
 Logo:
Logo:  Areas Served:
Areas Served: AWS Athena and Glue a Powerful Combo?
Last Updated on April 3, 2024 by Editorial Team
Author(s): Harish Siva Subramanian
Originally published on Towards AI.
AWS Athena is a serverless interactive query system. It means we dont need to manage any infrastructure behind them. They can be really handy if we want to perform some infrequent queries.
Also, we don't need to scale up or down in case the load increases. We just need to submit the query and it runs like a charm!!
Athena works with the data stored in S3. We know the data stored in S3 is very cheap and they are highly available. In Athena, they use an ANSI query format. So if you are familiar with the Standard SQL queries, you are good to go!!
Athena supports a variety of formats like JSON, CSV, Avro, ORC, and Parquet. The ORC and Parquet are columnal storage and they are famous in the Big Data world because of their efficient storage.
The pricing for Athena is based on a per-query basis. So it will be very cheap for infrequent query operations.
Another thing to note in Athena is we need to specify the output S3 location where the output of the query would get stored.
First things first, load the sample data into the S3 bucket. The sample data used in this article can be downloaded from the link below,
Fruit and Vegetable Prices
How much do fruits and vegetables cost? ERS estimated average prices for over 150 commonly consumed fresh and processed…
www.ers.usda.gov
First let’s create bucket and upload the downloaded file to the bucket.

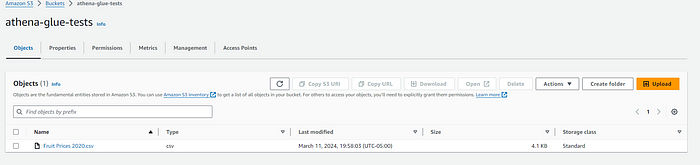
From the above image, we can see the file after being uploaded.
Glue Crawler Setup
The next step is setting up a Glue crawler to extract the schema of this file and create a database.
- Go to the AWS Glue Console.
- Create a new Glue Crawler to discover and catalog your data in S3. This is necessary for Glue to understand the structure of your data.
- Create a Glue Job to perform ETL operations on your data. Define your source and target (S3) connections and transform your data as needed.
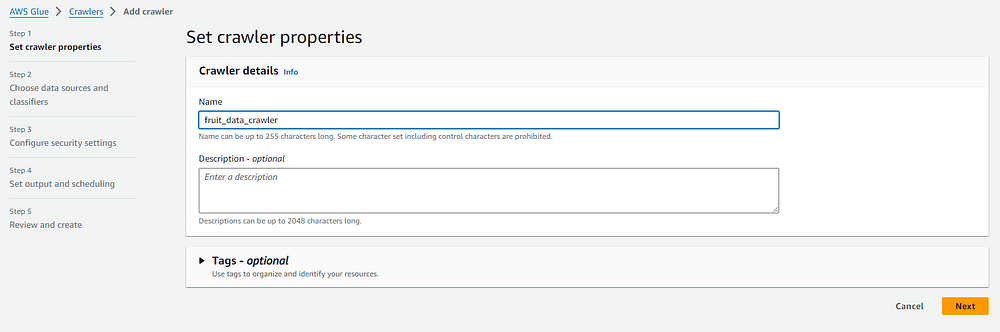

In the source, we choose the the S3 option. We have the following options to choose from,
Once this is done, there will be a step to add the IAM role. This step is very important. We need to have the S3 read permissions to read the data from S3 bucket.
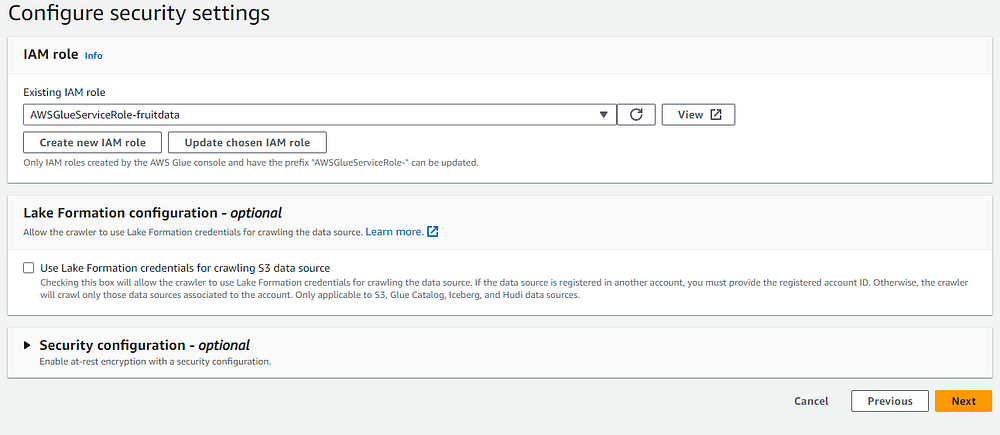
Here create a new IAM role or use an existing role. If you are using an existing role, make sure that the role has the S3 Read permission.
Next step we want to specify the database. In our case we dont have a database and so we create one by clicking Add New Database.
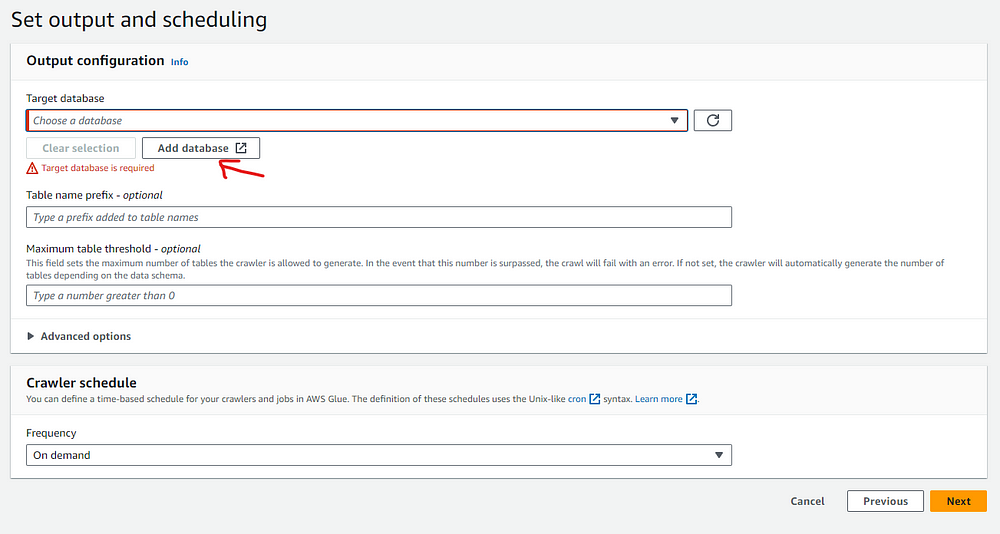
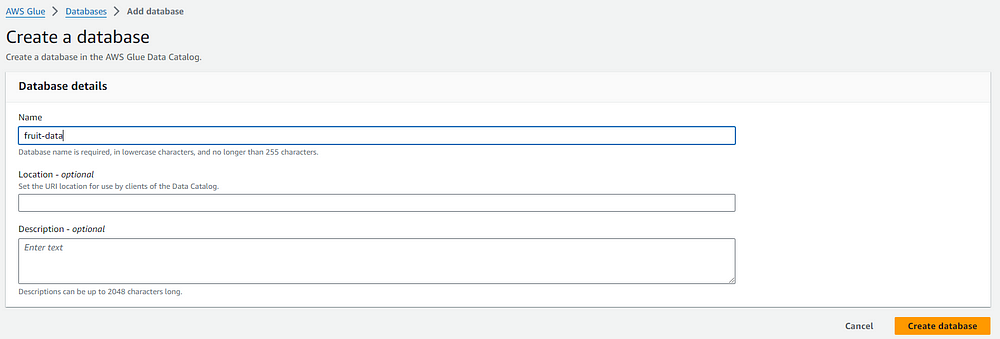
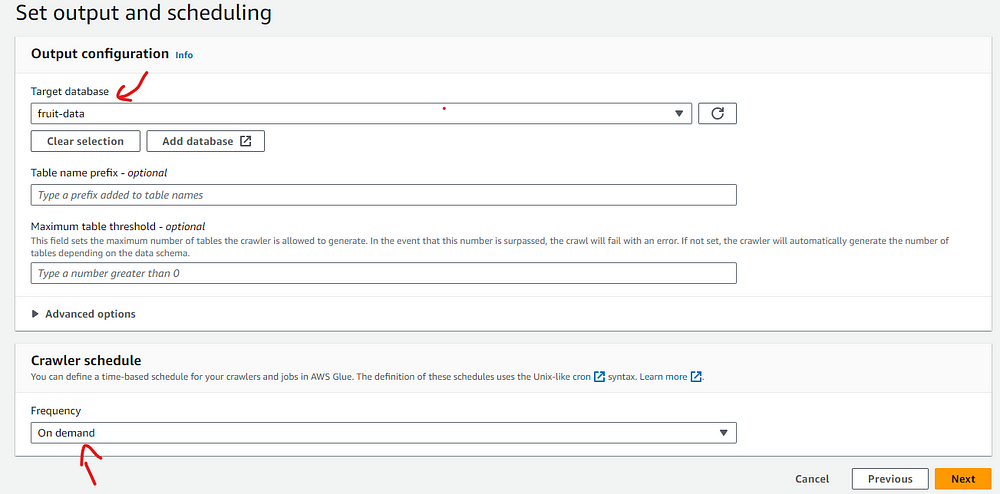
We can see the database that we created pop up. Now we need to choose the schedule in the drop-down below. For this article, we will run the job on demand.
That is click Review and create!!

We can see the fruit_data_crawler we just created.
Now let’s run the crawler by selecting them and clicking Run

Once the crawler is done running, we can now see the database created inside the Glue.

Athena Setup
Go to the AWS management console and open Athena.
In the Athena, go to the Query Editor Window.

In the image above, we can see the datasource in the left side automatically showing as the AwsDataCatalog and the database showing as fruit-data that we created above.
When we runt he above query we see an error because we have to specify the output where the Athena results would be stored. If not we would get an error!

Click on the Edit Settings and specify the s3 output location.
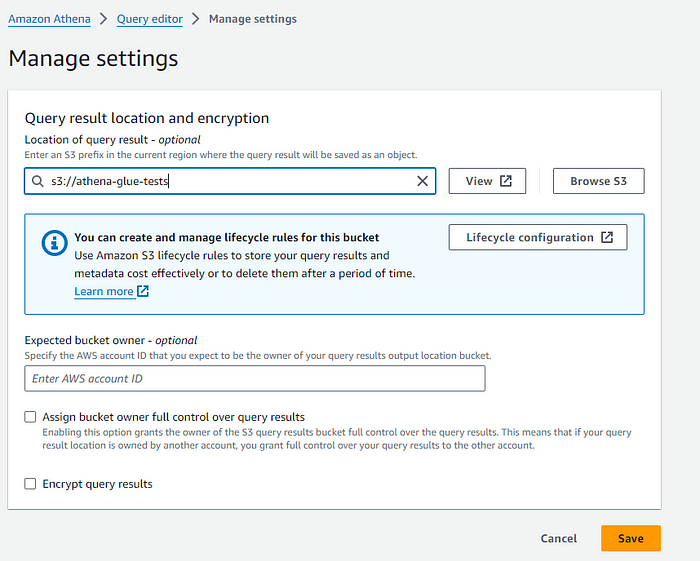
Here I am specifying the same s3 bucket for the output!

When we run it this time, we can see the results are specified here. Also the results would be saved in the S3 location. AWS automatically creates a new folder based on the date and stores the output as a CSV file.
That is it!! Thank you for reading!!
If you like the article and would like to support me, make sure to:
- U+1F44F Clap for the story (50 claps) to help this article be featured
- Follow me on Medium
- U+1F4F0 View more content on my medium profile
- U+1F514 Follow Me: LinkedIn U+007C GitHub
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts
Popular posts

 for 2021")



Updates

Recent Posts

