NOTES, DEEP LEARNING, REMOTE SENSING, ADVANCED METHODS, SELF-SUPERVISED LEARNING
Retell a Paper: “Self-supervised Learning in Remote Sensing: A Review”
A note of the paper I have read
Hi everyone,
In today’s story, I would share notes I took from 32 pages of Wang et al., 2022’s paper. The paper discusses an overview of self-supervised learning strategies for remote sensing applications.
What you can expect from this story is the general overview of their paper which later more details are in separate stories. They have done a very comprehensive study regarding this topic so lot of things we can talk about. Thus, it is better to begin with a general one.
In this story, my review of their paper can be divided into:
- Introduction (definition and motivation)
- Characteristics of remote sensing data
- Taxonomy of the self-supervised learning
- Evaluation Matrix
- Challenges and future directions
Introduction
Self-supervised learning (SSL) is one of the learning techniques in deep learning where a model learns to extract useful features or representations without needing any labeled annotation. In the implementation, the model is expected to learn high-level representations of the input data. So, it can be served as a transfer model which then can be further transferred to downstream tasks. the general principle of SSL is depicted in Figure 1.
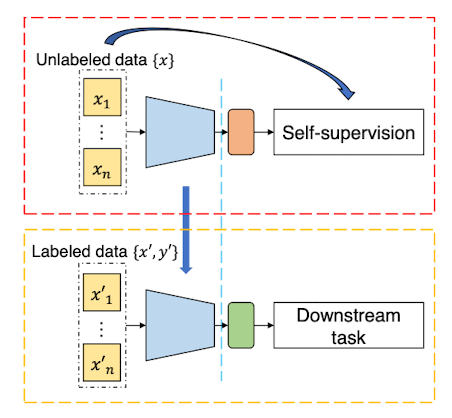
Deep learning notoriously needs a lot of data in training. However, in remote sensing, getting a sufficient number of labeled data remains a challenge. Furthermore, currently, models become more complex and require a huge number of parameters which leads to requiring a lot more data to be annotated. To get things worse, annotating remote sensing data has to be done by experts in the domain expertise. Moreover, there are other aspects that make remotely sensed imagery become more complex than the common image. Therefore, with its independency of annotated data, SSL becomes a promising technique for remote sensing to apply deep learning.
Characteristics of remote sensing data
When it comes to working with remote sensing data and deep learning techniques, several things need to be considered since remotely sensed data is quite different from common images in computer vision. Here are some characteristics of remote sensing data:
- Multiple modalities. Remote sensing applies various types of data and various types of sensors according to their applications. In general, it can be grouped into optical (multi- and hyper-spectral), LiDar, synthetic aperture radar (SAR), or even a combination of those three types (usually called multi-modal data). Hence it could be possible the image is not only in 3 channels RGB.
- Geolocated. In remote sensing data, each pixel represents a geospatial coordinate. It can be used as additional chances to design the SSL e.g., as a pre-text.
- Correspond to physical meaning. Remote sensing data is acquired using geodetic measurements that correspond to specific physical meanings. If this character is not handled well, it can provoke issues with the data augmentation particularly when applying contrastive learning
- Multi-object in single imagery. In most cases, remote sensing imagery contained lots of objects in it compared to natural images e.g., images from ImageNet (which only contains a few main objects). In remote sensing, it could be possible to have many repeated objects.
Taxonomy of the self-supervised learning
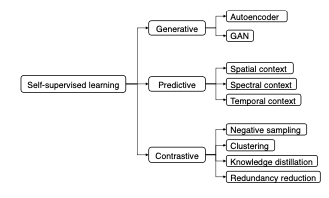
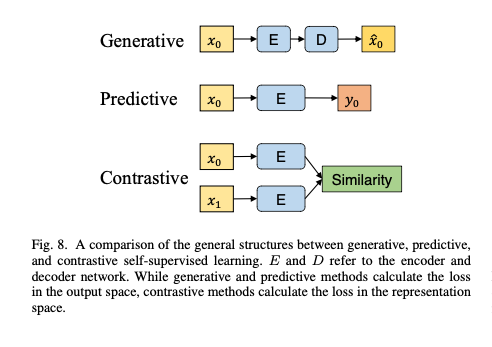
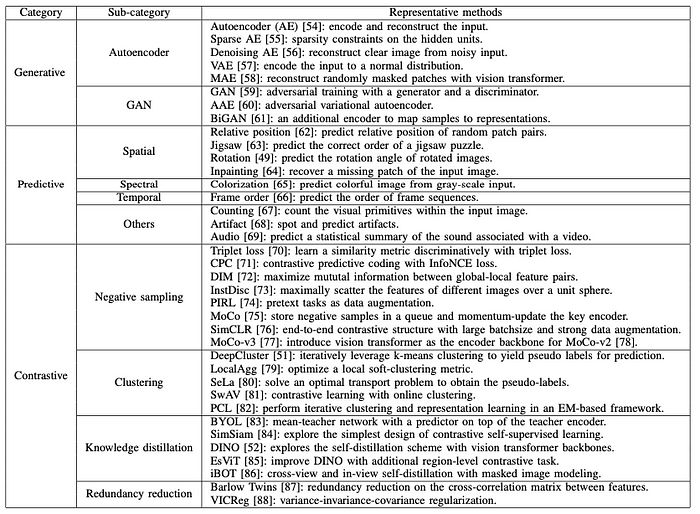
Wang et al. provide a comprehensive grouping of how SSL has been implemented in both computer vision and remote sensing. They group the SSL into three: generative, predictive, and contrastive. In a nutshell, the taxonomy of SSL is shown in Figure 2. While the general structure of SSL can be seen in Figure 3. Furthermore, existing works in SLL according to its taxonomy can be found in Figure 4.
Generative
In the generative self-supervised method, representations are learned by reconstructing or generating input data. There are sub-categories in this method:
- Autoencoder. Autoencoder consists of encoder and decoder. Those networks are trained to reproduce their input at the output layer. Usually autocoder is introduced with bottleneck structure in the middle (between encoder and decoder) which allows dimensionality reduction. Later on, the encoder is used as a transfer model.
- Generative Adversarial Network (GAN). The GAN approach comes from a game theory. It consists of two models: a generator and a discriminator. The generator takes random input and then constructs synthetic samples. While the discriminator distinguishes the generated sample from real data samples. Here, in GAN, the latent representation is modeled through the inverse of the generator.
Predictive
Predictive methods work by predicting the self-generated labels or auto-generated labels, for instance, rotation angles of rotated images, missing patches, etc. This method is also called pre-text tasks. These pre-text tasks can be categorized as follows: spatial context, spectral context, temporal context, and other semantic context. More detailed explanations of this task will be described in a different article.
Contrastive
Constrastive approaches work by trying to maximize the similarity between the identical inputs semantically for instance learning two augmented views of the same image. The sub-categories of this approach are negative sampling, clustering, knowledge distillation, and redundancy reduction. More details of this approach will be described in a different article.
Evaluation Matrix
In SSL, the performance evaluation is usually conducted while doing transfer learning in the downstream task. Assessing the performance of transfer learning would estimate the generalization of the pre-trained model. Some common quantitative evaluations are linear probing, K nearest neighbors (KNN), and fine-tuning. Besides that, there is also qualitative evaluation. It can be done by visualizing the features to derive some insight. Some popular techniques are kernel visualization and feature map visualization.
Challenges and future directions
SSL is a relatively new branch of technology both in computer vision and remote sensing hence there is still much room for improvement and challenge to tackle. According to the reference paper, it can be summarized as follows:
- Model collapse. This is still a main challenge, particularly for modern contrastive learning. For instance, SimSiam gets collapsed easily in earth observation data. Future work could be to explore the theoretical foundations to answer why the model collapsed in remote sensing data.
- Pretext tasks and data augmentation. This topic is a very important role in SSL since it corresponds directly to what important information and invariance should be learned by the model. Common computer vision benchmarks may not cover multispectral imagery. Therefore, more studies are still needed to better understand which tasks and augmentation methods work for different types of remote sensing data.
- Pre-training datasets. Pre-training dataset is still an issue in remote sensing because of the limited data and bias toward the tasks of the datasets. It could be worth examining the necessity of self-supervised pre-training on large-scale uncurated datasets.
- Multi-modal/temporal self-supervised learning. Multi-modal/temporal data is one of the important aspects of remote sensing and deep learning. It allows us to perform big data analysis. However, at the same time, it would bring more complexity to the model to be trained. In this case, there need more studies to balance different modalities or time stamps.
- Computing efficient self-supervised learning. Big pre-training data in SLL requires huge computer resources. One could do research more about optimization such as reducing the computational cost.
- Network backbones. Currently, transformer or ViT has become more popular with its promising results. It is worth to explore more for remote sensing images.
To wrap up, self-supervised learning is a promising strategy to learn remote sensing data. Considering that it is very costly to annotate remote sensing data, SSL can be done without annotation. Furthermore, SSL can be divided into sub-categories: generative, predictive, and contrastive. SSL in remote sensing data is relatively new. Hence there is still much room for improvement.
I hope that will be useful. Thanks for reading. :D
