
Discover the power of Python libraries for (partial) automation of Exploratory Data Analysis (EDA). Pandas Profiling and SweetViz stand out, simplifying tasks like summary statistics, visualizations, and pattern identification. These tools empower both seasoned Data Scientists and beginners to explore datasets efficiently, extracting meaningful insights without the usual time constraints.
Elevate your data exploration game with these intuitive libraries, optimizing your workflow and transforming the way you interact with data.
Powerful Python Libraries to (Partially) Automate EDA
Exploratory data analysis (EDA) stands as a cornerstone of the data science domain. It offers insights that pave the way for informed decision-making. As we navigate through the realm of EDA, leveraging Python libraries can significantly enhance efficiency. This article delves into the Python libraries that not only streamline but elevate the EDA process, giving you a competitive edge in the data-driven domain.
What are auto EDA libraires?
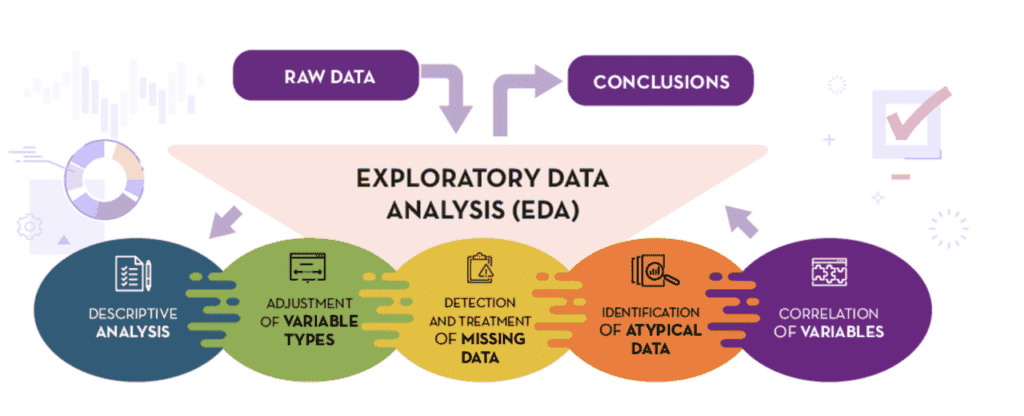
Auto EDA (Exploratory Data Analysis) libraries refer to a set of tools in the Python programming language designed to automate and streamline the process of exploring and understanding datasets. These libraries are created to simplify the often time-consuming tasks involved in data analysis, allowing data professionals to gain insights quickly and efficiently.
Auto EDA libraries typically offer functionalities such as generating summary statistics, detecting missing values, identifying outliers, and creating visualizations to highlight patterns in the data.
Two popular examples of Auto EDA libraries are Pandas Profiling and SweetViz. Pandas Profiling, for instance, can generate detailed reports that cover various aspects of a dataset, providing a comprehensive overview with minimal coding effort.
SweetViz specializes in creating visualizations that make it easier to interpret complex patterns within the data, offering a valuable tool for data exploration.
The essence of Auto EDA libraries lies in their ability to automate mundane aspects of data analysis, making it more accessible to a wider audience, from seasoned data scientists to beginners.
By leveraging these libraries, users can focus on deriving meaningful insights from their data, ultimately enhancing the efficiency and effectiveness of the entire data exploration process.
Best Python EDA libraries
 Pandas: The Backbone of Data Manipulation
Pandas: The Backbone of Data Manipulation
Pandas often hailed as the Swiss Army knife of data manipulation, is an essential library for any data scientist. With its powerful data structures, such as DataFrames, Pandas facilitates seamless data manipulation and exploration. Whether it’s cleaning messy data or aggregating information, Pandas is the go-to tool that transforms raw data into actionable insights.
Matplotlib and Seaborn: Crafting Visual Narratives
In the era of data storytelling, visualization plays a pivotal role. Matplotlib and Seaborn emerge as a dynamic duo, empowering you to create compelling visualizations with ease. Matplotlib provides a robust foundation for crafting a wide array of plots, while Seaborn adds an extra layer of sophistication with its aesthetic appeal. Together, they transform your data into visually engaging stories, making complex trends accessible at a glance.
Plotly: Interactive Visualizations for the Win
For those seeking an interactive twist to their visualizations, Plotly takes center stage. With its interactive capabilities, Plotly allows users to delve deeper into data points, enhancing the user experience. Whether it’s creating interactive dashboards or exploring intricate details in plots, Plotly adds a layer of engagement that traditional static visuals may lack.
NumPy: The Powerhouse of Numerical Computing
When it comes to numerical operations and mathematical computations, NumPy emerges as the powerhouse. Its array-oriented computing capabilities make it an indispensable library for handling large datasets with efficiency. NumPy’s array operations, combined with its mathematical functions, lay a solid foundation for numerical exploration in EDA.
Scikit-Learn: Streamlining Machine Learning Integration
In the age of machine learning, the intersection of EDA and predictive modeling is inevitable. Scikit-Learn stands as a bridge between these domains, offering a plethora of tools for machine learning integration. From data preprocessing to model evaluation, Scikit-Learn provides a cohesive environment that seamlessly integrates with your EDA workflow.
Streamlining Workflow with Dask
As datasets grow in complexity and size, the need for scalable computing becomes apparent. Dask addresses this challenge by enabling parallel computing for advanced analytics. Whether it’s distributed computing or handling larger-than-memory datasets, Dask empowers data scientists to scale their EDA efforts without compromising on performance.
Conclusion:
Elevating Your EDA Game
In the dynamic realm of data exploration, leveraging the right Python libraries can be a game-changer. From the foundational data manipulation capabilities of Pandas to the interactive prowess of Plotly, each library plays a unique role in enhancing the efficiency and depth of your EDA.
As you embark on your data exploration journey, remember that mastering these Python libraries is not just about automation; it’s about unlocking the true potential of your data. By incorporating these tools into your EDA arsenal, you not only streamline your workflow but also gain a competitive advantage in the data-driven landscape.
Pickl.AI: Simplify Python Learning with the Python for Data Science course
For beginners, learning Python could be intriguing, but at Pickl.AI’s Python for Data Science course, you can learn the fundamentals of Python. The course encompasses modules focussing on Pandas, Numpy, Python OOPs and more.
By the end of this course, you will be familiar with the basics of Python. To learn more about this course, click on this link: https://www.pickl.ai/course/python-certification-training-program









