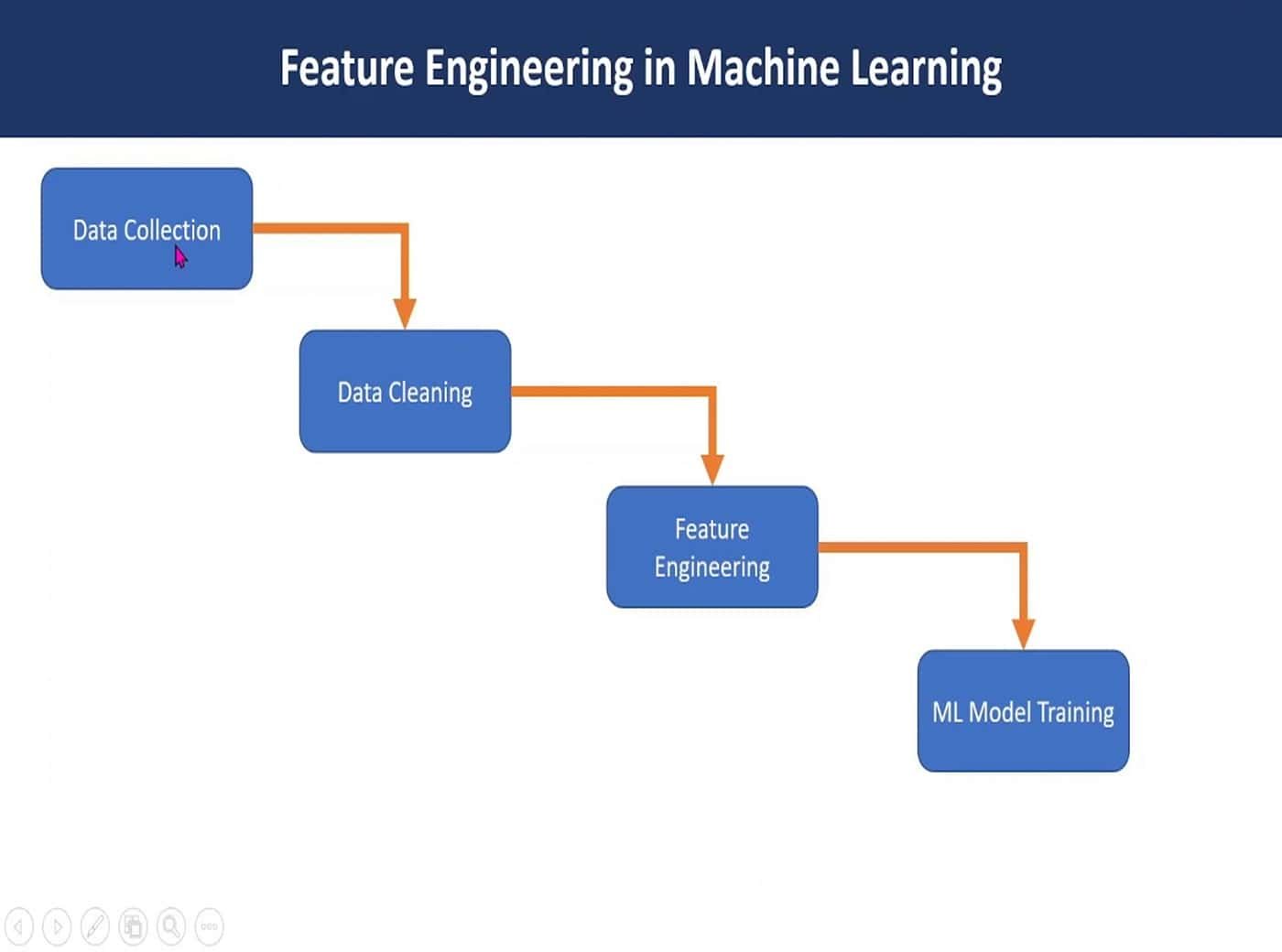
Feature engineering in machine learning is a pivotal process that transforms raw data into a format comprehensible to algorithms. This strategic step involves techniques like binning, encoding, and scaling, empowering models to extract meaningful patterns. Through Exploratory Data Analysis, imputation, and outlier handling, robust models are crafted.
Embrace the benefits of feature engineering to unlock the full potential of your Machine-Learning endeavors and achieve accurate predictions in diverse real-world scenarios.
The growing application of Machine Learning also draws interest towards its subsets that add power to ML models. Hence, it is important to discuss the impact of feature engineering in Machine Learning.
This transformative process involves crafting and selecting the most impactful variables to enhance model performance. Let’s delve into the intricacies of Feature Engineering and discover its pivotal role in the realm of artificial intelligence.
Key takeaways
- Feature engineering transforms raw data for ML, enhancing model performance and significance.
- Feature Engineering techniques include binning, polynomial features, encoding, time features, scaling, and more.
- EDA, imputation, encoding, scaling, extraction, outlier handling, and cross-validation ensure robust models.
- Feature Engineering enhances model performance, and interpretability, mitigates overfitting, accelerates training, improves data quality, and aids deployment.
What is Feature Engineering?
Feature Engineering is the art of transforming raw data into a format that Machine Learning algorithms can comprehend and leverage effectively. This crucial step empowers algorithms to extract meaningful patterns, ultimately elevating the accuracy and robustness of your models.
Feature Learning examples
Feature engineering is the backbone of successful Machine Learning models, allowing data scientists to unlock hidden patterns and enhance predictive performance. Here are some illustrative examples of feature engineering techniques:
Binning or bucketing
Objective: Grouping continuous data into bins to simplify complex patterns.
Example: Age ranges or income brackets can be created, transforming numerical data into categorical variables providing a clearer representation of trends.
Polynomial features
Objective: Introducing interaction terms by combining features to capture non-linear relationships.
Example: If ‘x’ and ‘y’ are featured, adding a new feature ‘, xy’ might help the model capture interactions that a linear model would miss.
Encoding categorical variables
Objective: Converting categorical data into numerical format for Machine Learning algorithms.
Example: Using one-hot encoding or label encoding for variables like gender or city, ensuring the model can effectively utilize these features.
Time features
Objective: Extracting valuable information from time-related data.
Example: Breaking down timestamps into components like day, month, or season, allowing the model to understand temporal patterns.
Scaling and normalization
Objective: Ensuring that all features have a similar scale, preventing dominance by features with larger magnitudes.
Example: Scaling features like age and income to a standardized range, such as [0,1], for improved model convergence.
Feature crosses
Objective: Creating new features by combining existing ones.
Example: Combining ‘weekday’ and ‘hour’ features to create a new feature representing the day and time, capturing daily patterns.
Missing value imputation
Objective: Addressing missing data to prevent information loss.
Example: Filling missing values in a ‘customer satisfaction’ column with the mean or median satisfaction score based on available data.
Text feature extraction
Objective: Transforming textual data into numerical representations.
Example: Using techniques like TF-IDF (Term Frequency-Inverse Document Frequency) to convert text data into features suitable for Machine Learning models.
Feature importance from trees
Objective: Leveraging decision tree-based models to assess feature importance.
For example, random forest or gradient-boosted trees can provide insights into which features contribute most significantly to model predictions.
Domain-specific features
Objective: Creating features tailored to the specific domain of the problem.
Example: For an e-commerce platform, introducing features like ‘average order value’ or ‘customer lifetime value’ based on transaction history.
By implementing these feature engineering techniques, data scientists can optimize their models, extract meaningful insights, and significantly improve the overall performance of Machine Learning systems.
Steps of Feature Engineering
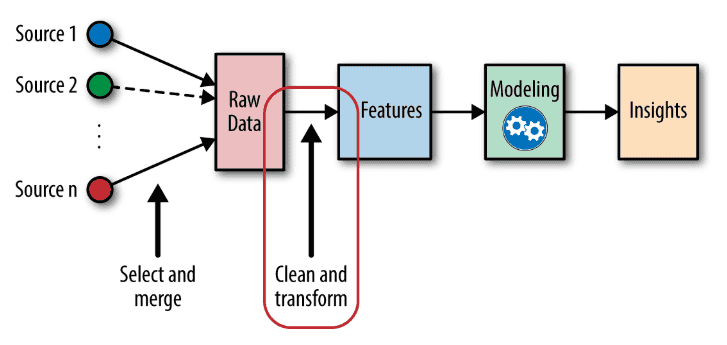
1. Exploratory Data Analysis (EDA): A foundation for success
The initial step in feature engineering is to conduct a meticulous Exploratory Data Analysis. Dive deep into your dataset, scrutinize patterns, and identify outliers. This not only refines your understanding but also lays the groundwork for feature selection.
2. Imputation: Filling the gaps with precision
In any dataset, missing values can be stumbling blocks. Imputation comes to the rescue, where strategic filling of these gaps ensures a robust dataset. Employ methods like mean, median, or advanced algorithms to impute missing values intelligently.
3. Encoding categorical variables: The language of algorithms
Machines comprehend numbers, not labels. Transform categorical variables into numerical equivalents through encoding. Techniques like one-hot encoding or label encoding bridge the gap between machine understanding and human-defined categories.
4. Feature scaling: Balancing the equation
The scale of features can significantly impact model performance. Standardization or normalization of features ensures a level playing field, preventing dominance by variables with larger scales.
5. Feature extraction: Unearthing hidden gems
Beyond the obvious features lies the realm of feature extraction. This involves creating new features based on existing ones capturing complex relationships that might be elusive to the naked eye. Techniques like Principal Component Analysis (PCA) can be instrumental in this process.
6. Handling outliers: Nurturing robust models
Outliers can skew predictions, leading to inaccurate results. Robustly address outliers by employing techniques such as trimming, winsorizing, or using outlier-resistant models to fortify the robustness of your Machine Learning model.
7. Cross-validation: Ensuring generalizability
Testing the model on the same data it learned from might not reveal its true potential. Cross-validation is the litmus test, splitting the dataset into subsets for training and validation, ensuring the model’s Generalizability.
Pros and cons of Feature Engineering
Pros
1. Enhanced model performance
One of the benefits of Feature engineering is that it acts as a transformative force, elevating model performance to new heights. By fine-tuning input features, the model gains a sharper understanding of patterns, leading to enhanced predictive capabilities and increased accuracy.
2. Improved model interpretability
Crafting meaningful features not only refines predictions but also enhances model interpretability. A well-engineered set of features allows stakeholders to comprehend the logic behind predictions, fostering trust and facilitating informed decision-making.
3. Mitigation of overfitting
Overfitting, the bane of many Machine Learning models, occurs when a model memorizes training data instead of learning patterns. Feature engineering serves as a guardrail against overfitting by aiding in the creation of robust and generalized features, fostering a model that excels in real-world scenarios.
4. Accelerated training speeds
Optimized features contribute to streamlined model training. By providing the model with relevant and impactful information, feature engineering minimizes the computational burden, accelerating the training process and making Machine Learning applications more efficient.
5. Enhanced data quality
Feature engineering is not merely about creating new features; it is also about refining existing ones. The process often involves handling missing values, outliers, and noisy data, resulting in a dataset of higher quality. This, in turn, contributes to the overall reliability of Machine Learning models.
6. Effective model deployment
Well-engineered features pave the way for seamless model deployment. The careful selection, transformation, and extraction of features ensure that the model is not only accurate during training but also performs optimally when applied to real-world scenarios.
7. Optimized resource utilization
Efficient feature engineering contributes to resource optimization. By focusing on the most relevant features, the model requires fewer resources for both training and inference, making it more scalable and cost-effective.
Cons
-
Manual effort involved
Feature engineering requires manual intervention, making it time-consuming and dependent on human expertise.
-
Risk of overfitting
Inadequate feature engineering may lead to overfitting, where models memorize training data but struggle with new, unseen data.
-
Potential data leakage
Improper feature engineering may inadvertently introduce information from the validation or test sets into the training data, leading to biased results.
-
Algorithm sensitivity
Some Machine Learning algorithms are more sensitive to feature engineering choices, requiring careful consideration to avoid suboptimal outcomes.
Frequently asked questions
What is feature engineering for Machine Learning libraries?
Feature engineering involves crafting input features to enhance model performance in Machine Learning libraries. It refines and optimizes data, ensuring that models comprehend and leverage the most relevant information for accurate predictions.
What is the difference between feature learning and feature engineering?
Feature engineering is the manual process of creating input features, while feature learning involves algorithms autonomously discovering relevant features from raw data. The former relies on human intuition, while the latter leverages computational methods for automatic feature extraction.
What is Featurization in Machine Learning?
Featurization in Machine Learning refers to the process of transforming raw data into a format suitable for model training. It encompasses steps like handling missing values, encoding categorical variables, and scaling features to optimize the dataset for effective Machine Learning model development.
What is feature learning in Machine Learning?
Feature learning is the automated process where Machine Learning algorithms extract meaningful patterns or features from raw data. Unlike feature engineering, it doesn’t require manual intervention; instead, algorithms autonomously identify and utilize relevant information to improve model performance and predictive accuracy.
Concluding thoughts
Feature engineering is not just a step in the Machine Learning pipeline; it is a strategic move towards empowering models with the capability to unravel complex patterns and make informed predictions.
Embrace the benefits of feature engineering and witness your Machine Learning endeavors transform into a journey of unparalleled success.









![What is Transfer Learning in Deep Learning? [Examples & Application]](https://www.pickl.ai/blog/wp-content/uploads/2023/02/Transfer-learning-150x150.jpg)