance: BMI_PERC, weight, upper arm circumference, thigh length, and race. The first three of these predictors all showed positive correlations with the probability of developing the disease in the model, whereas thigh length, in contrast, showed a predominantly negative correlation, i.e., the longer the thigh was, the lower the likelihood of developing MetS. Finally, we deployed the model online for social use.
In addition, the model performance of the support vector machine model was poor. This may be due to the lower probability of occurrence of MetS in adolescents, leading to a category imbalance in the validation set. This bias ultimately led to poor results for the support vector machine model on performance data other than the AUC.
Through in-depth analysis of NHANES data from 2007–2016, this study successfully developed a predictive model for MetS in adolescents, based on nonbiochemical indicators, and demonstrated its robust predictive performance. The key point of the study is that we excluded all the indicators that require instruments for measurement, such as biochemical indicators and blood pressure, which results in the process of obtaining indicators without expensive laboratory equipment, reducing the cost of testing, and making it overall simpler and more efficient. However, it is important to note that the model is primarily applicable to populations resembling those in the NHANES dataset and may require further validation in other demographic or epidemiologic contexts. While this method is particularly suitable for large-scale screening and surveillance in public health systems and in settings such as neighborhoods, schools, and homes, future studies are needed to evaluate its accuracy and generalizability across diverse populations and settings.
Based on the findings of this study, policy recommendations can be made to public health and education authorities, such as the introduction of regular health screening in schools, the inclusion of simple physical measures, and the early identification and warning of adolescents at high risk for MetS, to provide a scientific basis for more effective public health policies. In addition, the results of this study can be utilized to carry out adolescent health education and publicity activities to increase public awareness of and attention to MetS. The health awareness and self-management ability of adolescents and parents can be enhanced through a variety of methods, such as scientific lectures, health promotion and interactive experiences.
Nevertheless, our study has several limitations. First, our data were derived from the NHANES, in which the questionnaire data relied on participants' self-reports, which may affect the accuracy of the data. Second, the NHANES data are cross-sectional and do not provide evidence of causality, and the lack of longitudinal data limits an in-depth understanding of the developmental process of MetS. Third, although we included a wide range of variables, we may still have missed some important underlying factors because MetS is influenced by numerous factors, such as psychological stress and genetic factors. Therefore, further localized data are needed to validate the model and consider more predictor variables. Fourth, although machine learning models such as LGB excel in predictive performance, their complexity may lead to a reduction in the model's explanatory power.
To address the limitations of the current study, future research should focus on the following areas. First, the inherent limitations of cross-sectional designs restrict causal inference and hinder the model's ability to predict the dynamic progression of diseases. Although we integrated multiple cycles of NHANES data and applied sample weighting adjustments to ensure the representativeness of the data, these methods cannot fully overcome the inherent shortcomings of cross-sectional data. Future research could adopt Inverse Probability Weighting (IPW) to reduce the influence of confounding factors by adjusting sample weights, thereby improving the model's causal inference ability. Additionally, studies have shown that combining bootstrap simulation and SHAP techniques can enhance model interpretability and help explore causal relationships between variables, which may support overcoming the limitations of cross-sectional data31,32. Moreover, combining longitudinal data with time-series models can provide deeper insights into the dynamic development and potential causal relationships of MetS.
To further validate the model's broad applicability, external validation studies using multi-center datasets (e.g., the UK Biobank and the China Health and Nutrition Survey (CHNS)) are necessary. Exploring adjustments to prediction thresholds for different epidemiological contexts is also crucial. Additionally, adopting feature analysis methods could help identify key predictors that perform consistently across different populations, thereby improving the model’s generalizability33.
Another important area for improvement is the specificity of predictive factors. While this study intentionally excluded biochemical indicators to improve practicality, future research could integrate simplified biochemical markers, such as the triglyceride-glucose index (TyG), which could provide a more comprehensive characterization of MetS's metabolic features34. Therefore, future studies should consider incorporating simplified biochemical markers to provide a layered model that balances practicality and accuracy, meeting the needs of diverse resource settings while ensuring precise identification and early intervention of high-risk individuals.
Finally, as demonstrated in biological annotation research, iterative optimization strategies help balance model performance and interpretability and support application in low-resource settings, such as through offline versions or mobile applications35. These efforts will lay a solid foundation for future research, enabling us to further optimize model performance, improve its applicability, and promote its widespread use in public health and clinical screening.
Conclusions
We analyzed data from the 2007–2016 NHANES and used LASSO regression and 20-fold cross-validation to filter out demographic and body measurements with significant predictive power, and ultimately developed a machine-learning model of LGB based on non-biochemical indicators. The results of the model evaluation indicate that the model has relatively excellent predictive performance and has the potential for a wide range of applications. In addition, we interpreted the model using SHAP to increase the readability of the model and make it more convincing. Finally, the model was deployed as a web tool to enable large-scale non-medical primary screening and early warning of METS in adolescents. Future studies will use localized data to further optimize the model and improve its applicability in different settings, providing important support for early identification and intervention of METS.
Data availability
The data used in this study were obtained from NHANES, a national cross-sectional survey administered by the CDC to assess the health and nutritional status of the U.S. The NHANES ensures that the data collected are nationally representative by means of a complex multistage sampling design. Detailed statistics can be found at https://www.cdc.gov/nchs/nhanes/.
Abbreviations
- MetS:
-
Metabolic Syndrome
- NHANES:
-
National Health and Nutrition Examination Survey
- HDL-C:
-
High-Density-Lipoprotein-Cholesterol
- TNF-α:
-
Tumor necrosis factor-alpha
- IL-6:
-
Interleukin-6
- CDC:
-
Centers for Disease Control and Prevention
- AHA:
-
American Heart Association
- NHLBI:
-
National Heart, Lung, and Blood Institute
- PIR:
-
Poverty Income Ratio
- BMI:
-
Body Mass Index
- BMI_PERC:
-
BMI sex-age-specific percentage
- PMM:
-
Predictive mean interpolation
- LASSO:
-
Least Absolute Shrinkage and Selection Operator
- SHAP:
-
SHapley Additive exPlanations
- ROC:
-
Receiver Operating Characteristic Curve
- AUC:
-
Area Under the Curve
- MAE:
-
Mean Absolute Error
- XGB:
-
EXtreme Gradient Boosting
- GBM:
-
Gradient Boosting Machine
- LBG:
-
Light Gradient Boosting Machine
References
Cornier, M. A. et al. The metabolic syndrome. Endocr. Rev. 29, 777 (2008).
Kim, D. J. Trends and risk factors of metabolic syndrome among korean adolescents, 2007 to 2018 (Diabetes Metab J 2021;45:880–9). Diabetes. Metab. J. 46, 349 (2022).
Li, C. et al. High prevalence of metabolic syndrome among adolescents and young adults with bipolar disorder. J. Clin. Psychiat. https://doi.org/10.4088/JCP.18m12422 (2019).
Saltiel, A. R. & Olefsky, J. M. Inflammatory mechanisms linking obesity and metabolic disease. J. Clin. Invest. 127, 1 (2017).
Matsuzawa, Y., Funahashi, T. & Nakamura, T. The concept of metabolic syndrome: contribution of visceral fat accumulation and its molecular mechanism. J. Atheroscler. Thromb. 18, 629 (2011).
Azzu, V., Vacca, M., Virtue, S., Allison, M. & Vidal-Puig, A. Adipose Tissue-Liver cross talk in the control of whole-body metabolism: implications in nonalcoholic fatty liver disease. Gastroenterology 158, 1899 (2020).
Grootaert, M. et al. Vascular smooth muscle cell death, autophagy and senescence in atherosclerosis. Cardiovasc. Res. 114, 622 (2018).
Boles, A., Kandimalla, R. & Reddy, P. H. Dynamics of diabetes and obesity: Epidemiological perspective. BBA-Mol. Basis. Dis 1863, 1026 (2017).
Lega, I. C. & Lipscombe, L. L. Review: Diabetes, obesity, and cancer-pathophysiology and clinical implications. Endocr. Rev. https://doi.org/10.1210/endrev/bnz014 (2020).
Vespoli, C., Mohamed, I. A., Nasser, K. M. & Radhakrishnan, K. Metabolic-Associated fatty liver disease in childhood and adolescence. Endocrin. Metab. Clin. 52, 417 (2023).
Holterman, A. X. et al. Nonalcoholic fatty liver disease in severely obese adolescent and adult patients. Obesity 21, 591 (2013).
Goldbacher, E. M. & Matthews, K. A. Are psychological characteristics related to risk of the metabolic syndrome? A review of the literature. Ann. Behav. Med. 34, 240 (2007).
Pervanidou, P. & Chrousos, G. P. Metabolic consequences of stress during childhood and adolescence. Metabolism 61, 611 (2012).
Mattsson, N., Ronnemaa, T., Juonala, M., Viikari, J. S. & Raitakari, O. T. Childhood predictors of the metabolic syndrome in adulthood The Cardiovascular Risk in Young Finns Study. Ann. Med. 40(7), 542–552 (2008).
Carrasquilla, G. D., Angquist, L., Sorensen, T., Kilpelainen, T. O. & Loos, R. Child-to-adult body size change and risk of type 2 diabetes and cardiovascular disease. Diabetol. 67, 864 (2024).
Hayman, L. L. The cardiovascular impact of the pediatric obesity epidemic: is the worst yet to come?. J. Pediatr. 158, 695 (2011).
Marchesini, G., Petroni, M. L. & Cortez-Pinto, H. Adipose tissue-associated cancer risk: Is it the fat around the liver, or the fat inside the liver?. J. Hepatol. 71, 1073 (2019).
Barone, I., Giordano, C., Bonofiglio, D., Ando, S. & Catalano, S. Leptin, obesity and breast cancer: progress to understanding the molecular connections. Curr. Opin. Pharmacol. 31, 83 (2016).
Jeanes, Y. M. & Reeves, S. Metabolic consequences of obesity and insulin resistance in polycystic ovary syndrome: diagnostic and methodological challenges. Nutr. Res. Rev. 30, 97 (2017).
Motta, A. B. The role of obesity in the development of polycystic ovary syndrome. Curr. Pharm. Des. 18, 2482 (2012).
Son, D. H., Lee, H. S., Lee, Y. J., Lee, J. H. & Han, J. H. Comparison of triglyceride-glucose index and HOMA-IR for predicting prevalence and incidence of metabolic syndrome. Nutr. Metab. Cardiovas. 32, 596 (2022).
Zhou, B. et al. Development and validation of a nomogram for predicting metabolic-associated fatty liver disease in the Chinese physical examination population. Lipids Health Dis. 22, 85 (2023).
Zheng, J. et al. Metabolic syndrome prediction model using Bayesian optimization and XGBoost based on traditional Chinese medicine features. Heliyon 9, e22727 (2023).
Magge, S. N., Goodman, E. & Armstrong, S. C. The Metabolic syndrome in children and adolescents: Shifting the focus to cardiometabolic risk factor clustering. Pediatr. https://doi.org/10.1542/peds.2017-1603 (2017).
Expert Panel on Integrated Guidelines for Cardiovascular Health and Risk Reduction in Children and Adolescents; National Heart, Lung, and Blood Institute. Expert panel on integrated guidelines for cardiovascular health and risk reduction in children and adolescents: summary report. Pediatrics 128(Suppl 5), S213–S256 (2011).
Our Web Prediction Tool can be accessed at the following link: https://azeal123.shinyapps.io/metsonline/.
Oliveira, R. G. & Guedes, D. P. Performance of anthropometric indicators as predictors of metabolic syndrome in Brazilian adolescents. BMC Pediatr. 18, 33 (2018).
Wang, J. et al. Large mid-upper arm circumference is associated with reduced insulin resistance independent of BMI and waist circumference: A cross-sectional study in the Chinese population. Front .Endocrinol. 13, 1054671 (2022).
Liu, G. et al. Association between leg length-to-height ratio and metabolic syndrome in Chinese children aged 3 to 6 years. Prev. Med. Rep. 1, 62 (2014).
Chang, K. V., Yang, K. C., Wu, W. T., Huang, K. C. & Han, D. S. Association between metabolic syndrome and limb muscle quantity and quality in older adults: a pilot ultrasound study. Diabet. Metab. Synd. Obes. 12, 1821 (2019).
Huang, A. A. & Huang, S. Y. Increasing transparency in machine learning through bootstrap simulation and shapely additive explanations. Plos One 18, e0281922 (2023).
Huang, A. A. & Huang, S. Y. Use of machine learning to identify risk factors for coronary artery disease. Plos One 18, e0284103 (2023).
Popin, R. V., Alvarenga, D. O., Castelo-Branco, R., Fewer, D. P. & Sivonen, K. Mining of cyanobacterial genomes indicates natural product biosynthetic gene clusters located in conjugative plasmids. Front. Microbiol. 12, 684565 (2021).
Lou, J. et al. A retrospective study utilized MIMIC-IV database to explore the potential association between triglyceride-glucose index and mortality in critically ill patients with sepsis. Sci. Rep. 14(1), 24081 (2024).
Borriss, R. et al. Bacillus subtilis, the model Gram-positive bacterium: 20 years of annotation refinement. Microb. Biotechnol. 11(1), 3–17 (2018).
Funding
This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.
Author information
Authors and Affiliations
Contributions
YZ and HW contributed equally to this work. They were primarily responsible for the study design, data analysis, and manuscript preparation. RM, BF and RY analyzed and interpreted the statistical results of the different sections. XC and ML completed the collection and initial processing of patient data. LC as corresponding author. Provided leadership in study conception and design, guided the research methodology, and critically reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Ethics approval
All participants provided informed consent as part of the data collection process. The survey protocols were reviewed and approved by the National Center for Health Statistics (NCHS) Research Ethics Review Board. Since this study utilized de-identified secondary data, no additional ethics approval was required. The predictive model has been deployed on an online platform in strict compliance with data privacy and security regulations. The online tool does not collect or store user data, and all inputs are processed locally with encryption. The model is intended solely for educational and screening purposes and is not a formal diagnostic tool. Users are advised to consult healthcare professionals for further evaluation.
Duplicate publication
This manuscript has not been submitted or published elsewhere in part or in full.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, Yz., Wu, Hy., Ma, Rw. et al. Machine Learning-Based predictive model for adolescent metabolic syndrome: Utilizing data from NHANES 2007–2016. Sci Rep 15, 3274 (2025). https://doi.org/10.1038/s41598-025-88156-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-88156-4
