Machine Learning is becoming increasingly popular in the current tech-savvy era. the application of Machine Learning is everywhere from image recognition to complex forecast models.
However, the most complex and expensive type of Machine Learning trend in use is Labelled Data. They require human expertise to tell a machine about the different data types to help Artificial Intelligence learn it. Both labeled and unlabeled data are used in Machine Learning for different purposes.
Read the blog below to learn more about how data labeling works and gain an understanding of the use cases.
What is Data Labelling in Machine Learning?
Data Labelling is the process of adding meaning to different datasets ensuring that it can be used properly to train a Machine Learning model. Alternatively, Data Labelling is also called Data Annotation.
Labeled data in Machine Learning is typically used in the case of Supervised Learning where the labeled data is input to a model.
Labeled Data vs Unlabelled Data
Machine Learning makes use of both labeled and unlabelled data but, contains some major differences. These are as follows:
-
Labeled data generally has some predefined tags like name, type, or number. For instance, an image contains an apple or a banana. On the other hand, unlabelled data does not contain any tags.
-
Labeled data is part of Supervised learning techniques in ML while unlabeled data is used in unsupervised learning.
-
Acquiring labeled data is quite difficult while unlabelled data is easy to acquire.
How does Data Labelling Work?
Data labeling is an essential process in machine learning and artificial intelligence, where human annotators or data labeling services assign meaningful and accurate labels to raw data to create labeled datasets. These labeled datasets are then used to train and improve Machine Learning models.
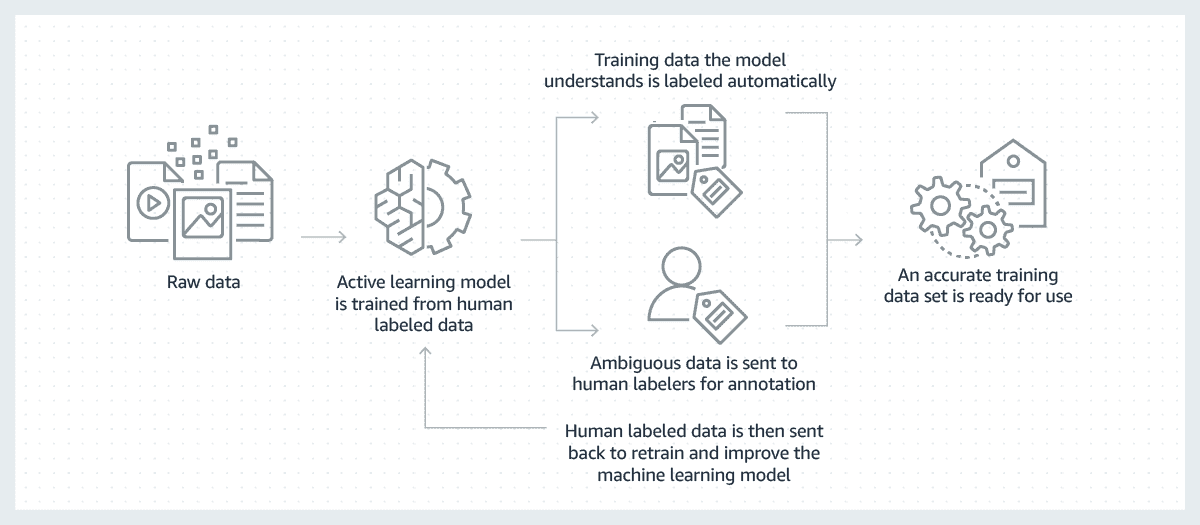
Here’s how data labeling typically works:
Data Collection: The first step involves gathering raw data, which can be in various formats such as images, text, audio, video, or any other type of data that the machine learning model aims to process and analyze.
Annotation Guidelines: Before starting the data labeling process, clear guidelines need to be established. Annotation guidelines define the criteria for assigning specific labels and ensure consistency among different annotators.
Annotation Types: The data labeling process can involve different types of annotations, depending on the machine learning task:Classification: In this case, data is labeled with one or more predefined categories. For instance, labeling an image as either “cat” or “dog.”
- Object Detection: Annotators identify and outline specific objects or regions of interest within an image or video.
- Semantic Segmentation: Each pixel of an image is labeled with the corresponding class it belongs to.
- Named Entity Recognition (NER): Identifying and labeling specific entities (e.g., names, dates, locations) in text data.
- Sentiment Analysis: Assigning sentiment labels (e.g., positive, negative, neutral) to text or audio data.
Annotation Process: Human annotators or data labeling tool work on the raw data and apply the defined annotation guidelines to label the data correctly.
Quality Control: To maintain the accuracy and consistency of the labeled data, a quality control process is crucial. This involves reviewing and validating the annotations for correctness and adhering to the guidelines.
Iterative Process: Data labeling is often an iterative process. As machine learning models are trained and evaluated, the performance is analyzed, and if the model is not performing well, additional or refined data labeling might be necessary to improve the model’s performance.
Data Privacy and Security: When working with sensitive data, data labeling must follow privacy and security measures to protect the individuals whose data is being used.
Tools and Automation: For large-scale projects, data labeling can be time-consuming. Therefore, some organizations use data labeling tools and even incorporate automation techniques (e.g., using Machine Learning models to perform some annotations) to accelerate the process.
Data labeling is a crucial step in the Machine Learning pipeline because the quality and accuracy of the labeled data significantly impact the performance and reliability of the Machine Learning models that are trained on it.
Use Cases of Data Labelling
Use Case 1: Image Recognition and Object Detection
Image recognition and object detection are common applications of data labeling, particularly in computer vision tasks. In this use case, data labeling is employed to annotate images with labels corresponding to the objects present within them. For example, a dataset of images containing various objects like cars, pedestrians, traffic signs, and buildings can be labeled with bounding boxes around each object and associated class labels.
Data labeling plays a critical role in training Machine Learning models to recognize and detect objects accurately. By providing labeled data, the model learns to identify different objects, enabling applications like self-driving cars, surveillance systems, and industrial automation.
To achieve high-quality results, data labeling teams follow detailed annotation guidelines to ensure consistent labeling and accurate bounding box placement. Additionally, quality control measures are implemented to validate the correctness of annotations and maintain dataset integrity.
Use Case 2: Sentiment Analysis in Text Data
Sentiment analysis is a Natural Language Processing (NLP) task used to determine the sentiment or emotional tone of a piece of text, such as customer reviews, social media posts, or product feedback. Data labeling is employed to assign sentiment labels (e.g., positive, negative, neutral) to the text data.
In this use case, annotators follow specific guidelines to understand the context and tone of the text accurately. For instance, in a customer review, they need to identify whether the review expresses satisfaction, dissatisfaction, or a neutral opinion. The labeled dataset is then used to train sentiment analysis models, enabling businesses to gauge customer sentiment at scale.
Data labeling for sentiment analysis involves multiple annotators to ensure consensus and reduce subjective biases. Quality control measures are implemented to maintain labeling accuracy, and sentiment-specific guidelines are followed to handle nuances and complexities in language.
Use Case 3: Named Entity Recognition (NER) for Information Extraction
Named Entity Recognition (NER) is an NLP task used to identify and classify named entities in text data. Named entities can include names of people, organizations, locations, dates, monetary values, and more. Data labeling is employed to annotate the text data, marking the specific spans that represent named entities.
In this use case, data labeling teams use guidelines to identify and categorize various types of named entities correctly. For example, in a news article, annotators need to label the names of people, locations, and organizations mentioned in the text.
NER is crucial for information extraction and is used in various applications such as information retrieval, document summarization, and knowledge graph construction. By providing labeled data, NER models learn to recognize named entities in unstructured text, making it easier to extract relevant information and identify relationships between entities.
To ensure high-quality annotations, multiple annotators review each text, and disagreements are resolved through a consensus mechanism. Iterative feedback loops and ongoing quality checks help maintain the accuracy and consistency of the labeled dataset.
FAQs
How to add data labels in Google Sheets?
Follow these steps:
- On your computer, open a spreadsheet in Google Sheets
- Double-click on the chart you want to change
- Click Customise> Series at the right
- Check the box next to Data Labels to add them to the sheet.
Which approach is used for automatic labeling?
Programmatic data labeling is the approach used for the automatic labeling of data using scripts. It can be useful in automating tasks including image and text annotation, eliminating the need for a large number of human labelers.
Conclusion
The above blog is a full-proof guide for you to understand the Labelled and Unlabelled types of Data in Machine Learning. If you want to learn and apply techniques in training Machine Learning models using Labeled data, you need to be specialized in supervised learning. Moreover, Machine Learning as the latest trend labeled datasets requires human expertise for ensuring that it learns effectively.