Member-only story
Working of Encoder-Decoder model
Sequence-Sequence LSTM model
LSTM and GRU models are variants of RNN. The RNN models are much easier to understand when compared to LSTM and GRU units. The beauty in understanding base concept is that, the learnings can be leveraged into LSTM and GRU units
There are many types of RNN/LSTM models and the most popular among them is the Seq2Seq model.
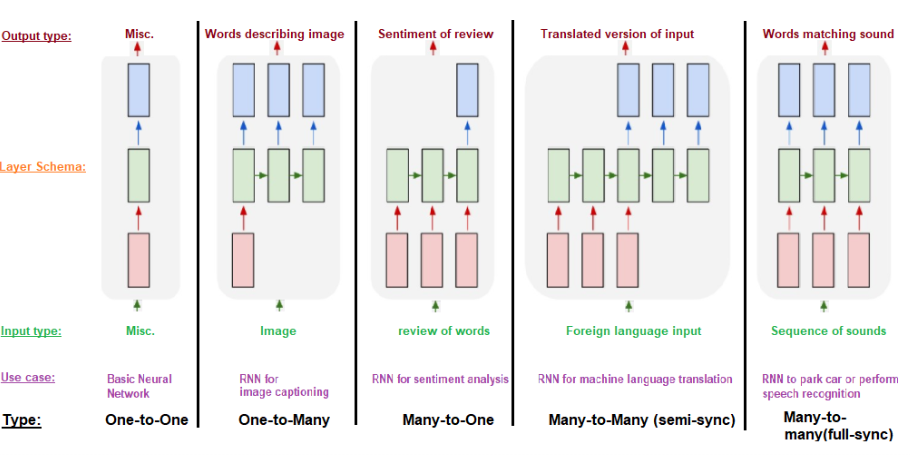
There are two types of Seq2Seq models — the Seq2Seq model of the same length and the Seq2Seq model of different lengths.
The architecture of the model depends on the type of use case, which is to be solved. Sequence models have gained traction in the past 5 years and it’s been very active research of study, even the GPT models — on which ChatGPT was implemented using the concept of Transformers and BERT, which is based on Self-Attention model — it is based on Attention models — which uses the base of Encoder-Decoder sequence models.
The problems like Machine Translation, Question Answering, Creating Chatbots and Text Summarization could also be solved using Encoder-Decoder sequence models.
Let’s consider a problem of Machine Translation (Translating a text from one language to another) to understand the architecture of Encoder-Decoder model and how they are built. Typically Neural Networks are used…

