Create autonomous & continuous AI Training — MLOPS on steroids.
Your company created multiple models, and the maintenance and redeployment workload are exploding, taking up the majority of your time? Continuous training is the solution.
Who should read this article: Machine and Deep Learning Engineers, Solution Architects, Data Scientist, AI Enthusiast, AI Founders
What is covered in this article?
This article explains how to build a continuous and automated model training pipeline. It is openly discussed and adaptable for any unified AI platform. This article will not explain how to deploy or train a machine learning model. It focus on the monitoring and retraining policies that are keen for continious training. The provided code to this article refers to IBM’S CP4D and demonstrates how a continuous training could be implemented. But it’s interoperable on any cloud like Azure, AWS or GCP.
Why It’s needed and what is the concept of continuous training?
Everything in our complex world is subject to change. Machine learning models are no exception and are subject to a natural evolutionary process. So it could happen that your machine learning models become stale. Stale means that the accuracy of your model felt under a predefined threshold:

This ends with two significant challenges. First of all it is important to detect a stale model. Second it is important to act and doing a redeployment after certain model evaluation steps. The detect and act approach is covered in the continuous training.
Other factors to consider include changes in data distribution, feedback from end-users, the age of the model, its complexity, and any legal and regulatory changes that may impact its validity. Regular evaluation of these factors can help to determine if a model needs retraining to maintain its effectiveness.
Fundamentals of continuous training
For an automated and continuous training of AI models it’s fundamental to have:
- Automated ETL Pipelines to collect and organize data
- Automated Preprocessing Steps to clean your data
- Automated Training Loop (Train, Evaluation) to retrain the model
- Automated Deployment to serve the model
- Monitoring / Retrain Policy
The picture below illustrates the process and necessary steps that are needed to build a continuous training pipeline.

On the left corner we have the Jupyter Notebook that contains the code to train our AI model. The code is designed to run our code autonomously so that it can be triggered via CronJob to rerun by a policy. Trained model are automatically deployed. Advice: Important is that your deployment instance is able to versioning models so that it is easy to roll-back in case of emergency.
The policy is one of the main concepts in continuous training because it defines when a new model is retrained. It’s recommended to think careful about these policies because not all of them working for each model. Some examples:
- model falls below a predefined threshold like accuracy, recall, precision, sensitivity, F1, MRR, RSE, etc. (models gets stale)
- tremendous amount of new data. A threshold can be set. For example: retrain model if we receive 1000 new records
- consider certain time periods. For example you are just intrested to use the last 6 months of data.
- the model starts to drift, shift or get’s biased. You can use OpenScale to monitor these events.
in general policies can be combined and can become very complex. When you are new to policies you should always start to think about how you can measure the success of your models. This helps you to define a good policy. Because the goal of the policy is to ensure the high effectiveness of the models. Advice: “Ensure to keep policies simple as possible .“
Monitoring predictions makes the difference between good a bad implementation of continuous training. Keep in mind that policies just work with a good monitoring approach.
Let’s talk about monitoring and the concept of feedback data
The monitoring approach logs useful information of your AI model. That are the prediction itself and the user behaviour. Means what the user did with the prediction. The user behaviour is called feedback data. Feedback data are the key to understand and learn from the user behaviour about the effectiveness of your AI.
We have two concepts of feedback data — implicit and explicit feedback data.
- Implicit feedback data are obtained by the operational process — the system tells you if the user follows the prediction or not.
- Explicit Feedback data are obtained by user feedback — the user tells you if a prediction was correct or not.
How to start monitoring?
IBM OpenScale is a useful tool for monitoring the performance of your model. It provides direct opportunities to monitor quality, fairness and drift. In addition it can become a critical part of automating the process of retraining. Such as scheduling retraining of your model, and comparing multiple models.
Openscale provides you an insights dashboard. That helps you to monitor your models in realtime. In addition it provides an open API that can be integrated into any existing dashboard. Here are some example of the insights dashboard:
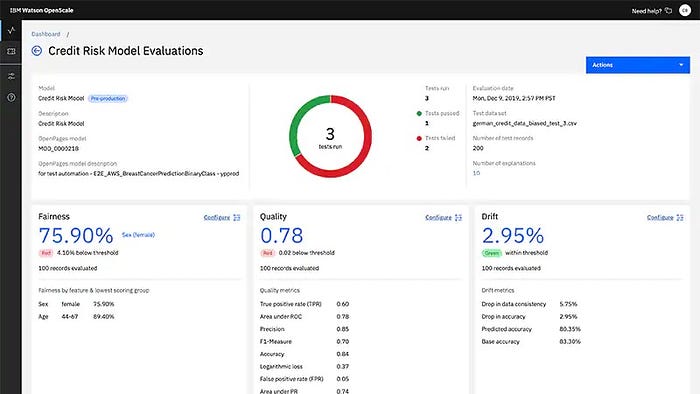
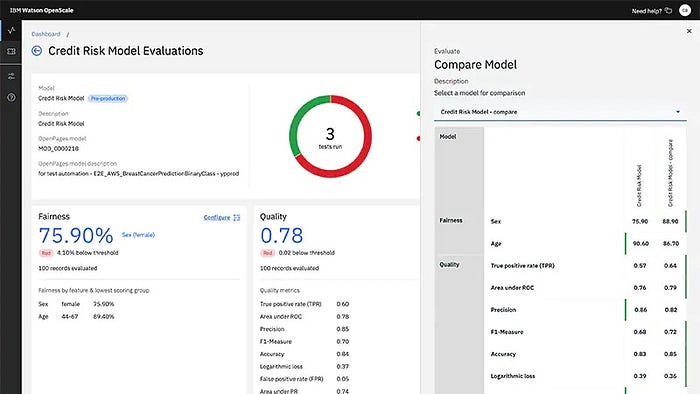
You can also use the IBM OpenScale to monitor the fairness and explainability of your model and get alerts on any drift that might occur on your model, and also you can use the OpenScale to deploy counterfactual explanations and adversarial samples.
When does it not work?
The policy don’t cover every scenario and from time to time it is necessary to have a human to review the models. Especially and this is important if you get some feedback for enhancement from the stakeholder. These are actions that have to be peformed by a human.
Monitoring doesn’t mean you don’t need to listen to your customers and stakeholders at all. Always look at both sides.
Time for hands-on monitoring with OpenScale:
Below you will find different examples of projects that using OpenScale for monitoring.
- Tutorial 1: Working with Watson Machine Learning engine
- Tutorial 2: Working with Azure Machine Learning Studio engine
- Tutorial 3: Working with Azure Machine Learning Service engine
- Tutorial 4: Working with Amazon SageMaker Machine Learning engine
- Tutorial 5: Working with Image-based models
- Tutorial 6: Working with Text-based models
- Tutorial 7: Working with Regression models
- Tutorial 8: Working with Custom Machine Learning Provider
Helpful links: https://github.com/IBM/watson-openscale-samples
Basic Example
This is a basic example of how you can use IBM OpenScale to monitor an AI application. In this example, you first connect to OpenScale using the APIClient class and your API key. Then, you register your AI model by providing the model’s unique ID and deployment details such as the name, description and URL of your endpoint.
from ibm_ai_openscale import APIClient
from ibm_ai_openscale.engines import *
# Connect to OpenScale
ai_openscale = APIClient(api_key='YOUR_API_KEY')
# Register the model
deployment_details = {
'name': 'My Model',
'description': 'This is my AI model',
'deployment_type': 'web',
'url': 'https://mymodel.com/predict'
}
deployment = ai_openscale.deployments.create(artifact_uid='YOUR_MODEL_UID', name='My Model', description='This is my AI model')
# Get the deployment_id
deployment_id = deployment['metadata']['guid']
# Create a subscription
subscription = ai_openscale.subscriptions.add(
deployment_id=deployment_id,
name='My Subscription'
)
# Monitor the performance of the model
performance_monitor = ai_openscale.monitors.add(WatsonMachineLearningMonitorForDeployment(subscription=subscription))Once the model is registered, you can create a subscription and attach a performance monitor to it using the WatsonMachineLearningMonitorForDeployment class. This will allow you to monitor the performance of the model over time, including metrics such as accuracy, fairness, and drift.
What you have learned:
You have learned the fundamentals of a continuous learning pipeline and how you can implement a monitoring and policy approach. In addtion I presented you IBM OpenScale to monitore your models.
Congratulation — that’s it!
Leave a comment if you have any questions, recommendations or something is not clear and I’ll try to answer soon as possible.
Dont Forget to clapp — if you find that helpful:
Disclaimer: Opinions are my own and not the views of my employer.

