Understanding Loss Functions for Classification
Implementation of loss functions for classification task in Python
Here is the link to my Kaggle notebook code.
Until now, I’m still overwhelmed by the wide variety of options available for each hyperparameter of the model. What are the loss functions? Which activation function to use for the last layer? How to select a loss function for a binary vs. multi-class classification? I realize that those questions will keep coming if I don’t establish a solid understanding of each option. Hence, I created this post as a reference point to answer those questions.
Let’s start with:
What are the loss functions?
Loss functions ( or Error functions) are used to gauge the error between the prediction output and the provided target value. A loss function will determine the model’s performance by comparing the distance between the prediction output and the target values. Smaller loss means the model performs better in yielding predictions closer to the target values.
Let’s define a loss function (J) that takes the following two parameters (Fig. 1):
- Predicted output (
y_pred) - Target value (
y_true)
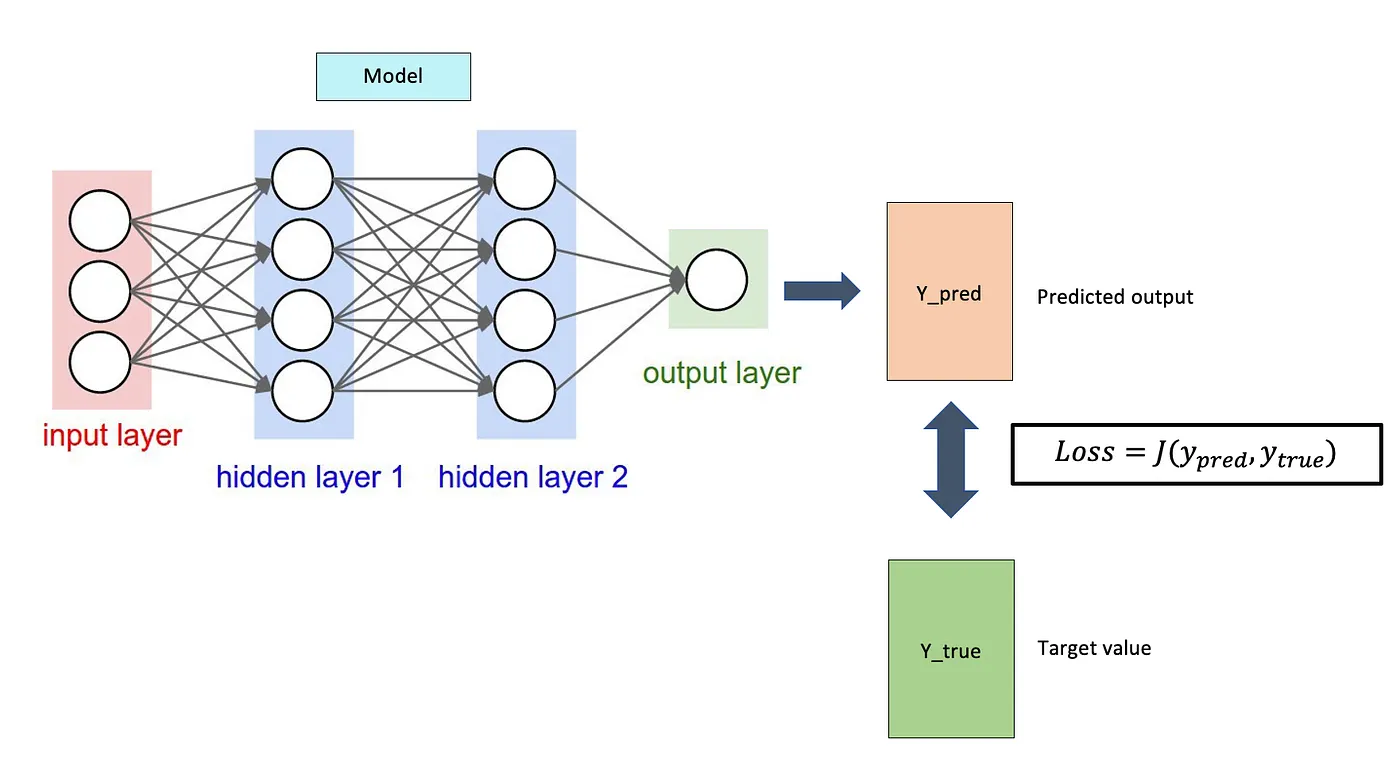
This function will determine your model’s performance by comparing its predicted output with the actual target values. If the deviation between y_pred and y_true is very large, the loss value will be very high.
If the deviation is small or the values are nearly identical, it’ll output a very low loss value. Therefore, a proper loss function is necessary if you want to penalize a model properly during training.
Loss functions change based on the problem statement that your model is trying to solve. The goal of training your model is to minimize the error between the target and predicted value by minimizing the loss function.
How to select a loss function for your task?
Based on the nature of your task, loss functions are classified as follows:
1. Regression Loss:
- Mean Square Error or L2 Loss
- Mean Absolute Error or L1 Loss
- Huber Loss
2. Classification Loss:
Binary Classification:
- Hinge Loss
- Sigmoid Cross Entropy Loss
- Weighted Cross Entropy Loss
Multi-Class Classification:
- Softmax Cross Entropy Loss
- Sparse Cross Entropy Loss
- Kullback-Leibler Divergence Loss
Note: I will focus on Classification Loss for now .
Loss functions for binary classification:
Hinge loss: It’s mainly developed to be used with Support Vector Machine (SVM) models in machine learning. Target variable must be modified to be in the set of {-1,1}.

Squared hinge loss: is a loss function used for “maximum margin” binary classification problems. It has the effect of smoothing the surface of the error function and making it numerically easier to work with. Target variable must be modified to be in the set of {-1,1}.

Use in combination with the tanh() activation function in the last layer.
def HingeLoss(y_pred, y_true):
"""Average hinge loss (non-regularized)
Parameters:
----------
y_true: torch tensor of shape (n_samples,)
True target, consisting of integers of two values. The positive lable must
be greater than the negative label
y_predicted: torch tensor of shape (n_samples,)
Prediction, as output by a decision function (floats)
Returns:
----------
list: tensor list of calculated loss
mean: mean loss of the batch
Hinge loss
"""
list_ = torch.Tensor([max(0, 1 - x*y) for x,y in zip(y_pred, y_true)])
return list_, torch.mean(list_)
Cross-Entropy/Logistic Loss (CE): Cross entropy loss is also known as logistic loss function. It’s the most common loss for binary classification (two classes 0 and 1). We want to measure the distance from the actual class to the predicted value, which is usually a real number between 0 and 1. We should use the sigmoid activation function as the last layer before applying CE. There are 2 types of CE:
- Sigmoid Cross Entropy Loss: transform the x-values by the sigmoid function before applying the cross entropy loss


def BinaryCrossEntropy(y_pred, y_true):
"""Binary cross entropy loss
Parameters:
-----------
y_true: tensor of shape (n_samples,)
True target, consisting of integers of two values.
y_pred: tensor of shape (n_samples,)
Prediction, as output by a decision function (floats)
Returns:
-----------
list_loss: tensor of shape (n_samples,)
BCE loss list
loss: float
BCE loss
"""
#y_pred = np.clip(y_pred, 1e-7, 1 - 1e-7) to avoid the extremes of the log function
term_0 = y_true * torch.log(y_pred + 1e-7)
term_1 = (1-y_true) * torch.log(1-y_pred + 1e-7)
return -(term_0+term_1),-torch.mean(term_0+term_1, axis=0)
- Weighted Cross Entropy Loss: weighted version of the sigmoid cross entropy loss. Here, provide a weight on the positive target to control the outliers for positive predictions.

In Pytorch,
BCELossandBCEWithLogitsLossis for binary labels.
# weigh 1 = 0.5
pos_weight_1 = torch.tensor([0.5])
criterion = torch.nn.BCEWithLogitsLoss(pos_weight=pos_weight_1, reduction='none')
bce_weight_loss_1 = criterion(pred[:200], target[:200]) #forward
# weight 2 = 0.75
pos_weight_2 = torch.tensor([0.75])
criterion = torch.nn.BCEWithLogitsLoss(pos_weight=pos_weight_2, reduction='none')
bce_weight_loss_2 = criterion(pred[:200], target[:200])
#bce_weight_loss.shape
Let’s put all the binary loss functions together!

Loss functions for multi-class classification:
Categorical Cross-Entropy
Instead of using sigmoid as the last layer activation, we use softmax for Categorical Cross-Entropy Loss.


BCE_list_cat, loss = BinaryCrossEntropy(pred[:200].softmax(dim=0),target[:200])
Sparse Categorical Cross-Entropy:
This loss is the same as the softmax cross-entropy one, except instead of the target being a probability distribution, it is an index of which category is true. Instead of a sparse all-zero target vector with one value of one, we just pass in the index of which category is the true value, as follows:

m = nn.LogSoftmax(dim=0)
criterion = nn.NLLLoss(reduction='none')
x = torch.tensor(np.linspace(0,4,400).reshape(200,2), dtype=torch.float32)
y = target[:200].long()#torch.ones(250, dtype=torch.long) # expect the target to be integer (Long)
sparse_loss = criterion(m(x), y)
Kullback Leibler Divergence Loss
To avoid underflow issues when computing this quantity, this loss expects the argument input in the log-space. The argument target may also be provided in the log-space if log_target= True.

kl_loss = torch.nn.KLDivLoss(reduction='none', log_target=True) #specify whether the target is the log space
# input should be a distribution in the log space
input_ = F.log_softmax(pred[:200], dim=0)
log_target = F.log_softmax(target[:200], dim=0)
output = kl_loss(input_, log_target)Let’s visualize all the loss functions for multi-class classification!

Conclusion:
To sum up, I’ve walked through different loss functions, their usages, and how to select a suitable activation function for each classification task. The table below gives a snapshot of where to use each of these functions:

