Feature Platforms — A New Paradigm in Machine Learning Operations (MLOps)

Operationalizing Machine Learning is Still Hard
OpenAI introduced ChatGPT. DeepMind launched AlphaFold, which can accurately predict 3D models of protein structures, accelerating research in nearly every field of biology. The United States published a Blueprint for the AI Bill of Rights. The growth of the AI and Machine Learning (ML) industry has continued to grow at a rapid rate over recent years. However, while many teams want to be a part of this growth and reap the benefits that come from these technologies, operationalizing a machine-learning system is still a difficult task. According to a McKinsey study, an estimated 88% of machine learning models are never taken into production. When we examine the hidden technical debt in machine learning systems, as illustrated below, it is understandable why most machine learning models never get deployed.

More money, more problems — Rise of too many ML tools


People often believe that money is the solution to a problem. In regards to the challenge of operationalizing machine learning, this problem prompted a surge of investment to find a solution. While this investment has driven progress and innovation in the field, it has also given rise to a new problem.

This trend led to the proliferation of companies developing tools to address different pain points in the machine learning lifecycle. While having multiple options may seem advantageous, it can create challenges for organizations tasked with managing these tools and applications. Additionally, imagine being a practitioner, such as a data scientist, data engineer, or machine learning engineer, who will have the daunting task of learning how to use a multitude of different tools. This complexity is compounded even further by the need to manage data across hybrid and multi-cloud environments.
Where do we go from here? — Data Platforms
Andreessen Horowitz, a prominent venture capital firm, predicts that the abundance of new tools in the machine learning industry will eventually lead to consolidation around a data-centric approach, prioritizing advanced data management. This shift in focus is expected to result in the emergence of data platforms that seamlessly integrate and interoperate with one another, effectively elevating data management beyond a collection of disconnected tools and fragmented datasets.
Andrew Ng, who is the founder & CEO of Landing AI, founder of DeepLearning.AI, General Partner at AI Fund, chairman and co-founder of Coursera, as well as an adjunct professor at Stanford University, holds a similar view regarding the shift towards a data-centric approach. He advocates for the following:
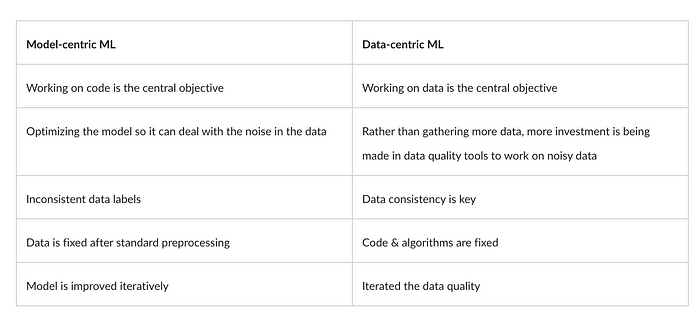
“Instead of focusing on the code, companies should focus on developing systematic engineering practices for improving data in ways that are reliable, efficient, and systematic. In other words, companies need to move from a model-centric approach to a data-centric approach.”
— Andrew Ng
To gain a deeper understanding of this topic, Andrew shares his insights here, and he weighs in on where we are today (Model-centric ML) and where we should be going (Data-centric ML).
So how does this data-centric approach fit in with Machine Learning? — Features
In machine learning, a feature is data that is used as the input for ML models to make predictions. There are many types of features, as shown below:
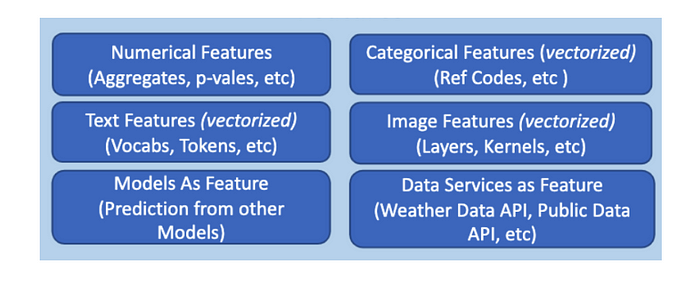
The easiest example of a feature is the column within a dataset.
Data scientists and data engineers often spend a large amount of their time crafting features, as they are the basic building blocks of datasets. They also serve as fundamental components of predictive models, for the quality of the features will have a major impact on the quality of the insights gained from an AI model.
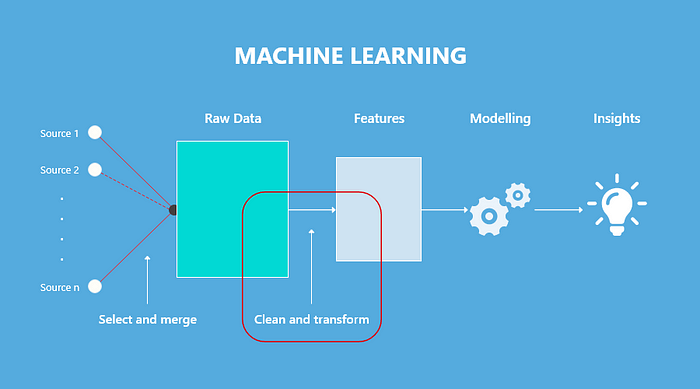
The Next Frontier? — Feature Platforms
The Rise of Feature Stores — In 2021, the machine learning industry witnessed the emergence of feature stores, a solution that enables teams to store and share features. The idea behind feature stores originated from Uber’s Michelangelo project and has since been embraced by various organizations, including Doordash, Facebook, LinkedIn, Inuit, and many others. Additionally, this development has inspired other open-source initiatives like Feast.
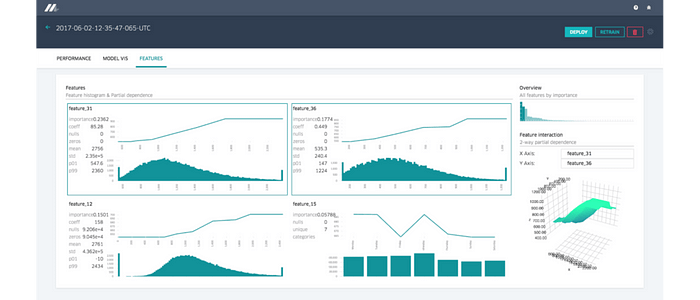
The Emergence of Feature Platforms — As we move into 2023, we are witnessing the evolution of feature stores into feature platforms, which oversee the entire feature engineering workflow. A feature platform manages the existing data infrastructure and facilitates continuous transformation, storage, and servicing of data for machine learning applications. It also handles metadata, monitoring, and governance related to data management. Chip Huyen, the author of Designing Machine Learning Systems, delves into the details of feature platforms in her blog post titled “Self-Serve Feature Platforms: Architectures and APIs” In the post, she highlights the differences between feature platforms and feature stores.
Today, feature platforms typically consist of the following components:
Feature Design
Feature Catalog
Feature Computation Engine
Feature Store
Feature Governance
Feature Monitoring
Feature Design
Users can design feature definitions with their tool of choice
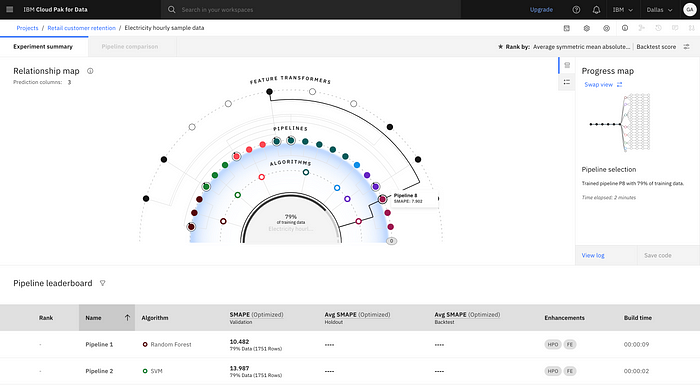
Feature engineering can be a tedious and time-consuming process that requires data scientists and data engineers to manually extract and engineer features from raw data. A feature platform should enable individuals within an organization to reuse pre-engineered features made by their colleagues in their modeling tools, such as notebooks, graphical builders, or AutoML tools. This would eliminate duplicate work and save time and effort for the team.


Feature Catalog
Users can manage feature definitions and enrich them with metadata, such as tags, transformation logic, or value descriptions.

MLOps teams often struggle when it comes to integrating into CI/CD pipelines. For MLOps teams, the core challenges lie in figuring out how to test and govern data. To ensure reproducible automated builds, a practice commonly found in DevOps, MLOps teams need to understand and manage both the code and the data (features). Tools like Git and Jenkins are not suited for managing data.
This is where a feature platform comes in handy. By capturing metadata, such as transformations, storage configurations, versions, owners, lineage, statistics, data quality, and other relevant attributes of the data, a feature platform can address these issues. This information allows data scientists and engineers working on different parts of the project to understand the features of their teammates and create feature pipelines that are consistent throughout the AI lifecycle.


Feature Computation Engine
Users can transform batch, streaming, and real-time data into features

To productionize a machine learning system, it is necessary to process new data continuously. This ensures that the models can make predictions based on the latest information available. A feature platform should automatically process the data pipelines to calculate that feature. To accomplish this goal, many feature platforms leverage engines (e.g. Spark, Flink, etc.) to compute features into the following:

A feature platform should be flexible in supporting the different computation engines as different configurations are needed to ingest and compute the features. In the end, the choice of the type of features needed by the team will depend on the use case and requirements.
Feature Store
Users can store and serve features across offline and online data stores.
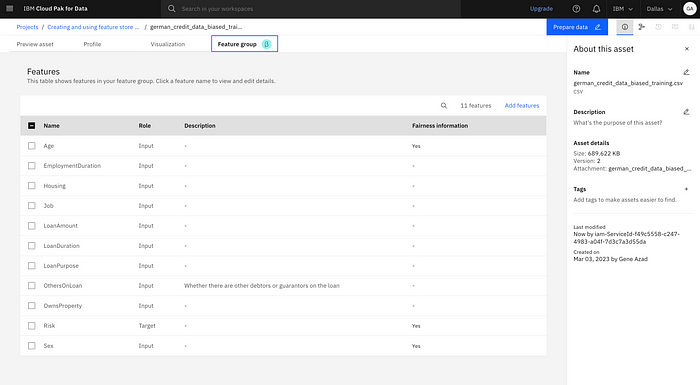
One of the major pain points in building ML models is dealing with training-serving skew, which refers to the situation where the data used to train a machine learning model is different from the data used to make predictions in the deployed model. Training-serving skew can result in model performance problems that are both challenging to diagnose and can have negative consequences. This problem often arises because the same batch features used during training are often not available when serving the model online in real time. This is what happened to Monzo Bank:
When shipping tabular-based models, we kept finding that many of the features we would input into a model while training it were not readily available in our production infrastructure. — Monzo Bank
To solve this issue, a feature store connects the different ML pipelines and creates the synchronization of features from training and serving. A feature store accomplishes this through a dual-database system comprised of the following:
- Offline store — where features are stored and processed in a batch manner (e.g Postgres, DB2)
- Online store — where features are typically stored in a distributed database that can handle high volumes of read and write requests in real-time (e.g. Redis)
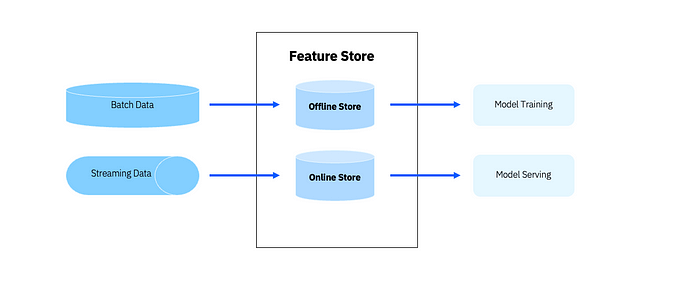
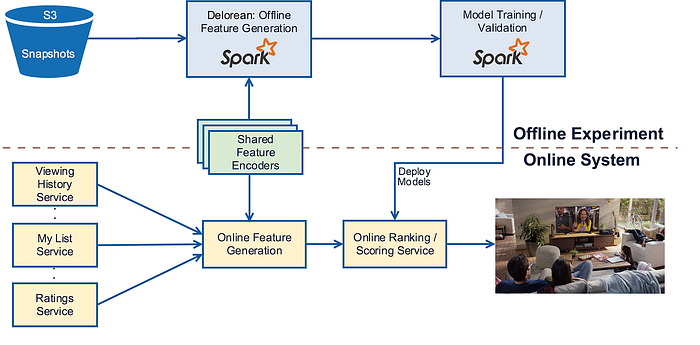
So say you ingest new features into your online store, you should be able to append those features to the offline store to keep both stores in sync. If you want to learn more about the subject, check out how Netflix uses this design to experiment faster and reduce the time to production for an idea.
Feature Governance
Users can easily understand, monitor, and govern features throughout the feature lifecycle.
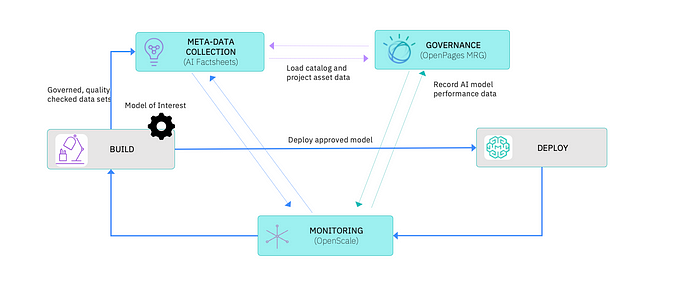
As AI scandals continue to emerge (such as gender bias accusations against Apple Card, wrongful accusations of fraud by the Dutch tax authority, and many others), governing AI is becoming a major concern. It begs the question: how do we govern AI? A feature platform can help address this issue by enabling teams to understand, control, and monitor the features that are being used in AI models. By breaking open the black box of AI, teams can identify issues with poor-quality or biased models and take appropriate action.
In the event of a problematic AI model, it can be challenging to determine the root cause. Imagine you have a poor-quality model, a model with bias, or a model with a disastrous outcome. How do you figure out the cause? Imagine people asking you why your AI is saying some ‘crazy and unhinged things. With a feature platform, teams can monitor the features being used and investigate any unusual behavior. This level of visibility and control can help prevent disastrous outcomes and build trust in AI systems. In short, a feature platform can help answer tough questions when people ask why an AI is producing unexpected or problematic results.
Can a team explain why these isssues are happening?
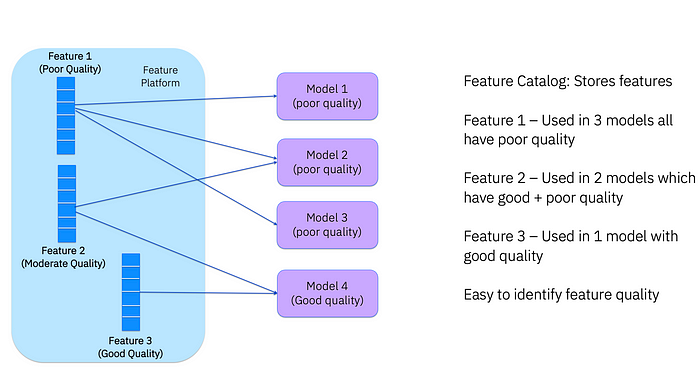
A feature platform empowers users to identify the root cause of a poor-quality model by providing valuable context in the form of metadata about the features. This metadata can help teams to decide which features to approve and share for production, and to ensure that the features comply with rules, regulations, and policies set by the organization or other entities (e.g. government). With these capabilities in place, teams can better understand, trust, and use their models with confidence. The ability to explain why a model is behaving a certain way is critical in gaining trust and accountability in the decision-making process.
Feature Monitoring
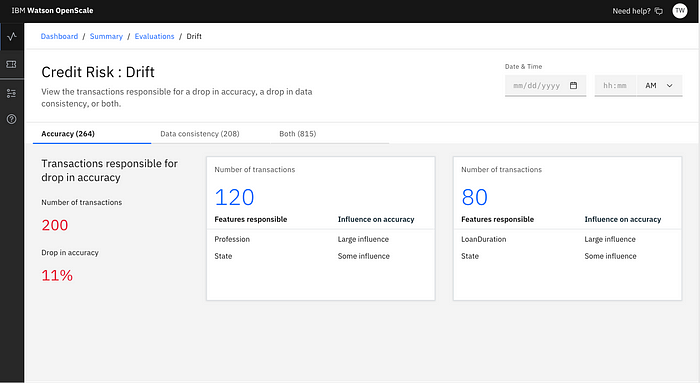
To ensure the performance and accuracy of machine learning models, continuous monitoring is a crucial aspect of feature platforms. As models are deployed into production, the feature data distribution used in the model can change over time, leading to feature drift. A feature platform should provide users with the ability to continuously monitor feature quality, usage, staleness, overlap, and provide recommendations and rankings for features. By having these monitoring capabilities, teams can quickly diagnose problems and react accordingly when a model degrades in performance. This level of continuous monitoring is critical in maintaining the accuracy, fairness, and overall performance of machine learning models.
Why does this all matter?
If we want to see more progress in the AI/ML field, it is essential to address a core issue: 88% of machine learning models are never taken into production. Feature platforms can help to reduce this number by addressing many of the pain points that ML teams faced in the past.
Past — Prior to the era of feature platforms, these teams had to contend with a range of challenges, including:
Pain Points:
Time-consuming feature engineering
Limited collaboration and knowledge sharing
Inconsistency in Features
Poor Feature Quality & Governance
Lack of Feature Monitoring
Present (& Future) — Today, we are starting to see some of those pain points go away. As the ML space continues to grow in 2023 and beyond, feature platforms will likely play an even more crucial role in the space. Features are food for AI. If we want to quickly operationalize healthy AI models, we need to understand and control what we are feeding the models. In addition, we need to monitor what happens to the model afterward. A feature platform brings us closer in that direction, for it allows teams to easily create, store, discover, understand, govern, and monitor the features being used within an organization. As result, teams will benefit in the following ways:
Benefits:
Efficiency — Teams will be able to reuse features
for modeling and inferencingFlexibility — Teams will be able leverage features where ever they may lie and in the tool of choice
Governance — Teams will be able understand, govern, and monitor their ML features
Feature platforms will elevate teams to new heights, help teams operationalize ML models with speed, and bring about a new era of innovation.
How to Get Started?
The feature platform mentioned above was made leveraging IBM Cloud Pak for Data, an analytics platform that helps prepare data for artificial intelligence. More details on the subject can be found here.