
 Logo:
Logo:  Areas Served:
Areas Served: 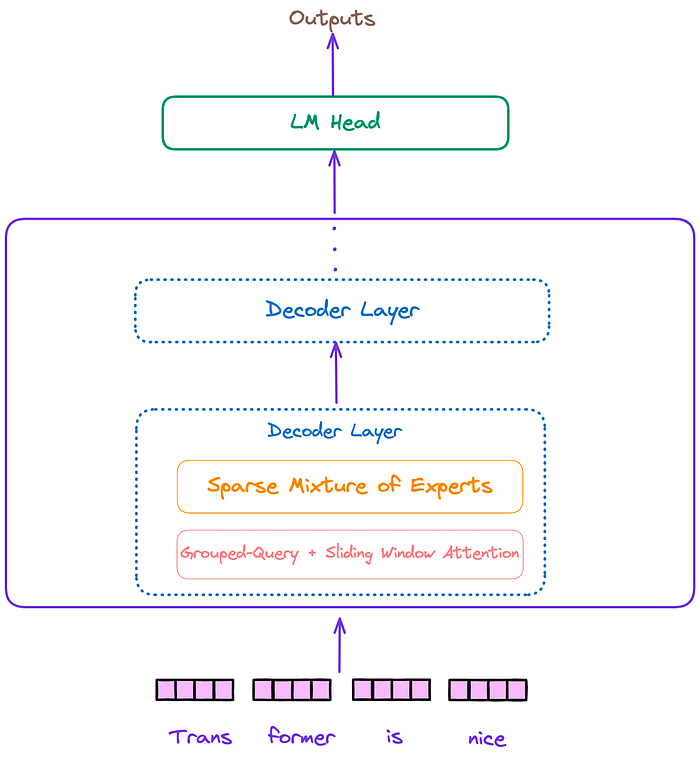
A Detailed Explanation of Mixtral 8x7B Model
Last Updated on January 10, 2024 by Editorial Team
Author(s): Florian
Originally published on Towards AI.
Including principles, diagrams, and code.
Since the end of 2023, the Mixtral 8x7B[1] has become a highly popular model in the field of large language models. It has gained this popularity because it outperforms the Llama2 70B model with fewer parameters (less than 8x7B) and computations (less than 2x7B), and even exceeds the capabilities of GPT-3.5 in certain aspects.
This article primarily focuses on the code and includes illustrations to explain the principles behind the Mixtral model.
The overall architecture of the Mixtral model, similar to Llama and other decoder-only models, can be divided into three parts: the input embedding layer, several decoder blocks, and the language model decoding head. This is illustrated in Figure 1.
Figure 1 : The overall architecture of the Mixtral model. Image by author.
The architecture of the decoder layer is depicted in Figure 2. Each decoder layer mainly consists of two modules: attention and a sparse mixture of experts(SMoE).
Figure 2: Decoder layer. Image by author.
We can see that the Mixtral model incorporates additional features, such as a sparse mixture of experts(SMoE), Sliding Window Attention(SWA), Grouped-Query Attention(GQA), and Rotary Position Embedding (RoPE).
Next, this article will explain these important features.
From Figure 1 and Figure 2, we already know the position of SMoE in the entire… Read the full blog for free on Medium.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts
Popular posts

 for 2021")



Updates

Recent Posts



