Logo:
Logo:  Areas Served:
Areas Served: 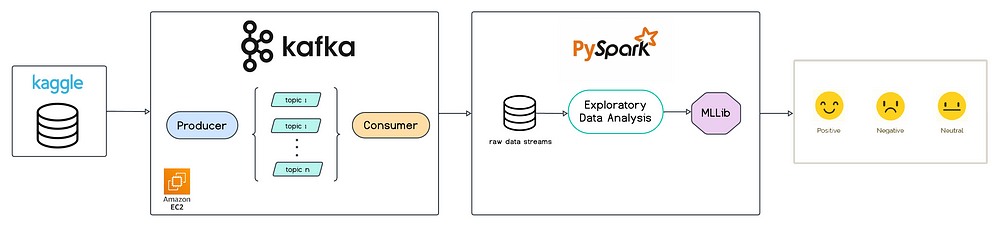
Real-Time Sentiment Analysis with Kafka and PySpark
Last Updated on February 29, 2024 by Editorial Team
Author(s): Hira Akram
Originally published on Towards AI.
As technology continues to advance, the generation of data increases exponentially. In this dynamically changing landscape, businesses must pivot towards data-driven models to maintain a competitive edge. Time emerges as a critical factor in this equation, where the ability to make timely decisions surpasses all other strategies. Real-time data streaming pipelines play a crutial role in achieving this objective. Within this article, we will explore the significance of these pipelines and utilise robust tools such as Apache Kafka and Spark to manage vast streams of data efficiently. Additionally, we’ll create an end-to-end sentiment analysis process, demonstrating the practical application of these technologies in real-world scenarios.
What is Real-Time Data Processing?
Real-time data processing refers to systems that ingest data streams as they are being generated. To put it simply, imagine scrolling through your Instagram feed and coming across a video. After watching it, you double-tap to express your liking. This action will be stored and sent back to the system. Over time, you may notice that your feed now contains similar content to that video. Have you ever wondered how this happens? Well, when you indicate that you like a certain type of content, this data is processed in real-time, and your recommendations are reshaped accordingly to match your preferences. This is essentially how data is processed in real-time. Apache Kafka plays a crucial role in enabling data processing in real-time by efficiently managing data streams and facilitating seamless communication between various components of the system.
Apache Kafka
Apache Kafka is a distributed event streaming platform used for building real-time data pipelines and streaming applications. Operating on a publish-subscribe messaging model, where producers are tasked with publishing data to topics while consumers subscribe to these topics to process the data. Let's take a better look at the key components:
- Producers: They publish/push records to Kafka topics.
- Topics: Think of these as logs supporting partitions, where each data point is systematically stored.
- Brokers: Servers that are responsible for managing the topics and handling incoming (producers) and outgoing (consumer) data traffic.
- Consumers: They subscribe/pull records from Kafka topics.
Let’s get started on setting up our very own ingestion pipeline! To begin, we’ll need to ensure that a Kafka broker is up and running. We’ll handle this entire setup process on Amazon Elastic Compute Cloud (Amazon EC2). Let’s dive in!
- Launch EC2 instance: Create an EC2 instance with appropriate security group settings allowing inbound traffic on Kafka ports.
- Connect to EC2 Instance: SSH into the instance using your key pair:
3. Install Java and Download Kafka: Install Java on the EC2 instance and download the Kafka binary:
4. Start Kafka Broker: First, you need to configure server properties and then start your broker so that we can set up a topic on this broker:
5. Create Topic, Producer and Consumer: Let’s create a Topic called ‘sentiments’ which will interact with our Consumer and Producer to receive and analyze data in real-time:
PySpark
PySpark serves as the Python interface to Apache Spark, enabling developers to tackle real-time, large-scale data challenges within a distributed environment. Spark’s framework consists of the following key components:
- Driver Program: This central program initializes the SparkContext, divides tasks, and coordinates their execution. It communicates with the Cluster Manager to allocate resources and oversee task progress.
- SparkContext: Facilitates communication between the Driver program and the Spark Cluster. It also aids in creating SparkSessions, enabling interaction with DataFrames and Datasets.
- Cluster Manager: Responsible for resource allocation and monitoring Spark applications during execution.
- Executor: These worker nodes execute multiple tasks concurrently, storing data in memory or disk as directed by the Spark Driver.
- RDD, DataFrames and Datasets: RDDs form the backbone of Spark, while DataFrames resemble relational database representations, and Datasets excel in handling structured and semi-structured data.
- Transformations and Actions: Transformations modify existing data structures, while Actions trigger execution and return results to the Spark Driver. DAG (Directed Acyclic Graph) are the logical execution plan outlining transformations and actions, describing the sequence of operations required to compute the final result.
Spark provides APIs for SQL queries (Spark SQL), real-time stream processing (Spark Streaming), machine learning (MLlib), and graph processing (GraphX). Let’s set up a SparkSession configured to interact with Kafka for our Sentiments Analysis application. This involves specifying the required Scala and Spark versions, along with essential Kafka integration packages.
With the SparkSession initialized, we’re equipped to receive a data stream from a Kafka topic named ‘sentiments’. This data is read as a streaming DataFrame and stored in-memory as a table named “sentiments_data”. Next, we run an SQL query to extract the data.
Real-Time Sentiment Analysis
Until now, we’ve configured a running Kafka broker, allocated a topic for live data streams, and configured Spark Streaming to subscribe to this specific topic. Additionally, we’ve executed an SQL query to persist the data into a PySpark DataFrame. Now let’s take a look at our data.

Data Parsing
Before we dive into the data exploration process on this Kaggle dataset, let’s execute the following lines of code to enable structured parsing and extraction of JSON data from the DataFrame. This will facilitate further analysis and manipulation of the data within the PySpark environment.
Top words
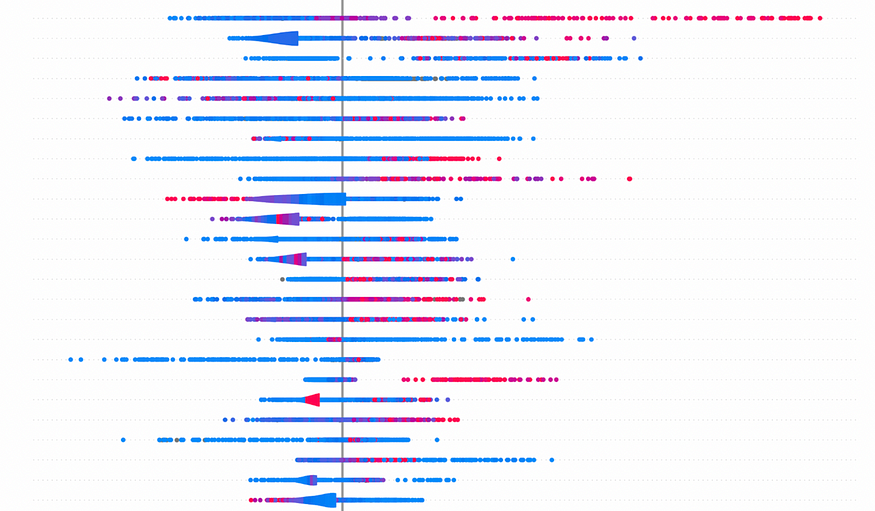
We’re exploring the top five most frequently used words (Figure 1) categorized under ‘positive,’ ‘negative,’ and ‘neutral’ sentiments, derived from the ‘comment’ column. This analysis helps us understand the common words linked to various sentiment categories.

Preprocessing
Now, our next step is to prepare the text data for sentiment analysis. This involves removing duplicate rows, assigning sentiment labels based on ratings, balancing sentiment categories, and splitting the data for training and testing. Next, we tokenize comments, remove stopwords, and convert words into numerical features.
With these preparations complete, we can proceed to build a logistic regression model to predict sentiment based on these features. Moreover, we will save the model for later use.
Evaluation
Now that the training is complete, we apply the model to predict outcomes on the test data. Following this, we assess the model’s performance by calculating the accuracy metric using the test dataset.
We can also generate a confusion matrix (Figure 2) to visually represent the model’s performance.

Predictions on the fly
Now for the most awaited part! With data continuously flowing from our Kafka topic named ‘sentiments’, Spark processes it in parallel, generating predictions on the fly. The code below fetches the latest streams from our topic and performs real-time sentiment predictions after preprocessing the data. This enables businesses to swiftly adapt to shifting trends and make decisions based on live data. Here’s a link to the GitHub repository of this project.
Below are a few example predictions based on the streaming data. Feel free to generate a new topic and start storing it in memory.
+-------+-----------------------------------------------------------------------+---------+
U+007Cuser_idU+007Ccomment U+007CsentimentU+007C
+-------+-----------------------------------------------------------------------+---------+
U+007C32 U+007C"The unexpected conflicts added depth and excitement to the storyline."U+007Cpositive U+007C
U+007C346 U+007C"Draco Malfoy's cunning nature added tension to the plot." U+007Cnegative U+007C
U+007C484 U+007C"The film's magic is truly spellbinding." U+007Cpositive U+007C
U+007C164 U+007C"Severus Snape's character arc is one of the highlights of the film." U+007Cnegative U+007C
U+007C19 U+007C"The pacing dragged, and the visual effects were unimpressive." U+007Cnegative U+007C
U+007C421 U+007C"The special effects are mind-blowing!" U+007Cpositive U+007C
U+007C16 U+007C"The magical world is brought to life with stunning visuals." U+007Cneutral U+007C
U+007C343 U+007C"Rubeus Hagrid's love for magical creatures added a unique charm." U+007Cpositive U+007C
U+007C202 U+007C"Draco Malfoy's cunning adds a layer of suspense." U+007Cpositive U+007C
U+007C201 U+007C"Magical creatures added a delightful touch." U+007Cpositive U+007C
+-------+-----------------------------------------------------------------------+---------+
only showing top 10 rowsConclusion
In summary, harnessing Apache Kafka and PySpark for real-time data processing equips organizations with agility, reliability, and scalability essential for navigating today’s dynamic data landscape. Through our sentiment analysis example, we’ve demonstrated the power of this integration in deriving actionable insights from streaming data.
Thanks for reading! ^_^
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts
Popular posts

 for 2021")



Updates

Recent Posts