Text Classification Using Machine Learning Algorithm in R

Introduction
Text classification, which involves categorizing text into specified groups based on its content, is an important natural language processing (NLP) task. Text categorization is supported by a number of programming languages, including R, Python, and Weka, but the main focus of this article will be text classification with R.
R is a popular open-source programming language used for statistical computation and data analysis, as well as for text classification tasks such as basic spam detection, sentiment analysis, and topic labeling. It also provides a wide range of packages and features designed specifically for NLP and text classification. This article will look at how R can be used to execute text categorization tasks efficiently.
Text Categorization
Text categorization is a machine-learning approach that divides the text into specific categories based on its content. The goal is to automatically classify documents based on the textual information contained within them. Text classification is heavily used in a variety of applications, including spam detection, sentiment analysis, and topic labeling. After being trained on a large corpus of data with predefined categories, the model learns to predict the appropriate category based on the text content. Some of the techniques that can be used to improve the accuracy of the text classification model are feature selection, feature engineering, and ensemble approaches.
R Language

R, a popular open-source programming language, is used for statistical computation and data analysis. It has a large number of NLP and text categorization packages, including the tm and caret packages. R’s ability to handle large volumes of text data, ease of data pre-processing, and visualization abilities are among its text categorization strengths. You can read more about the R language here.
Using R for text classification
We will explore text classification using the R language and its relevant packages. Our focus will be on three specific tasks: topic labeling, sentiment analysis, and simple spam detection.
Topic labeling in R
Topic modeling is a text analysis technique that helps identify the main topics discussed in a large corpus of text data. It is a form of unsupervised learning that identifies patterns in the text data, grouping similar words into topics, and then categorizes each document based on the topics it contains.
One of the most commonly used packages in R for topic modeling is the topicmodels package. This package provides functions for fitting topic models, such as Latent Dirichlet Allocation (LDA), and it also provides methods for visualizing and interpreting the results. You can read about the package here.
#Install the topicmodels package as we would require it our task
install.packages("topicmodels")The tidytext package uses the tidy data framework to analyze text. It provides tools for processing and transforming text data into a tidy format, making standard data analysis techniques more accessible. Because of the package’s emphasis on tidy data, it is both a user-friendly option for those new to text analysis, and a valuable tool for experienced practitioners. You can learn more about the usage of the package here
install.packages("tidytext")Application areas for topic modeling are numerous. Data mining, text classification, and information retrieval are just a few applications. To extract themes from a corpus of text data and then use these themes as features in text classification algorithms, topic modeling can be used in text classification.
It is simpler to find pertinent content when related documents are grouped together according to their themes using topic modeling in information retrieval. Data mining techniques like topic modeling can be used to find patterns and relationships in large datasets, facilitating the discovery of undiscovered knowledge and insights.
Copy the text below into a basic text editor like Notepad and save it as a csv file:
"Title","Text"
"Climate Change Effects on Agriculture","As global temperatures rise, farmers are facing new challenges in producing crops. Drought, heatwaves, and unpredictable weather patterns are making it harder for crops to grow, and soil degradation is becoming a major issue. Climate change is also leading to more pests and diseases, which can cause further damage to crops. To adapt to these changing conditions, farmers must adopt new practices, such as using drought-resistant crops, better irrigation systems, and more sustainable farming methods. It's important for governments and organizations to support farmers in this transition, as a food-secure future depends on it."
"The Benefits of Plant-Based Diets","A growing body of research shows that plant-based diets are good for both human health and the environment. People who follow a plant-based diet are less likely to develop heart disease, type 2 diabetes, and some forms of cancer. Additionally, plant-based diets have a lower carbon footprint than diets that rely on animal products, as producing plant-based foods requires fewer resources and produces less greenhouse gas emissions. If more people adopt plant-based diets, we can help reduce the impact of climate change while improving public health."
"The Rise of Renewable Energy","Renewable energy is becoming more prevalent as a source of power, and it's easy to see why. Not only is it better for the environment, as it produces less greenhouse gas emissions, but it's also becoming more cost-competitive with traditional fossil fuels. Advances in technology have made it possible for wind and solar power to be produced on a large scale, and many countries have set ambitious targets to transition to 100% renewable energy. The rise of renewable energy is a promising development, and it's essential for the future of the planet."
"The Importance of Biodiversity Conservation","Biodiversity refers to the variety of life on Earth, and it's essential for our survival. A loss of biodiversity can lead to ecosystem collapse, which can have serious consequences for humans and other species. Conservation efforts aim to protect biodiversity by preserving natural habitats and preventing the extinction of species. It's important for governments and individuals to take action to protect biodiversity, as it provides important ecosystem services, such as pollination and nutrient cycling, which are essential for life on Earth."
"Artificial Intelligence and Society","Artificial intelligence is changing the world as we know it, and its impact on society is complex as most individuals have different views."# Load the packages
library(tidytext)
library(topicmodels)
# Load the data saved as a csv
data <- read.csv("topic_data.csv")
# Pre-process the data by converting to a tidy format and removing stop words
topic_tidy <- data %>%
unnest_tokens(word, Text) %>%
anti_join(stop_words)
# Generate term-document matrix
tdm <- topic_tidy %>%
count(Title, word) %>%
cast_tdm(Title, word, n)
# Establish the number of topics to model
num_topics <- 5
# Perform Latent Dirichlet Allocation (LDA) topic modeling
set.seed(123)
model <- LDA(tdm, k = num_topics)
# View the five topic top terms
terms(model,5)
# Extract the topic-word probabilities
topic_word_probs <- as.matrix(terms(model,5))
# Create a data frame of the topic-word probabilities
topic_word_probs_df <- as.data.frame(topic_word_probs)
# Write the topic-word probabilities to a CSV file
write.csv(topic_word_probs_df, file = "topic_word_probs.csv")#The result generated would be something like thiis
terms(model,5)
Topic 1 Topic 2 Topic 3 Topic 4 Topic 5
[1,] "artificial" "energy" "crops" "biodiversity" "based"
[2,] "changing" "renewable" "farmers" "earth" "plant"
[3,] "complex" "power" "drought" "ecosystem" "diets"
[4,] "impact" "future" "changing" "essential" "health"
[5,] "individuals" "rise" "adapt" "life" "people"
The topicmodels package’s terms() function returns the top terms (words) associated with each topic in the LDA model. The model identified 5 topics in the example you provided, and the top 5 terms associated with each topic are shown.
The first topic, for example, is about “artificial” things, the second about “energy” and “renewable” sources, the third about “crops” and “farmers,” the fourth is about “biodiversity” and “ecosystem,” and the fifth about “based” and “plant.”
Curious to see how Comet works? Check out our PetCam scenario to see MLOps in action.
Sentiment analysis in R
Sentiment analysis is an NLP activity that involves categorizing and determining whether a text contains positive, negative, or neutral opinions or feelings (known as “sentiments”). The activities help you understand a writer’s attitude or position on the subject at hand.
R is a popular language for sentiment analysis because it has several packages that allow for it, such as the “sentimentR” package. The language also includes a diverse set of data preprocessing resources that enable effective analysis. The “tm” package is a text mining package that makes it simple to preprocess text for NLP tasks.
#install the sentimentR package
install.packages("sentimentr")You would also need to install the dplyr package. This package is very powerful as it allows you to carry out most the data manipulation tasks in R. Read more about the package for grammar data manipulation here
# The easiest way to get dplyr is to install the whole tidyverse:
install.packages("tidyverse")Sentiment analysis has numerous real-world applications. In business analysis, it is used to track customers’ views and opinions on a product’s features, price, new designs or modifications, and brand reputation. It is used in political analysis to ascertain public opinion on a political issue or candidate. Sentiment analysis can help businesses and organizations make better decisions by providing valuable insights into people’s perspectives and beliefs.
Copy the text below into a basic text editor like Notepad and save it as a csv file:
id,review,
1,"This hotel was fantastic, The staff was friendly and the room was clean and comfortable.",
2,"I had a terrible experience at this hotel, The room was dirty and the staff was unprofessional.",
3,The location of this hotel was great but the room was outdated and in need of some upgrades.,
4,"I had a mixed experience at this hotel, The staff was friendly but the room was noisy and small.",
5,"I was pleasantly surprised by this hotel, The room was spacious and the staff was helpful.",# Load the necessary packages
library(sentimentr)
library(dplyr)
# Generate simple hotel review data
reviews <- read.csv("review.csv")
# Create a data frame with the reviews
reviews_df <- data.frame(reviews)
# Perform sentiment analysis on the reviews
sentiment(reviews_df$review)
reviews_df$sentiment <- sentiment(reviews_df$review)
# Show the sentiment analysis results
reviews_df %>%
mutate(sentiment = ifelse(sentiment$sentiment > 0, "Positive", "Negative")) %>%
group_by(sentiment) %>%
summarise(count = n())
#The code above shows a summary of the count of positive and negative sentiments
# Create a new variable to the dataframe that shows positive and negative sentiments
reviews_df$sentimentresult <- ifelse(reviews_df$sentiment$sentiment > 0, "Positive", "Negative")
reviews_df$sentimentresult
# Plot the sentiment analysis results
ggplot(reviews_df, aes(review, sentimentresult)) +
geom_col(aes(fill = sentiment$sentiment > 0), show.legend = FALSE) +
coord_flip() +
labs(x = NULL, y = "Sentiment", title = "Sentiment Analysis of Sentiments Dataset in R") +
scale_fill_manual(values = c("red", "green"))The results of the code:
# The sentiment function results as:
sentiment(reviews_df$review)
element_id sentence_id word_count sentiment
1: 1 1 15 0.7100469
2: 2 1 17 -0.6063391
3: 3 1 18 -0.5302122
4: 4 1 19 -0.3869670
5: 5 1 16 0.5125000
# The sentences with sentiments <0 are negative meaning the review was poor
# To view the count of positive and negative sentiments
reviews_df %>%
+ mutate(sentiment = ifelse(sentiment$sentiment > 0, "Positive", "Negative")) %>%
+ group_by(sentiment) %>%
+ summarise(count = n())
# A tibble: 2 × 2
sentiment count
<chr> <int>
1 Negative 3
2 Positive 2
# The reviews analysed have 3 negative reviews and 2 positive reviews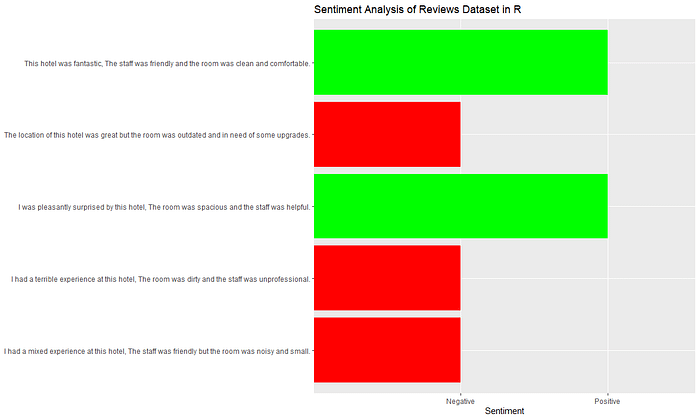
Spam message detection in R
Spam detection is the process of identifying messages that are suspicious or contain malicious content and filtering them out of a user’s direct message box. It prevents individuals from being victims of phishing scams, malware, and other forms of malicious content.
R has a rich set of libraries and tools for machine learning and natural language processing, making it well-suited for spam detection tasks. R can be used to build models for spam classification based on various features such as message header information, sender reputation, and text content analysis.
The e1071 package provides a suite of statistical classification functions, including support vector machines (SVMs), which are commonly used for spam detection. We will be utilizing the “Naive Bayes” model for our classification training.
Naive Bayes, according to Nagesh Singh Chauhan in KDnuggets, is a straightforward machine learning technique that uses Bayes’ theorem to create predictions. The Bayes theorem states that the prior probability of the hypothesis and the likelihood of the evidence given the hypothesis can be used to determine the probability of a hypothesis (such as a forecast) given certain observed evidence.
The method generates predictions by calculating the posterior probabilities of each class label given the input features and selecting the label with the highest probability as the forecast.
Naive Bayes is commonly used for spam classification. The goal of this work is to predict whether a given email, which serves as input data, is spam or not. Based on the words in the email as characteristics, the algorithm determines the likelihood of each class (spam or non-spam). The email is then classified as spam or not spam based on the class with the highest probability.
The caret package is a comprehensive R package for developing and evaluating machine learning models. It includes training and testing functions for classifiers, including those used for spam detection.
A single interface for kernel-based learning algorithms is offered by Kernlab.
We’d be utilizing the kernel package’s spam dataset. An assortment of emails that have been labeled as “spam” or “not spam” are included in this dataset. This dataset will be used to train a machine learning model that will determine based on the content of a new email whether it is spam or not.
The Spam dataset:
Source
• Creators: Mark Hopkins, Erik Reeber, George Forman, Jaap Suermondt at Hewlett-Packard Labs, 1501 Page Mill Rd., Palo Alto, CA 94304
• Donor: George Forman (gforman at nospam hpl.hp.com) 650–857–7835 These data have been taken from the UCI Repository Of Machine Learning Databases at http: //www.ics.uci.edu/~mlearn/MLRepository.html
# Load the spam dataset from the kernlab library
library(kernlab)
data("spam")
# Split the data into training and test sets
set.seed(123)
trainIndex <- sample(1:nrow(spam), 0.75 * nrow(spam))
trainData <- spam[trainIndex, ]
testData <- spam[-trainIndex, ]
# Convert the email text into a matrix of word frequencies
library(tm)
corpus <- Corpus(VectorSource(trainData$text))
corpus <- tm_map(corpus, tolower)
corpus <- tm_map(corpus, removePunctuation)
corpus <- tm_map(corpus, removeNumbers)
corpus <- tm_map(corpus, removeWords, stopwords("english"))
dtm <- DocumentTermMatrix(corpus)
# Train a Naive Bayes classifier on the training data
model <- naiveBayes(x = trainData[, -58], y = trainData$type)
# Use the trained model to predict the class labels for the test data
predictions <- predict(model, testData[, -58])
# Evaluate the accuracy of the predictions
accuracy <- mean(predictions == testData$type)
cat("Accuracy:", accuracy)Finally, text classification is an important task in NLP because it divides text data into pre-defined groups based on its content. The R programming language is widely used for text classification, and it includes a number of packages and features designed specifically for NLP tasks such as spam detection, sentiment analysis, and topic labeling. Text classification is also supported by other programming languages such as Python and Weka. Techniques such as feature selection, feature engineering, and ensemble methods can be used to improve the accuracy of text classification. Text classification results can be used in a variety of applications such as data mining, information retrieval, and sentiment analysis, making it a valuable tool for gaining insights and knowledge from large amounts of text data.
References
- Nagesh, Singh Chauhan. “Naïve Bayes Algorithm: Everything You Need to Know”, KDnuggets
- Julianhi. “Build a SPAM filter with R”, Rbloggers
- Finnstats. “Sentiment analysis in R”, Rbloggers
- Shashank, Gupta. “Sentiment Analysis: Concept, Analysis and Applications”, Towards Data Science
Thanks for taking the time to read my blog ❤️! You can reach out to me on LinkedIn.
If you have any thoughts on the topic, please share them in the comments; I’m always looking to learn more and improve.
If this post was helpful, please click the clap 👏 button below a few times to show your support for the author 👇
Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for data science, machine learning, and deep learning practitioners. We’re committed to supporting and inspiring developers and engineers from all walks of life.
Editorially independent, Heartbeat is sponsored and published by Comet, an MLOps platform that enables data scientists & ML teams to track, compare, explain, & optimize their experiments. We pay our contributors, and we don’t sell ads.
If you’d like to contribute, head on over to our call for contributors. You can also sign up to receive our weekly newsletter (Deep Learning Weekly), check out the Comet blog, join us on Slack, and follow Comet on Twitter and LinkedIn for resources, events, and much more that will help you build better ML models, faster.

