



Data Science in Mental Health: How We Integrated Dunn’s Model of Wellness in Mental Health Diagnosis Through Social Media Data
Author(s): MSVPJ Sathvik
Originally published on Towards AI.
The World Health Organization suggests that about one in four people in today’s world experience mental health conditions at some point in their lives, which are not only confined to emotional well-being but also physical, social, and cognitive abilities.
In our work on medical diagnosis, we have focused on identifying conditions such as depression and anxiety for suicide risk detection using large language models (LLMs). Our previous approach considered additional factors associated with mental illnesses, such as Perceived Burdensomeness (PBu) and Thwarted Belongingness (TBe).
But later on, we realized that the overall parameters of a person’s well-being would provide a broader view, which can be critical for early detection and medication rather than just focusing on a diagnosis, like particular mental health issues.
For this, we have worked on the MULTIWD dataset that identifies the wellness indicators in social media posts.
We crafted it to support a multi-dimensional analysis beyond the traditional categories determining mental health issues. Our MULTIWD dataset has been a fantastic resource in helping detect multiple wellness dimensions in Reddit posts. This dataset represents a valuable tool for mental health research, letting researchers perform fine-detailed multi-label classification tasks for analyzing mental well-being in real-world social media contexts.
What are wellness dimensions?
Considering its structure, we have taken Halbert L. Dunn’s wellness model as a base for our MULTIWD dataset.
Dunn’s model categorizes wellness into six dimensions:
- Physical: Often impacted by lifestyle and medical conditions related to one’s body
- Emotional: Emotional stability, resilience, and mental strength
- Social: Social interactions, relationships, and social networks
- Intellectual: Creative thinking, Active learning, and cognitive abilities
- Spiritual: Meaning to one’s life, the purpose of the soul
- Occupational(Vocational): Work-life balance, job satisfaction
Focusing on Reddit posts, the MULTIWD dataset annotates these posts with the above wellness dimensions, providing greater scope for analysis of mental health issues.
The MULTIWD Dataset: Structure and Purpose
How did we collect the data?
We have collected data from two particular subreddits: /depression and /SuicideWatch, where a lot of people around the world put their hearts out, pouring out their personal experiences on mental health problems that they’ve been facing, all anonymously.
Going anonymous for self-expression has bundled these forums with information that is quite useful for mental health studies.
We have carefully curated 3,200 posts out of thousands collected over two months.
How did we build our model on the base of Dunn’s model?
Labeling the wellness dimensions requires a clear understanding of social and psychological factors; we have invited an expert panel, including a clinical psychologist, rehabilitation counselor, and social NLP researcher. This panel has designed the guidelines for annotating the wellness dimensions and categorized the posts into the six wellness dimensions based on the sensitive content of each post. They have established clear criteria with many examples and allowed their well-trained student annotators to classify each post meticulously.
What does the dataset provide?
In conclusion, it has been observed that the posts in the dataset ranged from brief messages to detailed personal anecdotes with a maximum post length of 300 words. A clear distinction of imbalance has been made among the six dimensions, with the higher representation of the Social, Emotional, and physical aspects. We summed up from this that the skew indicates that the users often share more information about their social connections, physical health issues, and emotions than their vocational and spiritual experiences on these forums.

Data Analysis Techniques in MULTIWD
We have used machine learning and data science techniques to explore the wellness dimensions in rich and unstructured crude text.
The techniques we used for in-depth analysis were:
- Multi-Label Classification
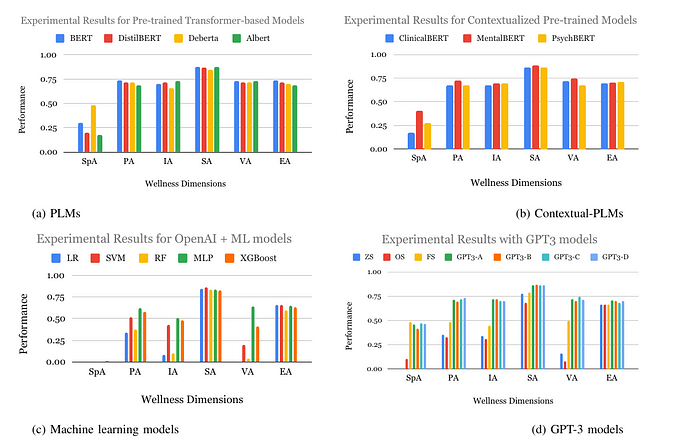
The first step to proceed with our MULTIWD was Multi-Label Classification. Each Reddit post can relate to multiple wellness dimensions, which made it essential to use models that can assign various labels. After a detailed evaluation of traditional classifiers and transformer-based models like BERT and GPT-3, MentalBERT and BERT became the best-performing models, achieving a fantastic F1 score of over 76%. This indicates that they can accurately portray the complexity of multiple dimensions in social media language.
- Handling Imbalanced Data
To address the class imbalance in our MULTIWD dataset, with notably fewer instances for Spiritual and Vocational aspects, we have used data augmentation techniques that can help generate synthetic data for the classes on a different level than others. This would help balance the training set and improve the model’s performance.
Additionally, we have used specialized evaluation metrics such as the Matthews Correlation Coefficient (MCC) to gauge the model’s performance beyond accuracy, providing an improved measure that accounts for false positives and negatives.
- Semantic and Contextual Analysis
We found dealing with semantics, vocabulary, and context quite challenging since social media posts contain ambiguous language, metaphors, or slang, complicating analysis. Per se, the word “head” can refer to either physical pain or mental distress, depending on context. We realized we’d need advanced natural language understanding and attention mechanisms to differentiate the meanings. Using BERT and MentalBERT, we could capture these subtleties effectively by contextualizing each word based on the surrounding text. This helped us make it well-suited for the intricacies of wellness dimension identification.
Practical Implications of the MULTIWD Dataset
The MULTIWD dataset presents many applications for monitoring mental health, longitudinal studies, and interventions. Further, researchers have a great scope to identify individual mental health trends by analyzing wellness dimensions over time, providing good insights into social-emotional and physical factors contributing to one’s mental well-being.
Expanding this dataset, we have observed some suitable applications:
- Early mental health crisis detection: The posts indicating significant signs and changes in the emotional and social well-being of individuals who are clearly at risk of mental health issues serve as early warning signs, allowing for timely interventions.
- Longitudinal Analysis: This dataset is entirely compatible with studies that assess wellness changes over time. Researchers can develop models that track well-being patterns by mapping the dimensions to different users’ previous posts. This would greatly support the mental health practitioners who are monitoring at-risk individuals.
- Informing Public Health Initiatives: If a specific wellness dimension is persistently associated with high distress and anxiety, targeted initiatives can address these issues. Analysis of this dataset can also guide the design of the policies that might highlight common mental health issues the users face.
Conclusion: The pathway to draw better insights from mental health data using data science
The MULTIWD dataset has significantly contributed to mental health research and still has a broad scope for application in the same field. By shifting the focus from individual diseases or disorders, blending the wellness dimension parameters into this helped us and other researchers to analyze the social media data to reflect the complexities of mental well-being. On taking this forward by refining the dataset, adding more balanced wellness dimensions can yield better insights into how wellness changes over time and how data science and analysis can contribute to meaningful mental health diagnosis.
Citation: MSVPJ SATHVIK , Muskan Garg . MULTIWD: Multiple Wellness Dimensions in Social Media Posts. TechRxiv. May 17, 2023.
Image source: Images generated by DALL-E based on the given prompts, also adapted from MSVPJ SATHVIK, Muskan Garg. MULTIWD: Multiple Wellness Dimensions in Social Media Posts. TechRxiv. May 17, 2023.
DOI: 10.36227/techrxiv.22816586.v1
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



