Action Detection Models— what are they and how can I create one using MVI?
Picture this: a world where every movement, gesture, and moment is meticulously observed and understood. In the realm of action detection, this futuristic dream is fast becoming a reality. As technology continues to evolve at an unprecedented pace, we find ourselves on the brink of a revolution that promises to transform the way we interact with the digital world.
In this article, we will explore Maximo Visual Inspection (MVI), learn about action detection, discuss some real world use cases and do a walkthrough demonstration of how to create your own model in MVI.
What is Maximo Visual Inspection?
Maximo Visual Inspection, otherwise known as MVI, is IBM’s easy to use, no-code tool that enables technical and non technical users to create image classification, object detection and video detection models. Through training on large and enriched datasets, these models are able to learn complex visual patterns that difficult to detect for the human eye.
What is Action Detection?
Action detection is the task of identifying and localizing specific human actions or activities in a video sequence.
Here are the three key components of action detection:
- Action Recognition: this task involves recognizes what specific action (class) is taking place in a video. This could include actions such as walking, running, jumping, dancing, or more complex activities like playing soccer, cooking, or assembling objects.
- Temporal Localization: this task involves locating the temporal boundaries of each action within the video. More explicitly, this means figuring out when a specific action starts and ends in the video. This information is crucial for understanding the timing and duration of actions.
- Spatial Localization: this task involves spatial localization, which identifies where the action is happening within the video frame. This can involve drawing bounding boxes around the people or objects performing the actions.
How is it different than object detection?
Often times, people assume action detection is very similar to object detection. However, there is nuance to this. While tradition object detection focuses on identifying and localizing static objects in images or videos, action detection takes it a step further by capturing the dynamic aspect of actions and activities performed (often times by humans) in a video.
Action detection should be employed when the change of position of an object is significant, not just the presence of an object. So for example, if you were looking at a traffic camera, and you wanted to note whether there is a green light — for this you could use simple object detection. However, if you wanted to monitor something more complex such as traffic, measured by the movement of cars, you would need to employ action detection.
What type of deep learning architecture can support Action Detection?
Several types of deep learning architectures have been researched and explored for developing action detection models.
There are a series of convolutional networks (CNs) including:
- Two-Stream CNNs: Two-Stream CNNs consist of two separate streams of Convolutional Neural Networks (CNNs) — one for spatial information (RGB frames) and another for temporal information (optical flow or motion frames). These streams are combined to capture both appearance and motion cues, making them effective for action recognition.
- 3D CNNs: 3D CNNs extend traditional 2D CNNs to handle spatiotemporal data directly. They take video clips as input and learn to model both spatial and temporal features jointly. Models like C3D and I3D (Inflated 3D ConvNets) are popular choices for action detection.
- Temporal CNs: TCNs are one-dimensional convolutional networks designed to capture temporal patterns in sequential data. They have been adapted for action detection tasks by processing video frames sequentially to learn temporal dependencies.
Another popular framework for action detection is a Structured Segment Network (SSN). This framework utilizes stage structures (so starting, course and ending) via structured temporal pyramid pooling. This framework is commonly used to detect short, temporal activity or actions in videos and is best at classifying short bursts of time that have a strong sense of directionality.
An example of stage structures and the temporal pyramid mechanism can be seen below:

Here someone is tumbling and the action being detected is the person doing the tumble. You can see the network temporally groups the different frames into three sections: yellow, green and blue. Yellow is where the person is getting ready to tumble, green is where the actual action of tumbling is taking place, and blue is after the action has been completed, with all of this occurring in less than a minute.
Some real world use cases and an example using Maximo Visual Inspection (MVI):
There are several use cases for action detection models. Whether you want to analyze congestion in traffic, detect sports players actions or activities, enhance surgical video analysis, or monitor consumer shopping behavior, there are several applications.
Let’s dive into an example with Tennis — creating a model in MVI:
In the steps below I will demonstrate how to build an action detection model in MVI. For the purpose of this demonstration, we will be creating a model that can detect and distinguish a forehand shot, a backhand shot and an an overhead shot in sport of tennis.
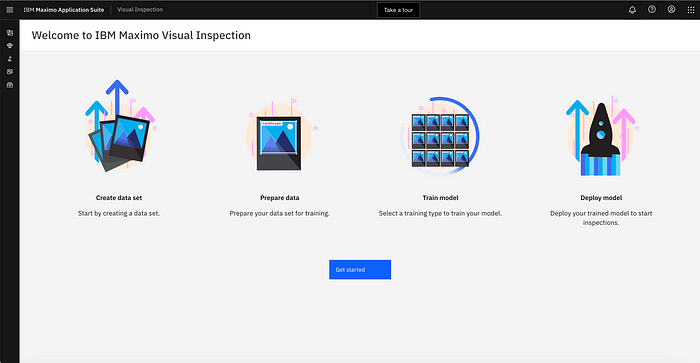
As you can see pictured below, the home page of MVI lists out the steps of model creation, from creating a data set, to preparing data, to training the model and finally deploying the model.
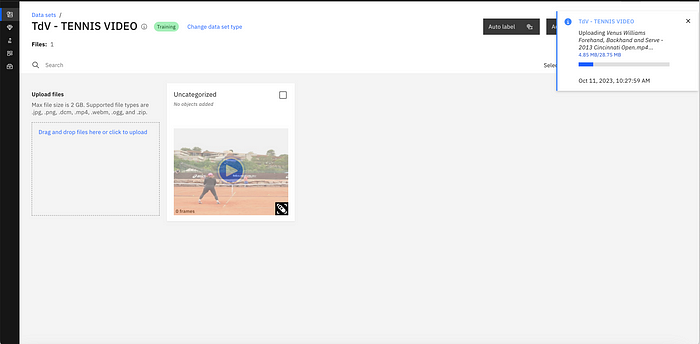
Step 1: Uploading data.
Through MVI’s easy drag and drop method, you can upload videos within seconds.
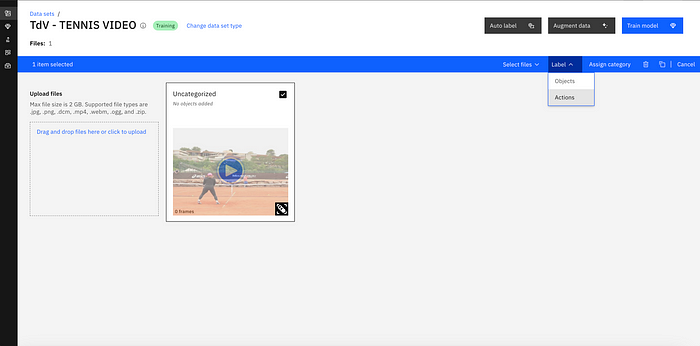
Step 2: Labeling the data.
You can simply click on the top right corner of the data item, click on the dropdown Label, and select Actions.
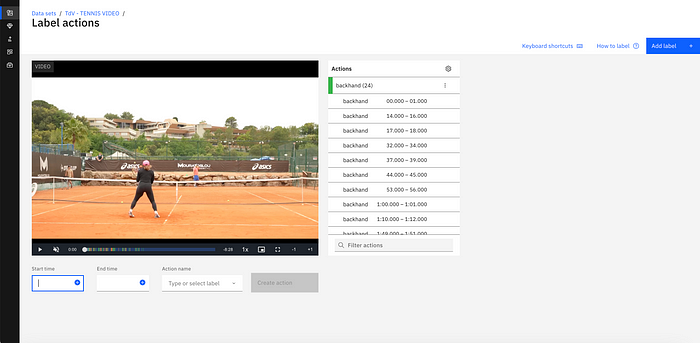
You are then brought to this page where you can enter a Start Time, End Time and Action name, aka the class to create an action in the video. In our case, the Action name is either backhand, forehand or overhead.
Step 3 (Optional): Augmenting data or Auto labeling.
In MVI you can easily augment your dataset to expand and enrich the training. Augmenting options include: blurring, horizontal and vertical rotations, coloring, cropping and more. Furthermore, you can use an already deployed action detection model to auto-label data in your new training set to save significant time in labeling.

Step 4: Training the model.
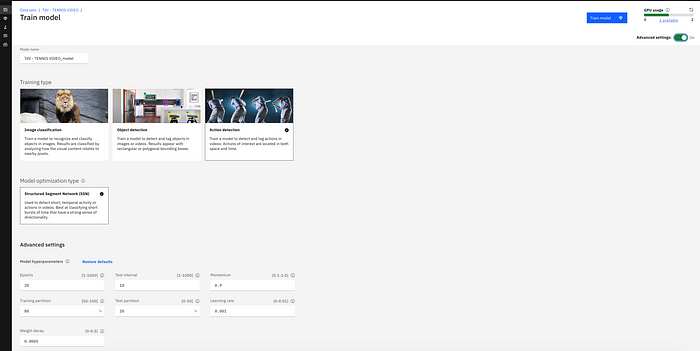
In MVI, you have the ability to train your model at the click of a few buttons. Currently the model architecture provided on the platform for action detection is an SSN. You do have the flexibility to choose model hyperparameters in Advanced Settings.
Step 5: Deploying the model.
Once your model is trained and you have validated the performance, you are able to deploy it by clicking the ‘Deploy’ button in the top right corner of the model home page. After deployment, you are able to see similar performance metrics (as the ones pictured below) as well as use the model to inference. Inferencing can be done either via API or via a drag and drop method in the User Interface.
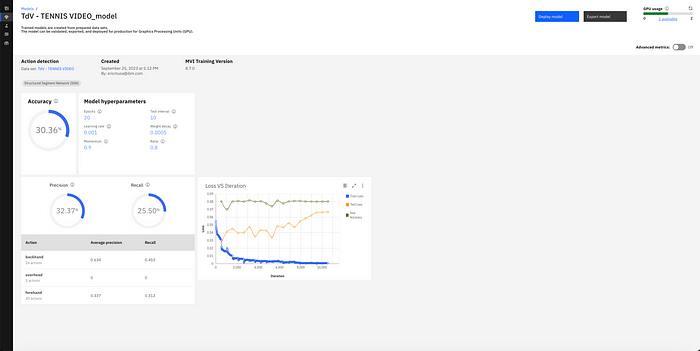
You may notice that the performance is fairly low for this model, however, this can be explained by the fact that I only used one video in the training set. Furthermore, for the overhead class, I only had 5 instances which resulted in a 0 average precision and recall, tanking the overall performance of the model. You can see that backhand, has an average precision of 63.4%, with only 24 action examples.
After deploying the model, you are able to perform inference in the UI or call the model via API.
If you are interested in learning more about MVI, you can visit IBM’s documentation here. Additionally, if you are curious in MVI’s image classification and object detection capabilities, check out my peer’s blog here.

