
 Logo:
Logo:  Areas Served:
Areas Served: 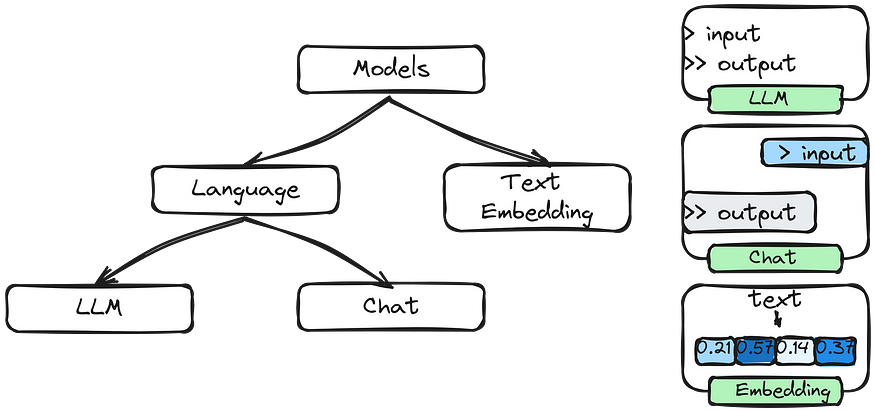
LangChain 101: Part 2ab. All You Need to Know About (Large Language) Models
Last Updated on November 5, 2023 by Editorial Team
Author(s): Ivan Reznikov
Originally published on Towards AI.
This is part 2ab of the LangChain 101 course. It is strongly recommended to check the first part to understand the context of this article better
(follow the author in order not to miss the next part) :
LangChain 101: Part 1. Building Simple Q&A App
In this article, I will introduce you to the basics of LangChain, a framework for building applications with large…
pub.towardsai.net
Don’t miss the next part of the Langchain 101 series:
LangChain 101: Part 2c. Fine-tuning LLMs with PEFT, LORA, and RL
All you need to know about fine-tuning llms, PEFT, LORA and training large language models
pub.towardsai.net
Or you can check out the full series:
LangChain 101 Course (updated)
LangChain 101 course sessions. All code is on GitHub. LLMs, Chatbots
medium.com
Models
The Models component is the backbone of Langchain. It is the core that is responsible for token generation that makes the tech feel magical.
In machine learning and data science, a black box that makes predictions is often called a model. There are different models, and one of them is a language model. Language models existed for some time but weren’t as popular as they got once ChatGPT appeared. One of the reasons is that the GPT-1 model was trained on a small amount of data. As the numbers after GPT grew, so did the amount of data, which led to the appearance of Large Language Models, or LLMs, as they are more often called.
The Models component allows the usage of different language models, including ChatGPT, GPT-4, LLAMA, etc. These models can be used for multiple tasks, most popular: answering questions and generating text.
The Models component is easy to use. To generate text, one can pass the model a prompt, and it will create a response. The same goes for translating a sentence or answering a question.
The Models component is also very versatile. You can combine it with other LangChain components to create more complex systems. For example, you could combine the Models component with the Prompts component to create a chatbot that can generate different kinds of creative text formats of text content like code or scripts, poems or musical pieces, letters or emails, etc. Combine the Models and Indexes components to create a search engine that can answer questions using information from various sources.
All the code (including colab notebooks) and extra materials are available on GitHub.
Overview
LangChain supports a variety of different models, so you can choose the one that suits your needs best:
- LLMs utilize APIs that take input text and generate text outputs
- Chat Models employ models that process chat messages and produce responses
- Text Embedding Models convert text into numerical representations
Tokenization
Tokenization breaks down human language into smaller units like words or subwords to convert text into machine-readable numerical representations. Further on, when we talk about text- or code- generation, we’ll understand it as different kinds of token generation.
Text generation
Say we want to generate the continuation of the phrase:
“Paris is the city …”.
The Encoder sends logits for all the tokens we have (if you don’t know what logits are — consider them as scores) that can be converted, using the softmax function, to probabilities of the token being selected for generation.

Read more about text generation:
How Does an LLM Generate Text?
This article won’t discuss transformers or how large language models are trained. Instead, we will concentrate on using…
pub.towardsai.net
.from_pretrained(<model>)
In many pre-trained language models, the tokenizer and the model architecture are designed and trained together. The reason for this coupling is that the tokenizer and the model architecture must be compatible to ensure consistent tokenization and decoding.
If the tokenizer and the model architecture were different or not synchronized, it could lead to tokenization errors, mismatched embeddings, and incorrect predictions.

API keys
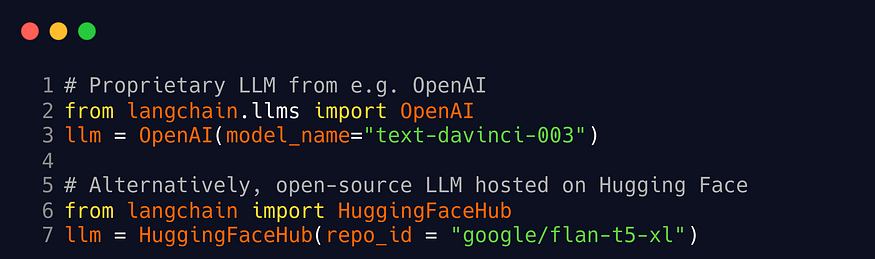
You will first need an API key for the LLM provider you want to use. We must choose between proprietary or open-source foundation models based on a trade-off between performance and cost.
Many open-source models are organized and hosted on Hugging Face as a community hub. Open-source models are usually smaller with lower capabilities than proprietary ones, but they are more cost-effective.
Examples: BLOOM (BigScience), LLaMA (Meta), Flan-T5 (Google), etc.
Proprietary models are closed-source foundation models owned by companies. They usually are larger than open-source models and thus have better performance, but they may have expensive APIs.
Examples: OpenAI, co:here, AI21 Labs, Anthropic, etc.
Embeddings
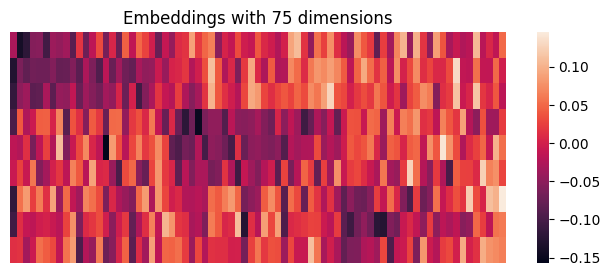
Embeddings are compact numerical representations of words or entities that help computers understand and process language more effectively. These representations encode the meaning and context of words, allowing machines to work with language more meaningfully and efficiently.
- OpenAIEmbeddings
- HuggingFaceEmbeddings
- GPT4AllEmbeddings
- SpacyEmbeddings
- FakeEmbeddings
Below, you can see the embeddings for the nine sentences of several topics. The heatmap values were presorted for better visualization.
- Best travel neck pillow for long flights
- Lightweight backpack for hiking and travel
- Waterproof duffel bag for outdoor adventures
- Stainless steel cookware set for induction cooktops
- High-quality chef’s knife set
- High-performance stand mixer for baking
- New releases in fiction literature
- Inspirational biographies and memoirs
- Top self-help books for personal growth
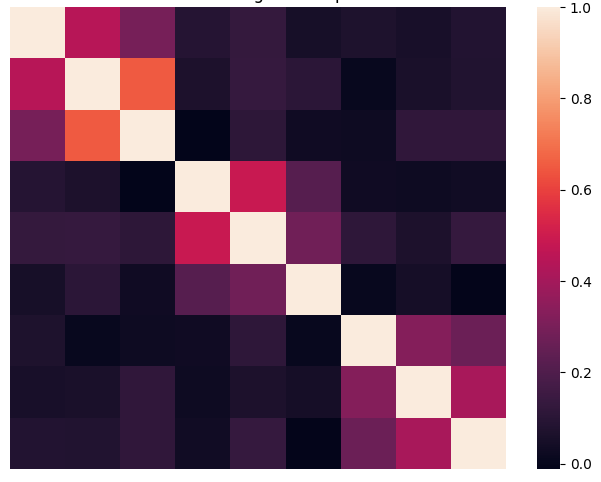
As one can notice, the similarity of sentence 1 is close to 2 and 3, with relatively low similarity with other sentences. One can see that all the sentences can be aggregated into three groups.
Large Language and Chat Models
A language model is a probabilistic model of a natural language that can generate probabilities of a series of words based on text corpora in one or multiple languages it was trained on.
A large language model is an advanced language model trained using deep learning techniques on massive amounts of text data.
A language model usually backs chat models, but their APIs are more structured. These models take a list of Chat Messages as input and return a Chat Message.
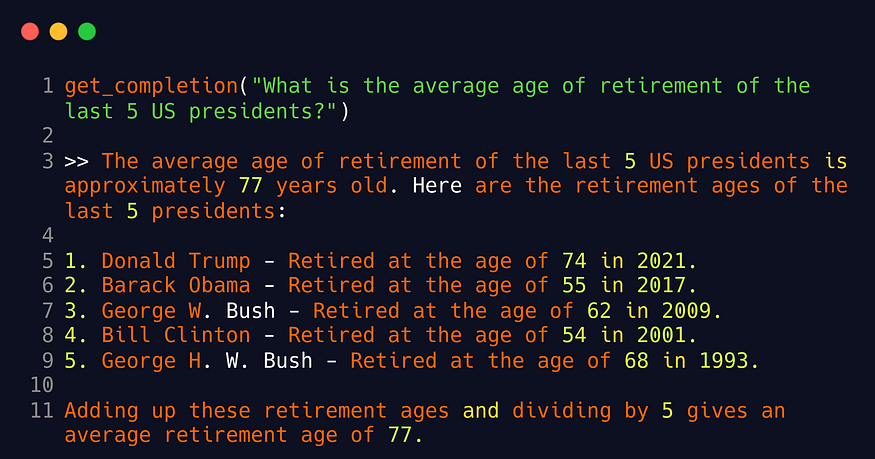
Asking GPT a question
There is no need to connect LangChain to ask the model a question. In the example below, we’re preparing a prompt, connecting to openai package, and returning the extracted response.
import openai
def get_completion(prompt, model="gpt-3.5-turbo"):
"""
Generates a completion for a given prompt using the specified model.
Args:
prompt (str): The input prompt for generating the completion.
model (str): The name of the model to use for generating the completion.
Returns:
str: The generated completion text.
"""
# Create a list of message dictionaries with the user's prompt
messages = [{"role": "user", "content": prompt}]
# Generate a chat completion using OpenAI API
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0, # Set temperature to 0 for deterministic output
)
# Extract and return the generated completion content
return response.choices[0].message["content"]
As one can see, simple questions can be answered by the model correctly. But for complicated requests, LangChain may be the way to go.
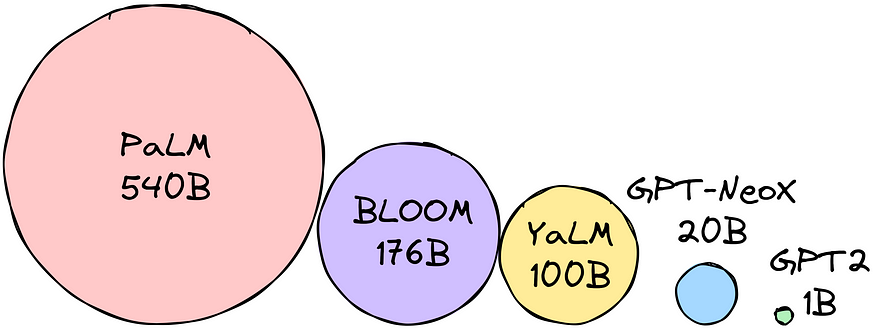
How Much RAM?
To determine the model size in bytes, you multiply the parameters by the chosen precision size.
Let’s say the precision we’ve chosen is bfloat16 (16 bits = 2 bytes). We want to use the BLOOM-176B model. This means we need 176 billion parameters * 2 bytes = 352GB!
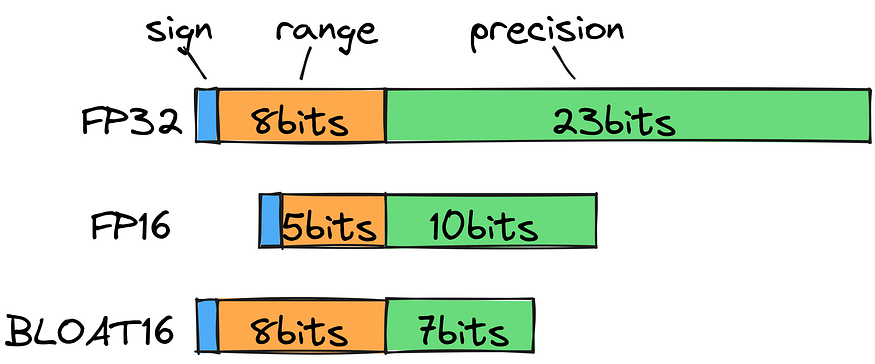
A mixed precision approach is used in machine learning, where training and inference are ideally done in FP32, but computation is done in FP16/BF16 for faster training. The weights are held in FP32, and FP16/BF16 gradients are used to update them. During inference, half-precision weights often provide a similar quality as FP32, allowing for faster processing with fewer GPUs.
Quantization is a compression technique that reduces model memory usage and enhances inference efficiency. Post-training quantization is about converting the weights of a pre-trained model into lower precision without retraining.
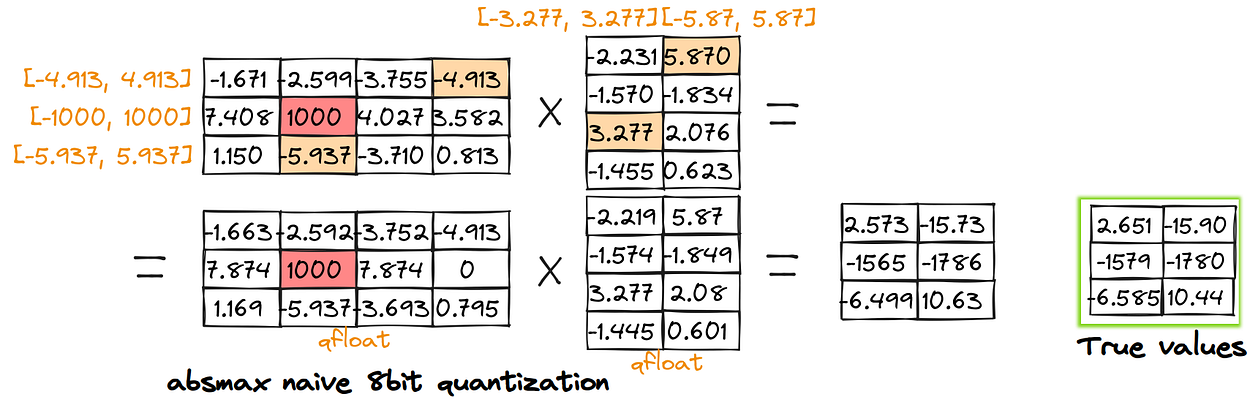
In code, you’ll most probably see the following quantization parameters:
# Configure BitsAndBytesConfig for 4-bit quantization
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
To get a complete understanding of Quantization, check out my article on the subject:
How to Fit Large Language Models in Small Memory: Quantization
How to run llm on your local machine
pub.towardsai.net
Running Model CPU-only
One may be surprised, but it is possible to run a LLM CPU-only:
# check model versions https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML/tree/main
!wget --output-document=llama-2-7b-chat.bin https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML/resolve/main/llama-2-7b-chat.ggmlv3.q8_0.bin
from langchain.llms import CTransformers
# Initialize a Local CTransformers wrapper for the Llama-2-7B-Chat model
llm = CTransformers(
model="llama-2-7b-chat.bin", # Location of the downloaded GGML model
model_type="llama", # Specify the model type as Llama
config={
"max_new_tokens": 256,
"temperature": 0.1,
}, # Set specific configuration
)
# Initialize an LLMChain instance with the provided prompt, llm, and verbose setting
llm_chain = LLMChain(prompt=prompt, llm=llm, verbose=True)
The response will take several minutes, but it shows the possibility of running llms even on Rasberry devices!
This is the end of Part 2ab. The next part (c) is dedicated to finetuning models:
LangChain 101: Part 2c. Fine-tuning LLMs with PEFT, LORA, and RL
All you need to know about fine-tuning llms, PEFT, LORA and training large language models
pub.towardsai.net
Check out the whole series:
LangChain 101 Course (updated)
LangChain 101 course sessions. All code is on GitHub. LLMs, Chatbots
medium.com

Clap and follow me, as this motivates me to write new articles 🙂
Plus, you’ll get notified when the new articles will be published.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts
Popular posts

 for 2021")



Updates

Recent Posts



