
 Logo:
Logo:  Areas Served:
Areas Served: Outsmarting the Masters: How Weak AI Trains Super AI
Last Updated on January 2, 2024 by Editorial Team
Author(s): Yunzhe Wang
Originally published on Towards AI.
Superintelligent AI systems will be extraordinarily powerful; humans could face catastrophic risks including even extinction if those systems are misaligned or misused. It is important for AI developers to have a plan for aligning superhuman models ahead of time — before they have the potential to cause irreparable harm. (Appendex G in the paper)
Weak-to-Strong Generalization: Eliciting Strong Capabilities With Weak Supervision
Widely used alignment techniques, such as reinforcement learning from human feedback (RLHF), rely on the ability of…
arxiv.org
Human supervision plays a critical role in overseeing large artificial intelligence models, like GPT-4, today. However, as we progress towards creating superintelligence — AI that surpasses even the smartest humans in complex tasks — human supervision inevitably becomes weaker. To ensure such models remain beneficial to humanity and under human control, questions arise: Can weak human supervision effectively elicit and control the full capabilities of strong models? Is there additional work we can do to make weak supervision more efficient?
Although superintelligence does not yet exist, solving this problem beforehand is critical. The OpenAI superalignment team approaches this problem through an analogy: weak AI models (GPT-2) are to strong AI models (GPT-4) as humans are to superintelligence.

The main results and takeaways have been summarized quite well in the official blog post. This blog post offers a complementary overview of some key technical concepts and methodologies introduced in this paper for learning purposes.
Throughout the post, consider GPT-2 as the weak supervisor and GPT-4 as the strong student. This paper examines the extent of performance GPT-4 can achieve by training it with labels generated by GPT-2 on given tasks of interest.
Concepts and Methodologies
- Weak-to-Strong Generalization: The phenomenon where a strong AI model, when fine-tuned on labels generated by a weaker model, performs better than the weaker supervisor.
- Performance Gap Recovered (PGR): A metric to evaluate weak-to-strong generalization over a pair of weak and strong models.
- Bootstrapping with Intermediate Model Sizes: Sequential training of models of increasing strength, improving weak-to-strong generalization.
- Auxiliary Confidence Loss: Encourage strong models to learn a broader understanding of the weak supervisor at the early stage and shift towards gaining confidence in their own predictions, avoiding replicating errors made by the weak supervisor, thereby improving weak-to-strong generalization.
- Generative Supervision: Self-supervised finetuning on task-relevant data to enhance the salient representation of the task at hand, thereby improving weak-to-strong generalization.
- The Challenge of Imitation and the Inverse Scaling Phenomenon: Strong models not only learn from the weak supervisor but also overfit its errors. However, a phenomenon is observed that larger student models tend to agree less with the errors of the supervisor than smaller student models.
- Enhancing Concept Saliency through Linear Probing: Finetuning language models on weak labels followed by linear probing with ground truth labels significantly improves concept saliency, indicating the weak label finetuning process makes the task more linear.
Performance Gap Recovered (PGR)
PGR is a metric that measures the effectiveness of a weaker AI model’s supervision in improving the performance of a stronger AI model. It is a function of three performance metrics:
- Weak Performance: The evaluation of a weak model trained on ground-truth labels. Predictions of the weak model are used as weak labels.
- Strong Ceiling Performance: The evaluation of a strong model trained on ground-truth labels.
- Weak-to-Strong Performance: The evaluation of a strong model trained on weak labels generated by the weak model.

Note:
- PGR == 1 indicates perfect weak-to-strong generalization
- PGR == 0 indicates negligible weak-to-strong generalization.
Bootstrapping with Intermediate Model Sizes
Bootstrapping is a long-standing concept in alignment: instead of directly aligning superhuman models, we could first align a slightly superhuman model, then use it to align an even smarter model, and so on.
Specifically, consider a sequence of model sizes: M1 < M2 < … < Mn. We use the weak labels from M1 to fine-tune M2, then use M2 to generate new weak labels to fine-tune the next model in the sequence, M3, and so on.
This study found that Bootstrapping improves weak-to-strong generalization.
Auxiliary Confidence Loss
Directly training a strong student model to mimic a weaker supervisor risks the student replicating the supervisor’s mistakes. To prevent this, a regularization loss term is introduced. This term encourages the strong model to maintain confidence in its own answers when the weak supervisor errs, learning the supervisor’s intent without imitating its mistakes.
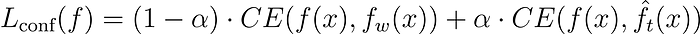
In particular
- CE(⋅ , ⋅) is the cross-entropy function
- f(x) ∈ [0, 1] is the predictive distribution of the strong model
- f_w(x) ∈ [0, 1] is the predictive distribution of the weak model (weak labels)
- ˆf_t(x) = I[f(x) > t]∈ {0, 1} is an indicator function that hardens the predictive distribution of the strong model based on threshold t. Let’s say the strong model outputs a prob distribution like [0.9, 0.2, 0.3, …]. With threshold t = 0.7, the hardened distribution becomes [1, 0, 0, …]. This makes the strong model learn by becoming more confident in its own answers.
Let's see what happens when we gradually increase α.
- When α is low (near 0), the loss primarily minimizes the discrepancy between the strong model’s predictions and the weak labels, allowing the strong model to initially learn from the broader, possibly noisier information (intent) provided by the weak supervisor.
- As α increases, the loss function gradually shifts its focus to reinforce the strong model’s predictions by hardening their confidence, thereby encouraging the model to increasingly rely on its own learned representations and decisions.
Generative Supervision

Generative Supervision (or more broadly self-supervised learning) involves fine-tuning a pre-trained model on task-relevant data without using traditional labeled data. This method helps the model to learn by generating data that reflects the task, enhancing its understanding and performance. For example, in a sentiment analysis task, by fine-tuning a language model on a large volume of online reviews without directly teaching it about sentiment, the model learns to associate certain words and phrases with positive or negative sentiments by itself.
In this study, the method involves fine-tuning a language model on ChatGPT’s comparison reward modeling data. These comparisons consist of prompts and candidate completions, and the completitions include both the best-ranked and worst-ranked completions. Therefore, the fine-tuning supervision should not, in principle, leak human-preferred ground truth data. Yet, this method still leads to improved weak-to-strong performance.
Understanding the Challenge of Imitation
The challenge of imitation involves a strong model that potentially ends up mimicking the supervisor’s systematic errors during learning. This risk is particularly acute when the weak supervision includes easily learnable systematic errors. The theoretical implications of this are significant, as it raises concerns about the model’s ability to generate independent, superior predictions rather than just echoing human-like responses or the flawed outputs of its weak supervisor.
Student-Supervisor Agreement is a way to measure imitation, by directly calculating the fraction of test inputs where the strong student makes the same prediction as the weak supervisor. It’s important to note that if the agreement were 100%, the weak-to-strong accuracy would equal the supervisor’s accuracy, and the PGR would be 0.
By measuring the Student-Supervisor Agreement on strong student models of varying sizes, an inverse scaling phenomenon is observed: larger models tend to agree less with the weak supervisor’s errors compared to smaller ones.
Weak-Supervision increases concept saliency
Concept saliency refers to how linearly a concept is represented. To assess this, a linear probe (a logistic regression classifier) can be trained on the model’s frozen activations. The central idea is that if a concept can be effectively captured with a linear probe, it’s considered more salient. The study compares five different strategies for increasing concept saliency: training a linear probe with weak or ground truth labels, finetuning the model on weak labels, finetuning followed by probing with ground truth labels, and finetuning on ground truth labels. The effectiveness of these strategies is measured in terms of test accuracy, revealing how each approach impacts the model’s ability to linearly represent concepts.

The results show that linear probes trained with ground truth labels are less effective than finetuning with ground truth labels, suggesting that the optimal solution to most tasks isn’t completely linear in the model’s final activations. However, a significant finding is that finetuning on weak labels and then probing with ground truth labels substantially improves performance. This method notably outperforms the baseline method of finetuning from weak to strong labels, closing much of the gap between ground truth linear probing and fine-tuning.
Further Reading
Weak-to-strong generalization
We present a new research direction for superalignment, together with promising initial results: can we leverage the…
openai.com
Statement on AI Risk U+007C CAIS
A statement jointly signed by a historic coalition of experts: "Mitigating the risk of extinction from AI should be a…
www.safe.ai
Managing AI Risks in an Era of Rapid Progress
In this short consensus paper, we outline risks from upcoming, advanced AI systems. We examine large-scale social harms…
arxiv.org
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts
Popular posts

 for 2021")



Updates

Recent Posts

