
What Is Data Processing?
Data Processing is the process of transforming and manipulating raw data to meaningful insights for effective use in business purposes. It requires different techniques and activities including organising, analysing and extraction of valuable information. Data Processing is done in both manual and automated manner, depending on the type of complexity in the data and the required outcomes.
The importance of Data Processing lies in various fields like business, finance, healthcare, scientific research, etc. Consequently, it enables organisations to make important decisions, discover trending patterns, solve business problems and improve efficiency by leveraging the power of data.
Examples of Data Processing
There are various examples that can be considered important and part of the Data Processing for better understanding the process. Following are the examples of Data Processing:
- Financial: large volumes of processing of transactional data happens on a daily basis within banks and financial institutions. They are involved in performing different tasks such as validating transactions, calculating balances and detection of fraud patterns. Additionally, Data Processing is also used for generating financial statements and conducting risk assessments.
- Ecommerce: Customer data including history, preferences and demographics by online retailers involves Data Processing techniques. Additionally, these ecommerce businesses also use Data Processing for personalising customer recommendations, optimising pricing strategies, tracking inventory and managing order fulfilment.
- Healthcare: within the healthcare industry, healthcare providers processes patient records, lab results, medical images and other related data. They specifically use Data Processing techniques that help in diagnosing diseases, monitor patient health, conduct medical research and improve treatment outcomes.
- Social Media: with social media being widely popular and highly crucial in the digitised world, the platform uses Data Processing for vast amounts of user generated content. It includes posts, comments and interactions that take place in the social media platforms. These platforms employ Data Processing methods that analyses user behaviour, personalises content feeds, detects spams and target advertisements.
- Manufacturing: the industry of manufacturing involves companies that make use of Data Processing techniques for monitoring and controlling different operations. From production processes involving quality control to supply chain management, inventory tracking and equipment maintenance, all requires Data Processing. By leveraging Data Analysing techniques, manufacturing companies optimises processes, improves efficiency and reduces costs.
Why is Data Preprocessing Important In Machine Learning?
With the help of data pre-processing in Machine Learning, businesses are able to improve operational efficiency. Following are the reasons that can state that Data pre-processing is important in machine learning:
- Data Quality: Data pre-processing helps in improving the quality of data by handling the missing values, noisy data and outliers. Accordingly, by addressing the issues, the dataset that is released as the outcome becomes more reliable and accurate. This helps in enabling better performance of the Machine Learning model.
- Data Consistency: Data is sourced in the real world from multiple sources which results in these data involving various forms of inconsistencies in formats, units or scales. With the help of data pre-processing techniques, it is possible to ensure that data remains in the standardised and consistent format. It allows and helps in fair comparisons between features and reducing the biases in Machine Learning models.
- Feature Engineering: the technique of data pre-processing allows feature engineering which involves creation of new features or transforming existing ones. It helps in improving model performance. With the need of selecting and constructing relevant features, Machine Learning models can help in capturing more meaningful patterns and relationships in the data.
- Dimensionality Reduction: for Machine Learning models, high-dimensionality data can be quite challenging. With Data Pre-processing techniques like dimensionality reduction help in reducing the number of features whereby training the most important information. Consequently, it helps in alleviating the challenge of dimensionality and improving the model’s efficiency.
Types of Data Processing

Data Pre-processing includes different types with each serving different purposes and therefore catering to specific needs of Machine Learning. Some of the common types of Data Processing are:
- Batch Processing: this type of Data Processing involves processing of large volumes of data in batches. The data collected over a long period of time are processes together as a batch. Batch processing is typically useful for non-real-time or offline cases, where the need for instant results is not important. The technique is often used for tasks such as Data Cleaning, aggregation, reporting and generating reports in batches.
- Real-Time Processing: this type of immediate processing of data in real-time focuses on the data that arrives immediately and involves handling and analysing data in real-time. It helps organisations to receive instant results and is commonly used in applications where prompt decisions are to be made. Accordingly, these decisions are made on incoming data such as fraud detection, stock market analysis or real-time monitoring systems.
- Online Processing: this type of Data Processing involves managing transactional data in real time and focuses on handling individual transaction. It includes transactions like recording sales, processing customer orders, or updating inventory levels. The systems are designed to ensure data integrity, concurrency and quick response times for enabling interactive user transactions. In online analytical processing, operations typically consist of major fractions of large databases. Therefore, today’s online analytical systems provide interactive performance and the secret to their success is precomputation.
- Time Sharing Processing: in this type of processing, the CPU of a large-scale digital computer helps in interacting with multiple users with the help of different programs simultaneously. With this type of processing, solving several discrete problems during the input/output process is possible because the CPU is faster than most peripheral equipment. This helps the CPU to address each problem sequence-wise. However, remote terminals have the impression that access to and retrieval from time-sharing system enables instant outcomes. This is because the solutions are immediately available as soon as the problem is fully centred.
- Distributed Processing: with the help of distributed processing, it is possible to endure analysis of data across multiple interconnected systems or nodes. The type of Data Processing enables division of data and processing tasks among the multiple machines or clusters. The process therefore, helps in improving the scalability and fault tolerance. Distributed processing is commonly in use for big Data Analytics, distributed databases and distributed computing frameworks like Hadoop and Spark.
- Multi-processing: it is the type of Data Processing in which two or more processors tend to work on the same dataset at the same time. In this process, multiple processors are housed within the same system. Consequently, data is broken down into frames whereby each frame is processed by two or more CPUs in a single computer system, working in parallel ways.
Read Blog: Eager Learning and Lazy Learning in Machine Learning
Steps in the Data Processing cycle
The Data Processing cycle consists of various stages where raw data is fed to the system for producing actionable insights. Each step take in specific order and the entire process is repeated in a cyclic manner. Following is steps of Data Processing cycle in Machine Learning:
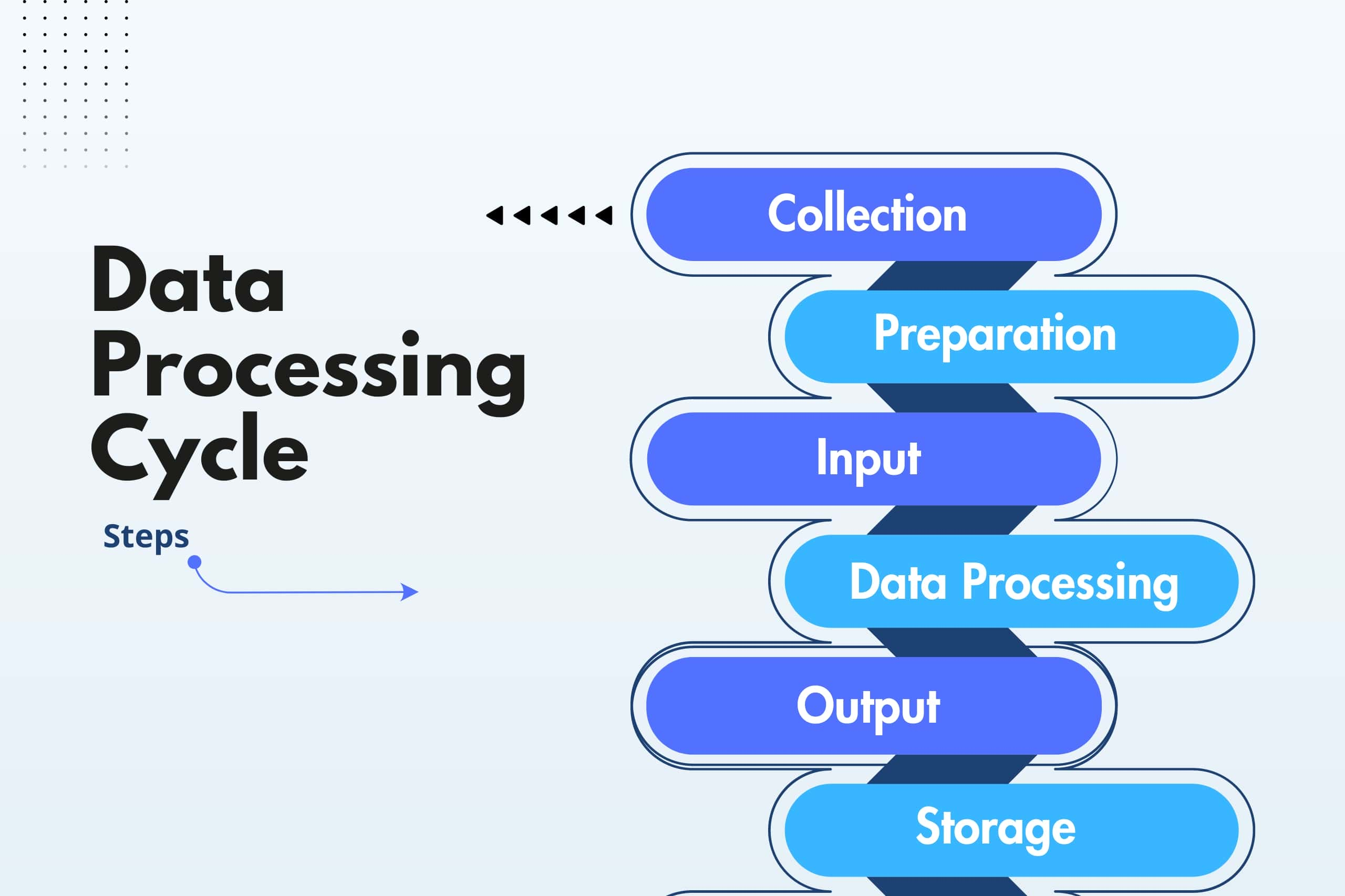
- Collection: the collection of raw data refers to the first step in the Data Processing cycle. Accordingly, the type of data collected is typically raw and has a huge impact on the output produced. The raw data hence, shall be gathered from accurate sources ensuring that the subsequent findings are effectively valid and usable. Raw data includes monetary figures, website cookies, profit/loss statements of a company, etc.
- Preparation: the second stage in Data Processing cycle is preparing the data or Data Cleaning that involves sorting and filtering raw data for removing unnecessary and inaccurate data. Significantly, checking of errors, duplications, miscalculation or missing data from raw data is checked and transformed into a more suitable form for further analysis and processing. The purpose of the Data Cleaning or preparation stage is to ensure that the information fed to the processing unit is of the highest quality.
- Input: the third stage requires the raw data to be converted into a Machine Learning form that is readable and fed to the processing unit. It is possible that the process can be in the form of data entry made through the use of a keyboard, scanner or any input source.
- Data Processing: the raw data in this stage of Data Processing is subjected to different methods that makes use of Machine Learning and Artificial Intelligence algorithms. It essentially helps in the generation of a desirable output. The step varies slightly from process to process depending on the source of data being processed.
- Output: the fifth stage of the data cycling process is the output where the data is finally transmitted and displayed to the users in the readable format. It includes graphs, tables, vector files, audio, video, documents, etc. The output generated from this stage is stored and further processed for the next Data Processing cycle.
- Storage: the last step involves the Data Processing cycle involves storage of the data and metadata for further use. Accordingly, it allow in quick access and retrieval of information whenever one needs and ensures to be used as the input in the next Data Processing directly.
FAQs
Which is the correct sequence of data pre-processing?
The correct sequence of data pre-processing involves Data Cleaning, Data Integration, Data Transformation, Data Reduction, Data Discretisation and Data Normalisation.
What is the key objective of Data Analysis?
The key objective of Data Analysis is to help businesses in optimising its performance, maximise profit or make more decisions quite strategically.
What is the importance of Data Pre-Processing?
Data Pre-processing involves transforming raw data to a clean and useful data. The Dataset is technically about a process of pre-processing helpful for checking missing vales, noisy data and other inconsistencies.
Conclusion
The blog comes to the conclusion that Data Processing in Machine Learning is indeed a critical part in the various domains including business, finance, healthcare, etc. Playing a significant role in the Machine Learning process, Data Processing ensures to be reliable and consistent for training ML Models. If you want to learn different Data Processing techniques and ensure to make informed business decisions, join Pickl.AI. The Data Science courses provided by Pickl.AI will allow you to learn these techniques and become an expert in the industry.









