Introduction to Perceptrons: Building Your First Neural Network in Python
Perceptron Implementation in Python: Understanding the Basics of Artificial Neural Networks

Perceptron is the most basic unit of an artificial neural network. It takes several inputs and outputs a single binary decision.

x1, x2, x3, …, xi are the inputs and each input is multiplied by a weight, wi. b is the bias or threshold. We compare the weighted sum of the inputs with the threshold.

It can be expressed as w.x + b. We call it z. So, z = w.x + b
An input comes into the perceptron, gets a value for z, and a function (like the step-function above) is applied to z.

For example, we want to decide whether the patient is COVID by looking at 3 parameters using a single neuron. The three inputs are Cough, Fever, and Muscle Pain. Each has weights and we have a bias in the perceptron.

(1*4) + (1*2) + (0*2) — 5 = 1 > 0 -> output is 1. The decision is that the patient has covid.
Linear Classifier
Perceptrons are linear classifiers. Consider the following perceptron example.

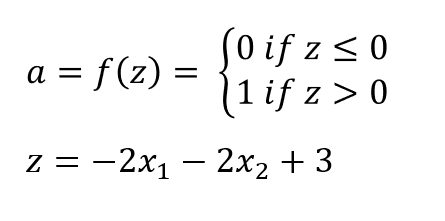
The input space of this equation would be:
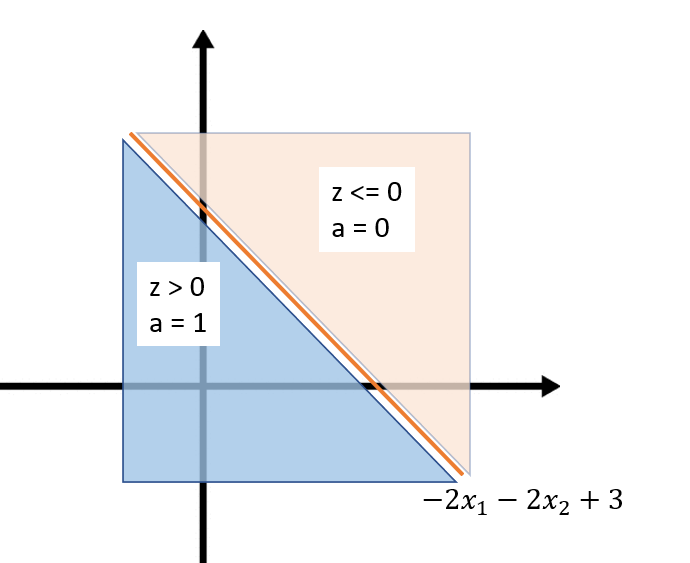
On the right side of the line, a = 0, and on the opposite side, a = 1. This behavior clearly demonstrates how it acts as a linear classifier.
Activation Functions
Several activation functions can be used in a perceptron, including:
- Step function: A binary function that produces an output of 1 if
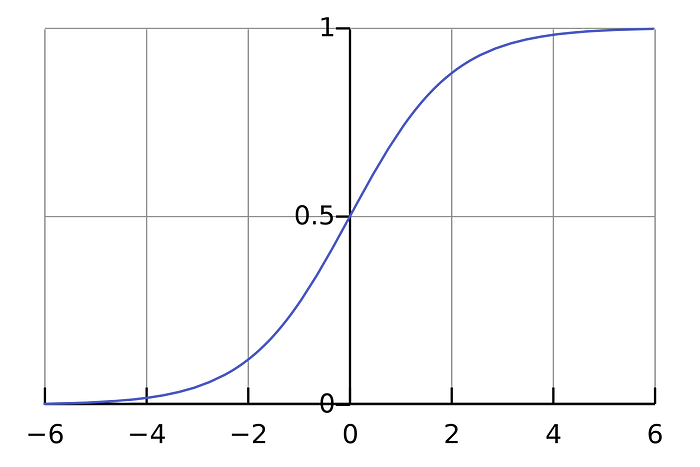
zis greater than the threshold, and 0 otherwise. - Sigmoid function: An S-shaped function with an output range of 0 to 1.
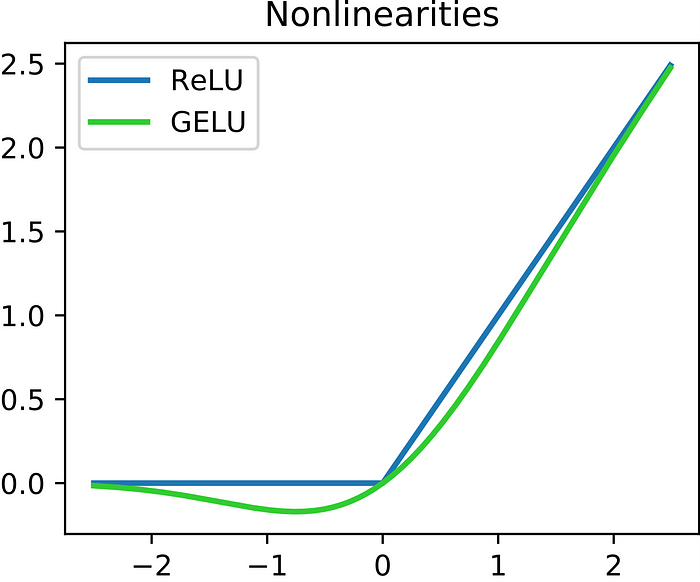
- Rectified Linear Unit (ReLU): Outputs 0 for negative
zand passes any positive value ofz.
- Hyperbolic tangent function: Also known as
tanh, it maps anyzvalue to a range between -1 and 1.
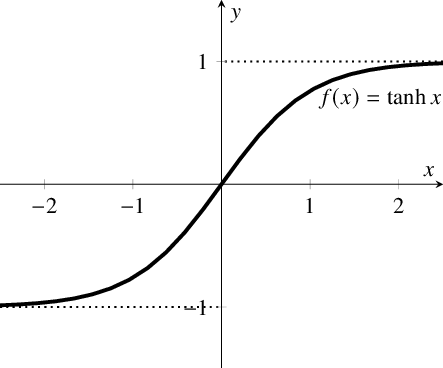
Learning
We compare the output of the perceptron with the desired output and update the weights and bias accordingly. Additionally, we use another parameter known as the learning rate, which determines the extent of the weight updates.
Δwᵢ = α(y — ŷ)xᵢ
w = wᵢ + Δwᵢ
- Δwᵢ is the change in weight for the i-th input feature
- α is the learning rate, which determines the step size for updating the weights
- y is the true label of the input data
- ŷ is the predicted label of the input data (output of the perceptron: a)
- xᵢ is the value of the i-th input feature
In the example below, x1 = 1 and x2= 1 and the actual label is 1. Our initial weights are w1 = 1, w2= 2, and bias is 5. Perceptron returns 0.
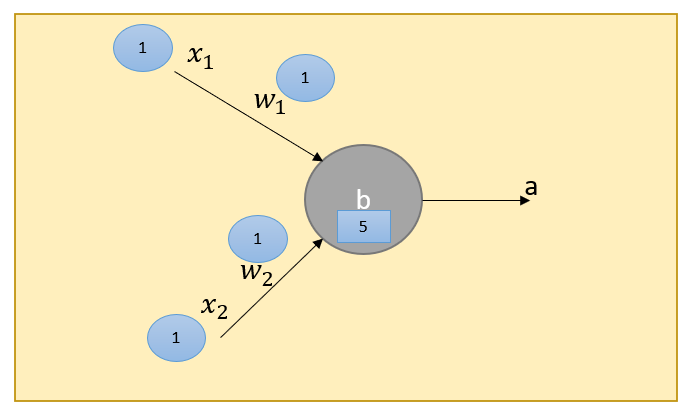
Let’s assume that α (learning rate) is 2 (it is almost always between 0 and 1, but for the sake of simplicity let’s make it 2).
Δw1,2 = 2(1–0).1=2. So the delta is 2, then our new weights would be 3.
In the updated scenario, z is 6, which is greater than 5, thus a = 1. This indicates that the perceptron has learned.
Logical Functions — AND
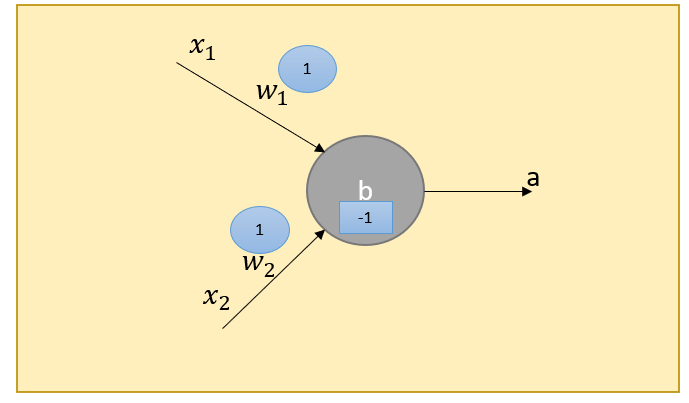
We can model AND logical function with a perceptron.

We can solve AND function by setting w1=1, w2=2, and b=-1.
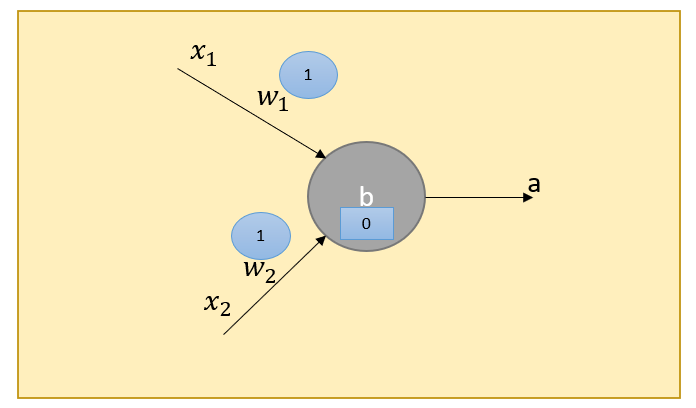
Logical Functions — OR

We can solve OR function by setting w1=1, w2=2, and b=0.
Multi-Layer Perceptron Network
We can create networks that have multiple layers of connected neurons (perceptrons). In contrast to a single-layer perceptron, which has a single layer of input and output neurons, an MLP has one or more hidden layers of neurons between the input and output layers.
Each neuron in a hidden layer receives inputs from the previous layer and computes a weighted sum of those inputs, similar to a single-layer perceptron. However, instead of directly outputting a binary classification result, the neuron applies an activation function to the weighted sum and passes the result to the next layer.

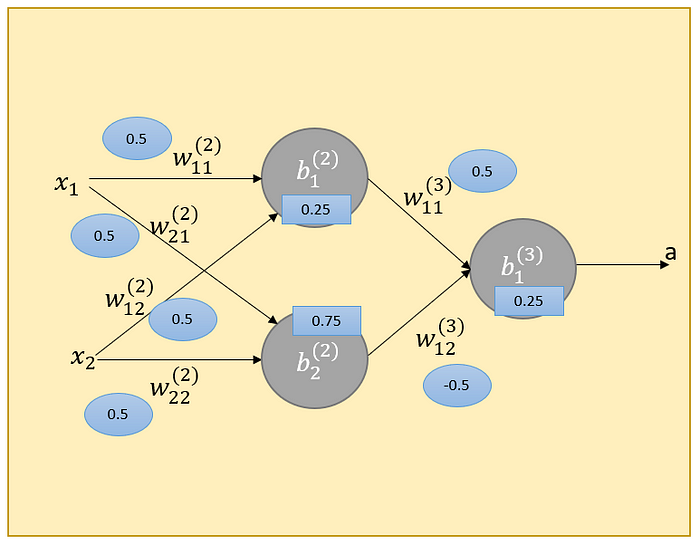
Logical Functions — XOR
XOR cannot be solved by a single perceptron. We need two layers at least.

The solution of XOR would be as follows:
Python
Let’s code a perceptron in Python.
import numpy as np
class Perceptron:
"""
A simple perceptron classifier.
"""
def __init__(self):
self.weights = None
self.bias = 0
def initialize(self, n_features):
"""set initial w and b as zeros"""
self.weights = np.zeros(n_features)
self.bias = 0
return
def predict(self, inputs):
"""
Predict the class labels for new input data.
calculate the step activation function
"""
activation = np.dot(inputs, self.weights) + self.bias
return 1 if activation > 0 else 0
def train(self, X, y, epochs=100, learning_rate=0.1):
"""Train the perceptron using the input data and target labels."""
# initialize the w and b
self.initialize(X.shape[1])
for epoch in range(epochs):
for inputs, label in zip(X, y):
# get prediction
y_pred = self.predict(inputs)
# calculate delta error
error = label - y_pred
# update w and b
self.weights += learning_rate * error * inputs
self.bias += learning_rate * error
returnLet’s test if this perceptron can learn logical functions like AND, and OR.
# AND
X_train = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y_train = np.array([0, 0, 0, 1])
p = Perceptron()
p.train(X_train, y_train, epochs=100, learning_rate=0.1)
test_input = np.array([0, 0])
print(p.predict(test_input)) # Output: 0
# OR
X_train = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y_train = np.array([0, 1, 1, 1])
p = Perceptron()
p.train(X_train, y_train, epochs=100, learning_rate=0.1)
test_input = np.array([0, 1])
print(p.predict(test_input)) # Output: 1Conclusion
In conclusion, perceptrons were the first type of artificial neural network and provided the foundation for the development of more advanced neural network models. While perceptrons had some limitations, such as only being able to model linearly separable data, they led to the development of more advanced models like multi-layer perceptrons.
Learning about perceptrons is important for building a foundation in neural network concepts and understanding the potential of more advanced models for solving complex problems.
Read More
Sources
https://www.youtube.com/watch?v=OFbnpY_k7js
https://www.youtube.com/watch?v=4Gac5I64LM4
https://www.youtube.com/watch?v=s7nRWh_3BtA
BECOME a WRITER at MLearning.ai
Stackademic 🎓
Thank you for reading until the end. Before you go:
- Please consider clapping and following the writer! 👏
- Follow us X | LinkedIn | YouTube | Discord
- Visit our other platforms: In Plain English | CoFeed | Venture | Cubed
- More content at Stackademic.com

