









 AI
AI
AI
AI
AI
Our research indicates that the adoption of generative artificial intelligence is occurring across a variety of frameworks with diverse deployment models, data sets and domain specificities.
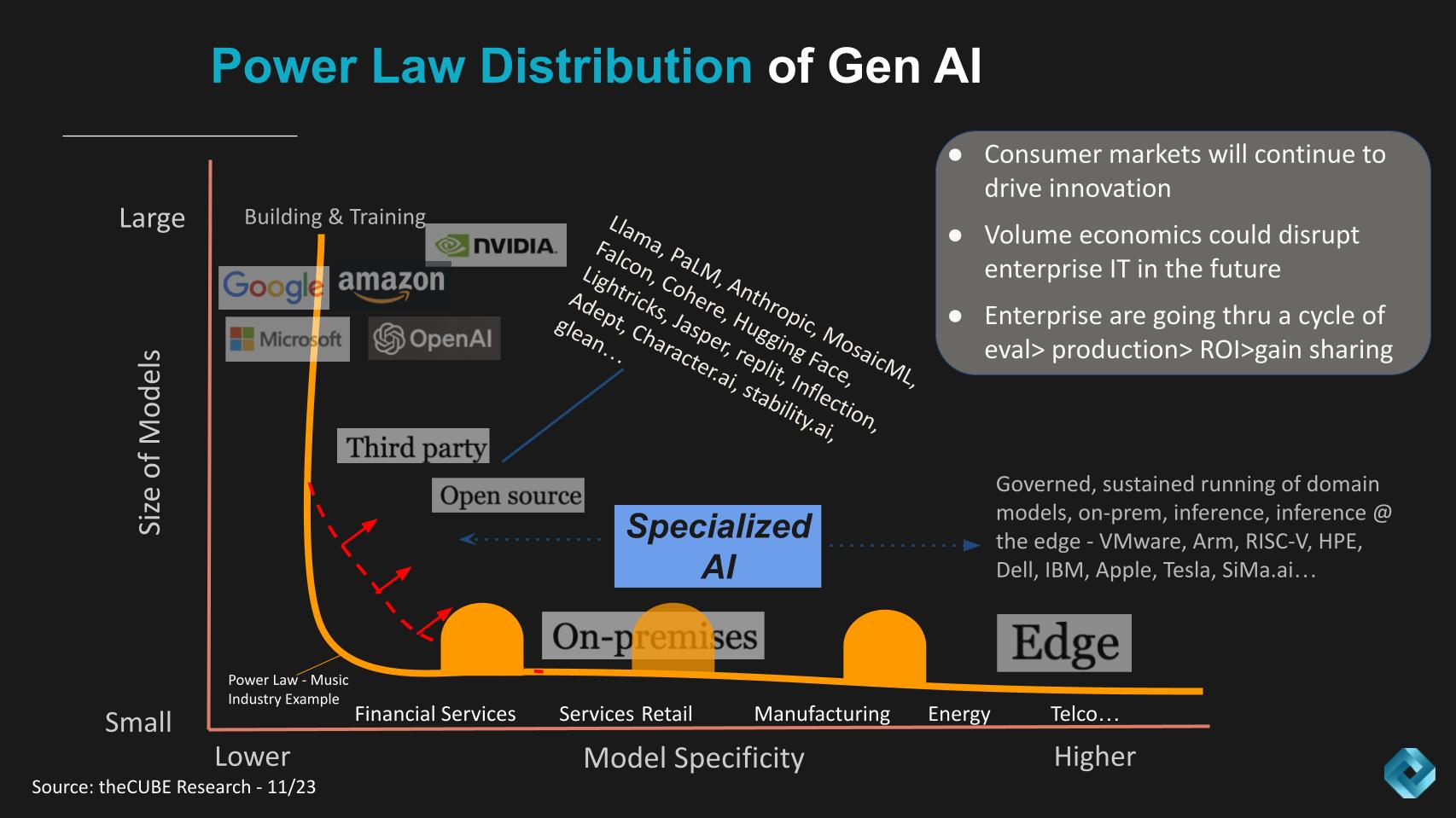
The transformative power of generative AI for industries is colossal, and we are convinced that AI will gravitate to where data lives. The power law of gen AI, developed by theCUBE Research team, describes the adoption patterns we see emerging in the cloud, on-premises and at the edge with a long tail of highly specific domain models across every industry.
In this Breaking Analysis, we revisit the gen AI power law, which informs how we see adoption happening within industries and organizations globally. We introduce new survey data from Enterprise Technology Research that looks at some of the vendors being adopted or considered with a special peek into the emerging technology sector with data on Hugging Face, Anthropic, Cohere and Jasper.
We also comment on the adoption of Meta Platforms’ Llama 2 and the potential impact of open source and other third parties on the shape of the curve. We share our estimates of Microsoft Azure’s AI revenue impact, which we see approaching a $2 billion run rate exiting 2023. Finally, we dig into the impact of retrieval augmented generation, or RAG, using real-world examples with some caveats of RAG implementations that practitioners should consider.

A power law, also called a scaling law, is a relation of the type Y = aX to the power of βeta, where Y and X are variables of interest, βeta is an exponent, the power law exponent, and is a constant that is not critical to our discussion today. The dynamics work as follows: If X is multiplied by a factor of 10, then Y is multiplied by 10 to the power of βeta — one says that Y “scales” as X to the power βeta.
In mathematics, an example of a power law many of you will be familiar with is a Pareto distribution, otherwise known as the 80/20 rule. Now, in precise mathematical terms the rule states that 80% of the outcomes are the result of 20% of the causes. For our purposes in this Breaking Analysis, we’re not so much interested in the cause-and-effect relationship, rather we want to use the shape of a curve to describe the adoption patterns we see evolving in generative AI and what it might mean for organizations, industries, adoption alternatives and the application of data.
The Power Law of Gen AI shown below was developed with our analyst team, including the author, John Furrier and Rob Strechay. It describes how we see the shape of the adoption curve evolving and the long tail of gen AI adoption.
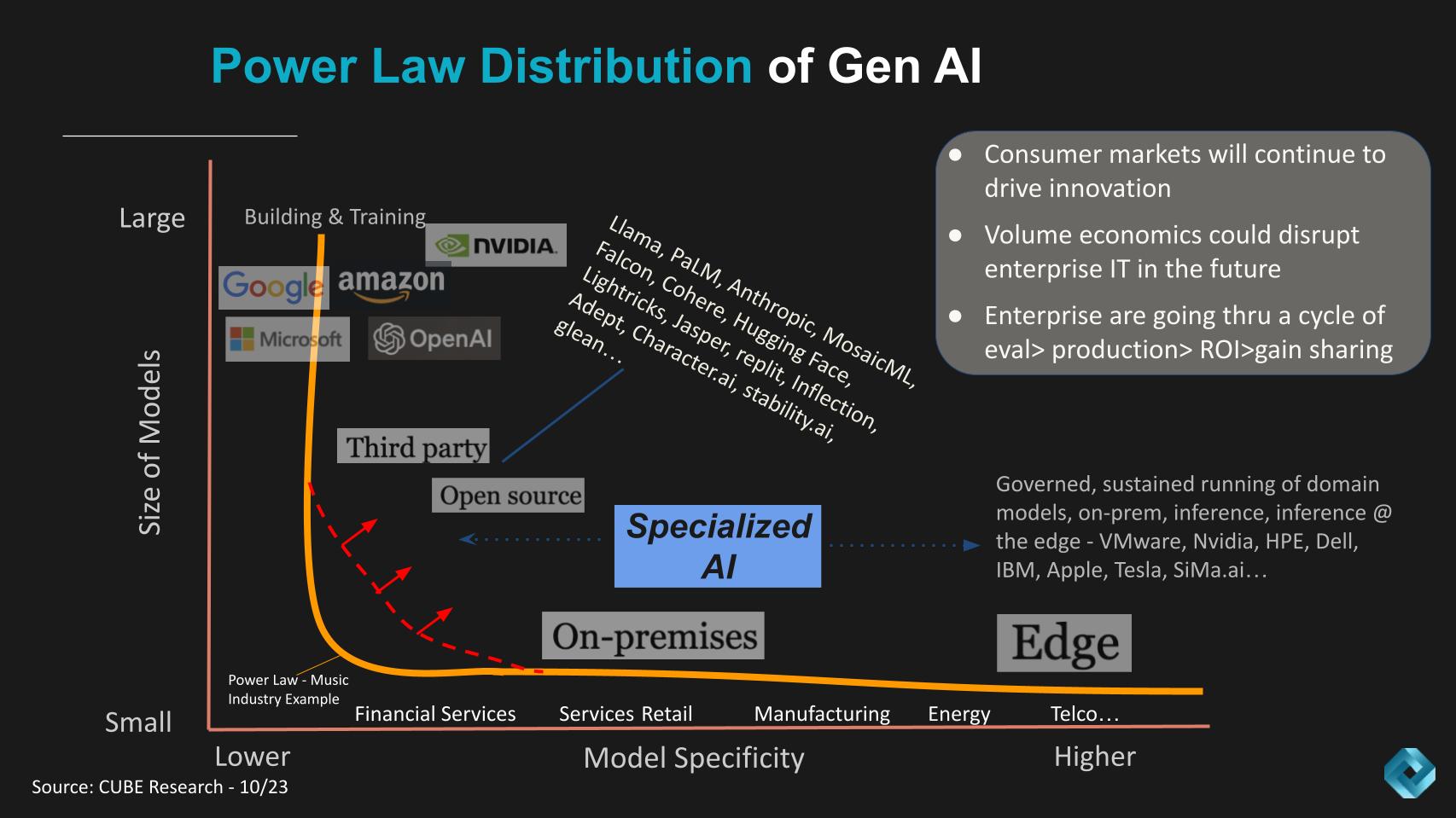
In the diagram above, the Y axis represents the size of the large language models and the X axis shows the domain specificity of the LLMs. The orange line shows an example of the historic music industry, where only about four labels dominated the record scene. And so the shape of the curve was a hard right angle.
In Gen AI we see a similar but somewhat different pattern in that:
The other points are shown in the gray box in the upper right. We believe that like many waves, the consumer adoption, in this case of ChatGPT, catalyzes innovation that bleeds into the enterprise. Our research shows that enterprises are currently going through a cycle of experimentation to production with very specific use cases. Most are still in the evaluation phase – possibly as high as 90% – but those in production that are successful are showing very fast ROI and sharing the gains to invest more. This is important because today, most gen AI is being funded by stealing from other enterprise IT budget buckets.
Coming back to the conversation on volume economics: This pattern of consumer adoption will, in our opinion, result in dramatic shifts to the economics of running workloads, which will eventually disrupt traditional data center and even possibly cloud economic norms.
We are particularly interested in the silicon wars taking place. To us, the Arm model is most compelling because of its maturity, time to market, power-per-watt advantage — but most importantly, the volume of Arm wafers as compared with any other standards. Arm wafer volumes are probably 10 times those of x86 and the performance curves coming out of the Arm ecosystem is progressing at a rate of 2.5 to three times that of historical Moore’s Law progressions.
It’s no coincidence that Apple got this all started with iPhone volumes and is TSMC’s biggest volume driver. It’s also is the No. 1 enabler of TSMC’s foundry leadership. But it’s not only iPhone. Apple laptops, Amazon Web Services’ Nitro, Graviton, Inferentia and Tranium, Google and Microsoft, Tesla, Oracle with Ampere and many others are driving this innovation. Oh yes – let’s not forget Nvidia. And the related cost implications are monumental in our view.
Arm is the low-cost architecture and we believe will remain so because of volume economics, tooling maturing and Wright’s Law.
We’re well aware that the entire industry is trying to find alternatives to Arm in the form of RISC-V open source standards and alternatives to Nvidia in GPUs. But the experience curves around Arm and Nvidia are years ahead of the pack in our view. The implication is we believe both Arm and Nvidia will maintain volume leads in their respective markets through the decade.
The reason we spend so much time thinking about this is we see the long tail of Gen AI and the massive volumes of embedded systems spawning new data consumption models that will radically alter the economics of enterprise information technology, in similar ways that x86 won the game against RISC back in the day.
Let’s review how IT decision makers think about which vendors they’re adopting today for gen AI and how they’re thinking about future partnerships.
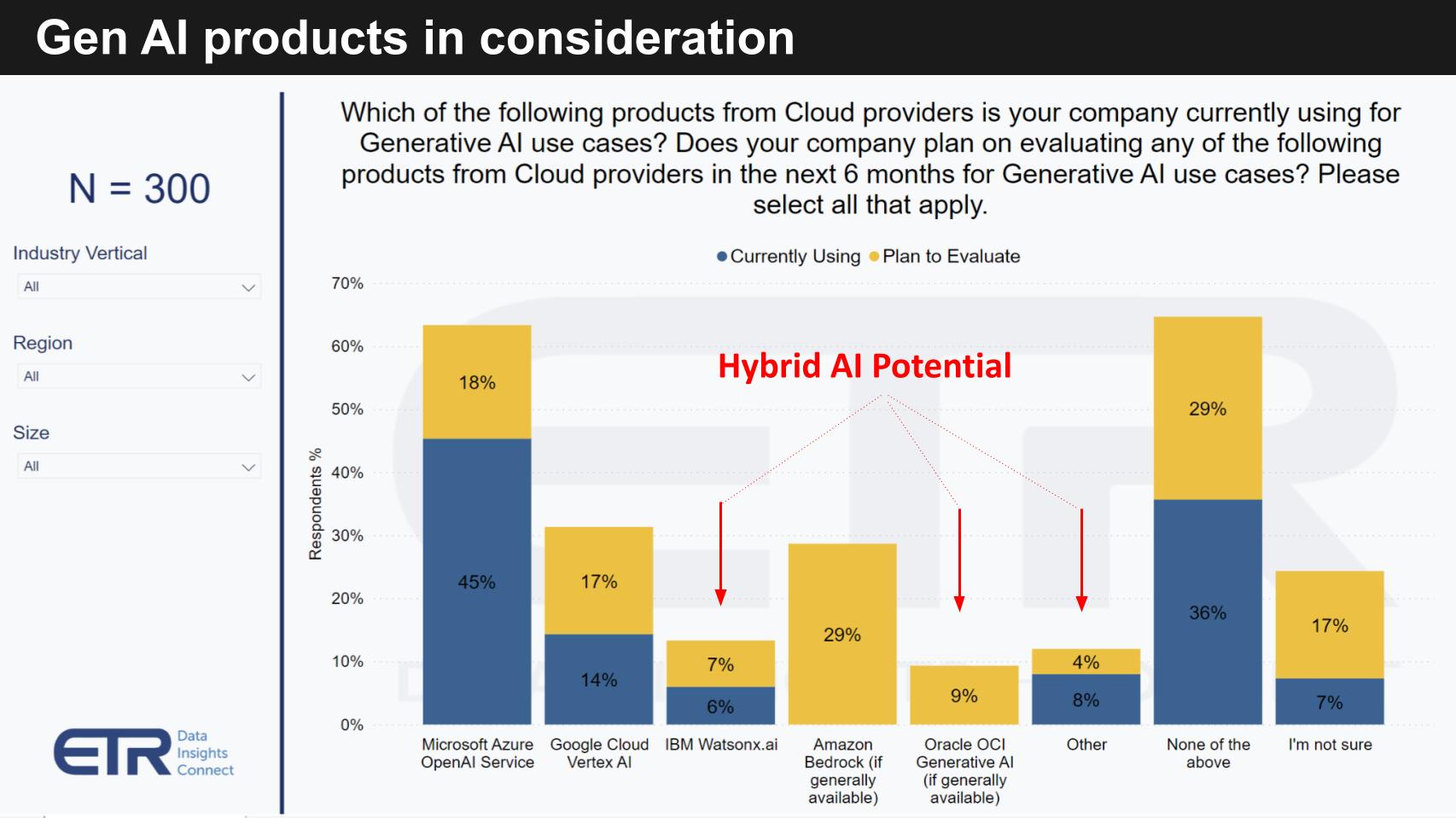
The data above is from a recent ETR drill-down. The survey asks customers which products are currently in use for gen AI and which are planned for eval. This is part of a cloud survey so it’s biased toward cloud vendors but that’s where the action is today for the most part. And you can see the dominance of OpenAI and Microsoft. Remember Microsoft said that gen AI provided a 300-basis point tailwind for Azure this past quarter and they are the only company to have expressed meaningful revenue from gen AI (other than Nvidia of course).
Microsoft guided that Azure saw a 300-basis point tailwind from AI this quarter which we equate to about $325 million. We see this figure approaching $500 million in the December quarter, implying a nearly $2 billion run rate for Azure AI.
In the chart you can see Google’s Vertex AI and Amazon in strong positions. AWS late last month announced Bedrock was in general availability, so we’ll likely see fast uptick there as we reported last week. We also focused on watsonx. In our view, IBM finally got it and the data is confirming a nice uptick in adoption interest for IBM Watson. Oracle as well is the other call-out on this chart as “other” players.
The new callout on this data is the impact of hybrid AI. The notion of bringing AI to the data. We think that occurs in the cloud, on-prem and at the edge. Because that’s where the data lives.
Data from ETR’s Emerging Technology Survey informs us as to how enterprises are investing or evaluating emerging tech. As you’re no doubt aware, there are many other players as we showed in the power law graphic. So let’s take a look at some of those lesser-known names that are worth noting.
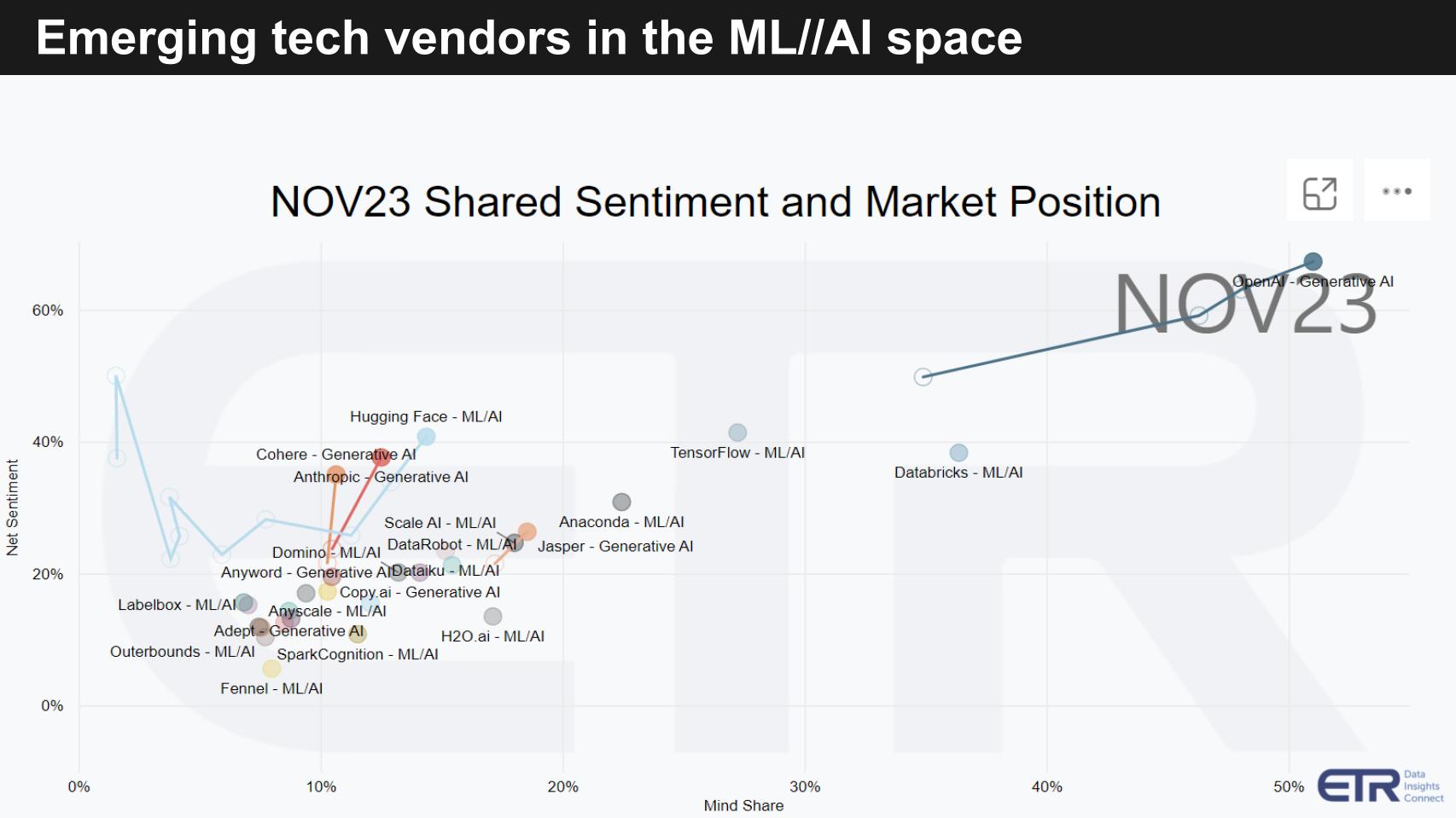
Above we show a chart from ETR’s ETS. It’s a relatively new addition to the mix that ETR’s new CEO decided to accelerate to multiple times per year. The ETS survey measures Net Sentiment on the vertical axis and Mind Share on the horizontal. The N responses are well over 1,000. This survey focuses only on privately held companies. Note that ETR will from time to time capture open-source tools such as TensorFlow shown above.
The vertical axis measures intent to engage and the horizontal measures awareness. And this is a mix of machine learning and AI tools, so it’s not just gen AI – there is other AI you know. We’d be happy to explain the methodology in more detail, so ping me us if you want more info on that.
What we want to really emphasize here is:
You can see the mix of other ML/AI players including the always prominent Databricks, which has a strong heritage in data science and machine learning.
The one major force that hasn’t shown up in the ETR data set just yet is Meta’s Llama2.
Meta introduced Llama early this year and in July announced Llama 2 in 7 billion-, 13 billion- and 70 billion-parameter versions. It’s an open-sourced LLM that Meta is deploying internally and is gaining traction as an alternative to OpenAI. For context, Google’s PaLM is said to be built around 500 billion parameters and ChatGPT is reportedly at 1 trillion or more. So Meta is showing with Llama 2 the massive potential of smaller language models.
The other really important thing we haven’t talked about is that one of the most significant barriers to gen AI adoption today is concerns over privacy, legal exposures and compliance. And so coming back to the Power Law of Gen AI, many companies want to deploy gen AI on-prem, where much of their sensitive data still lives. Think financial services, health care, regulated industries… and of course the edge.
There’s no hard data on this, but our conversations with various industry sources indicate that more than 50% of the Llama 2 deployments are possibly on-prem. At the very least, the majority of downloads are from companies that have significant data center deployments. So this fits squarely into our thinking on the long tail and the application of smaller models.
It’s very possible that over 50% of the Llama 2 deployments are on-premises in data centers and at the edge.
Now this doesn’t mean you won’t see smaller domain-specific models deployed in the cloud – you will. Absolutely. The point is it will be data location-dependent. The other caveat is the long tail will have camel humps along the curve (see below) where there will be organizations, particularly in high-performance computing and supercomputing applications, that use very large data sets, so keep that in mind when thinking about the shape of the curve.
There’s a major industry movement around retrieval-augmented generation. RAG dramatically simplifies and improves the deployment of gen AI. The problem with LLMs is they’re inconsistent and sometimes flaky – they hallucinate a lot – and often are unreliable and inconsistent. This is the result in large part of their wide scope of knowledge and data inputs and ability to get creative. So organizations are using RAG to address this.
RAG is an AI framework that improves the specificity of data used in LLMs. RAGs take the queries from users and vector in specific domain knowledge to complement the LLM, using a vector database like Pinecone or Milvus. The original user prompt is then augmented with a proprietary knowledge base, often complemented with other industry-specific data, and then sent to the foundation model, resulting in better responses.
This approach is more accurate, reduces hallucinations and provides domain specific value that generalized LLM models such as ChatGPT, in and of themselves, do not. RAGs give better control over the data used by the LLM when formulating a response.
Let’s take a look at an example of a RAG that I’m familiar with: theCUBEai.
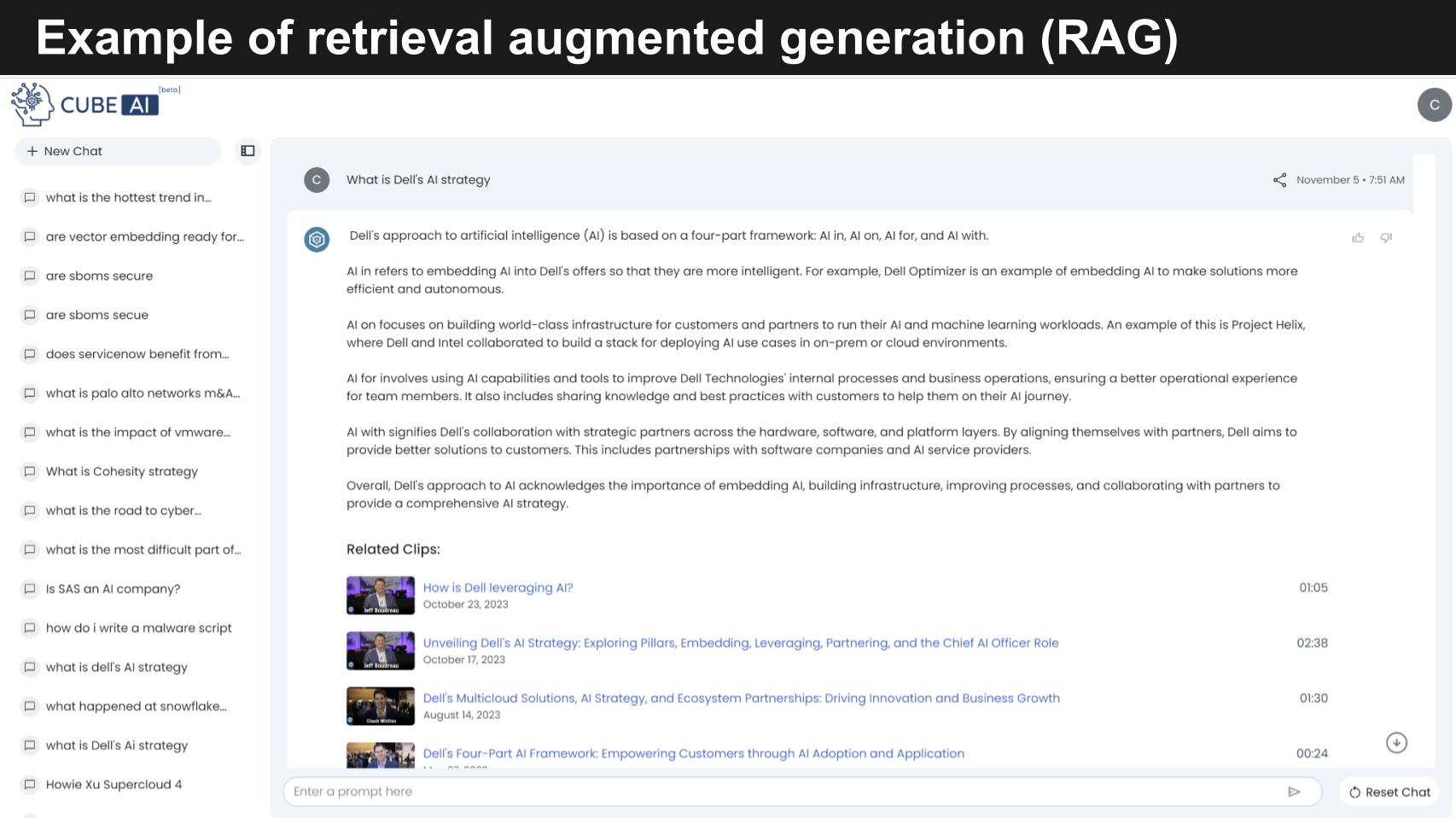
Our experience with theCUBEai a good example of a domain-specific model on the long tail of the Gen AI Power Law. We’ve ingested a corpus of about 35,000 videos from theCUBE and other data that we have. It allows our audience to ask very specific questions about companies, strategies and industry trends. It’s an AI-powered engagement platform that works as a virtual analyst to summarize video content extract and share key insights and provide AI assisted search.
In the example above, we ask theCUBE AI: “What is Dell’s AI strategy?”
It comes back with a very high-fidelity answer:
Dell’s approach to AI is based on a four-part framework: AI In, AI On, AI For and AI With.
‘In’ focuses on embedding AI into Dell’s offerings.
The AI ‘On’ aspect involves building infrastructure where customers and partners can run their AI and machine learning workloads. Project Helix.
The AI ‘For’ dimension has two prongs. Firstly, Dell applies AI capabilities and tools to improve their internal processes and secondly, Dell shares their knowledge and best practices with customers to support their AI journey.
Then AI ‘With’ focuses on enabling ecosystem partnerships
And the AI gives us relevant clips… which, by the way, were made by theCUBE AI.
Now there are a lot of learnings here. One is relevant to the conversation about AI taking jobs. To share a job loss story, theCUBE AI has eliminated at least one job. We used to have a human make clips manually, but AI now does that with a push of a button. We can control the length of clips, the context and the quality, and more. Now the person the AI replaced is not unhappy because that individual was like an air traffic controller staring at videos all day long with tired eyes.
So the jobs elimination thing is a two-edged sword. Like robotic process automation deployments, much of the AI will be replacing mundane tasks. Longer-term, it could have greater impacts on employment, no doubt, but we’ll leave that for another day.
The key to RAG specifically and LLMs generally is the quality of the data.
Because we have current data on Dell in our corpus, theCUBE AI’s answer is pristine. But below is an example that’s not as great. We asked theCUBE ai “Who is the CEO of ServiceNow?”
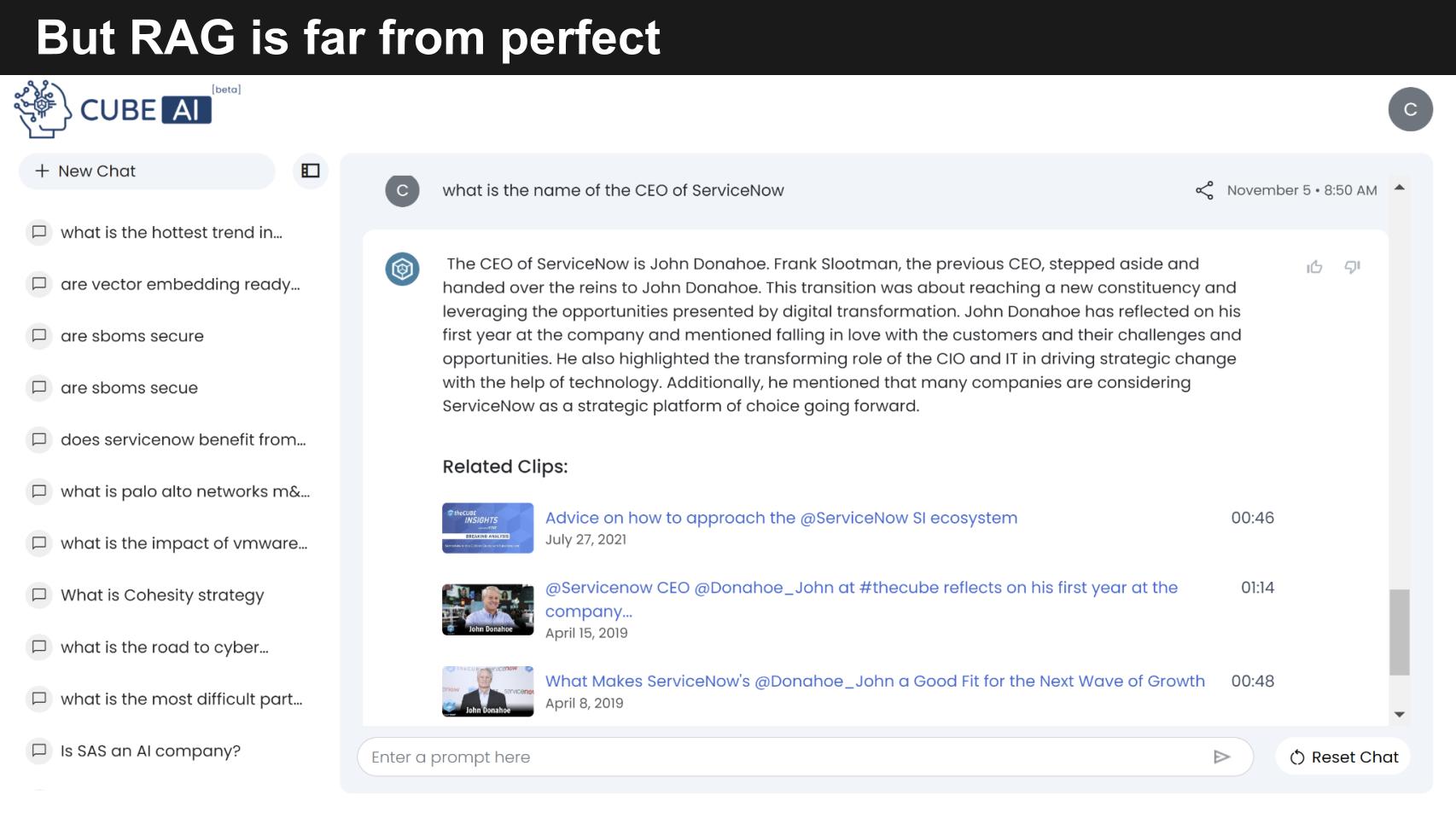
And the gives us back John Donahoe, a CUBE alum and former CEO. And it references Frank Slootman, the previous CEO. Now even though we’ve talked a fair amount about Bill McDermott, the new CEO, the AI couldn’t connect the dots; the data in the corpus just wasn’t current enough. So the engineers were notified with a thumbs down and a comment and they’ll train the system to key off the dates and put in a caveat in the answer that this is as of a certain date. Or possibly figure out a way to search other data in the corpus and actually connect the dots. We’ll see…
The point again is the currency and quality of data will determine the relevance and usefulness of the results.
PLEASE SIGN UP FOR THECUBE AI AND HELP US IMPROVE ITS UTILITY TO THE COMMUNITY!
So you won’t be surprised by this ETR survey data below asking customers where their focus is on gen AI data and analytics priorities related to gen AI.
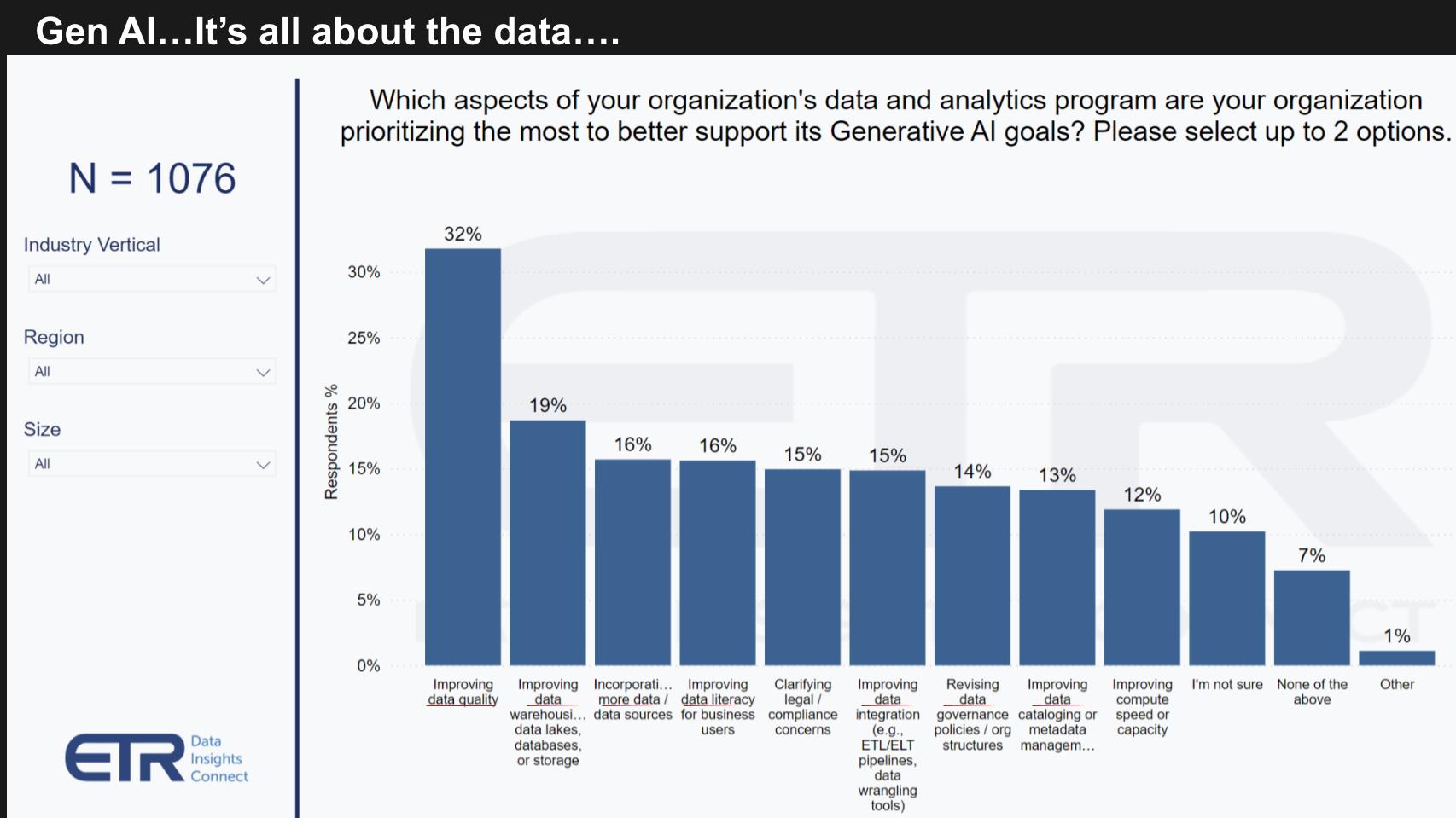
Just scan the categories above… improving data quality, improving data warehouses and data lakes and storage data, incorporating more data, improving data literacy, better data integration, revising data governance policies, improving data cataloging, better metadata management.
Again, it’s all about the data. A lot of data lives in the cloud. There’s tons of data on-prem – probably as much if not more than is in the cloud. And there’s more and more data at the edge. The phrase “it’s all about the data” means bringing AI to the data, improving the quality of data, and putting the right data governance models in place.
Data will be the key to differentiator in AI for those who act.
Let’s close with some final thoughts and expectations on gen AI adoption.

AI everywhere: It’s coming from the top down, bottom up, middle out. The organizational momentum underscores how AI is being adopted. Upper managements are pushing technology and business departments to drive AI into the system to improve productivity. There’s lots of “shadow AI” bubbling from the decentralized bottom layer of organizations and middle management wants to drive AI into their business units to improve.
Funding AI. Most organizations are still in evaluation phase, but those in production are showing return on investment and “gain sharing” where value is clear and it’s paying for itself.
Unfunded mandate. Gain sharing is an important concept for practitioners because AI budgets are still largely dilutive to other initiatives – that is, organizations are robbing funds from other sectors to pay for AI.
Pressing the leaders. The industry is scrambling for Nvidia alternatives (AMD, Intel and the like) and open-source options to Arm. But those two have a significant lead on the market (Nvidia in GPU and Arm in embedded with AI inferencing at the edge).
Better to be on the lead. It may be early, but tactical position matters in this race. Early innovators are gaining valuable feedback, rapidly improving data quality, learning how best to protect data, and figuring out the monetization models.
Admittedly that is a two-edged sword. The pioneers could take some arrows. But the momentum is so strong that we’d rather be on the lead in this horse race than starting from the back of the pack getting dirt kicked in our faces.
Thanks to Alex Myerson and Ken Shifman on production, podcasts and media workflows for Breaking Analysis. Special thanks to Kristen Martin and Cheryl Knight, who help us keep our community informed and get the word out, and to Rob Hof, our EiC at SiliconANGLE.
Remember we publish each week on Wikibon and SiliconANGLE. These episodes are all available as podcasts wherever you listen.
Email david.vellante@siliconangle.com, DM @dvellante on Twitter and comment on our LinkedIn posts.
Also, check out this ETR Tutorial we created, which explains the spending methodology in more detail. Note: ETR is a separate company from Wikibon and SiliconANGLE. If you would like to cite or republish any of the company’s data, or inquire about its services, please contact ETR at legal@etr.ai.
Here’s the full video analysis:
All statements made regarding companies or securities are strictly beliefs, points of view and opinions held by SiliconANGLE Media, Enterprise Technology Research, other guests on theCUBE and guest writers. Such statements are not recommendations by these individuals to buy, sell or hold any security. The content presented does not constitute investment advice and should not be used as the basis for any investment decision. You and only you are responsible for your investment decisions.
Disclosure: Many of the companies cited in Breaking Analysis are sponsors of theCUBE and/or clients of Wikibon. None of these firms or other companies have any editorial control over or advanced viewing of what’s published in Breaking Analysis.
THANK YOU





