Understanding the Transformer Model: A Breakdown of “Attention is All You Need”
Imagine a world where machines possess an uncanny ability to understand, generate, and translate human language with remarkable accuracy — a world where innovation breaks free from the shackles of tradition. It’s a paradigm shift that challenges the very foundations of sequential processing, a bold leap beyond fixed context windows. In this realm, machines transcend the limitations that once held them back, soaring toward a future where the intricacies of language are effortlessly unraveled, opening the door to exceptional communication and understanding. Let’s explore the Transformer model that does that precise magic, the encoder-decoder structure that powers its translation prowess, and witness the magic unfold as the model generates rich representations, transforming language from one form to another.
In natural language processing (NLP), the “Attention is All You Need” paper introduced a groundbreaking neural network architecture called the Transformer. Published in 2017, this paper revolutionized machine translation tasks by proposing a model that solely relies on self-attention mechanisms without using recurrent or convolutional networks. This article aims to provide an accessible breakdown of the critical sections and concepts presented in the paper, offering a comprehensive understanding of the Transformer model.
Motivation and Background:
The paper begins by highlighting the limitations of traditional architectures in capturing long-range dependencies in sequences. Recurrent neural networks (RNNs) struggle with parallel computation due to sequential processing, and convolutional networks have fixed context windows. To address these issues, the authors propose the Transformer model, which employs self-attention mechanisms to capture relationships between all positions within a sequence efficiently.

Model Architecture:
The core of the Transformer model lies in its unique architecture. The input sequence is first transformed into embedding vectors, augmented with positional information using learned positional encodings. The augmented embeddings are fed into a stack of encoder and decoder layers. Each layer comprises sub-layers, including self-attention mechanisms and feed-forward neural networks. The self-attention mechanism allows each position to attend to all other positions, capturing local and global dependencies. The feed-forward network adds non-linearity and capacity to the model.
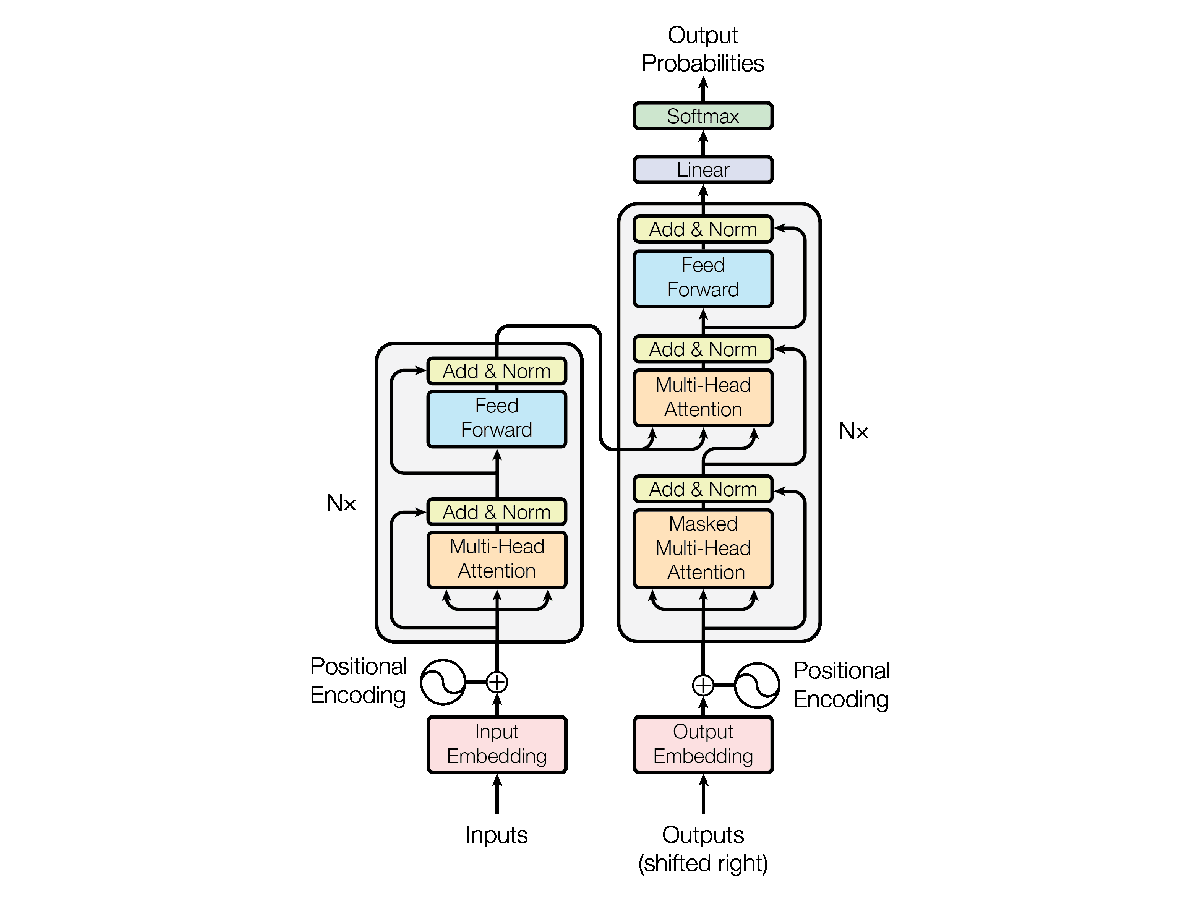
Self-Attention Mechanism:
The self-attention mechanism, a pivotal component of the Transformer, is worth exploring in detail. It involves three essential steps: computing query, key, and value vectors for each position in the sequence. These vectors are derived from linear transformations of the input embeddings. By comparing the query with the key vectors, attention weights are calculated, representing the relevance of different positions to each other. The weighted sum of value vectors by attention weights produces the final representation for each position. This attention mechanism allows the model to focus on relevant positions during encoding and decoding.


Encoder and Decoder:
The Transformer model consists of both an encoder and a decoder. The encoder processes the input sequence, generating representations for each position using self-attention and feed-forward layers. On the other hand, the decoder generates the output sequence by attending to both the encoder’s output and its own previously generated positions. This lets the decoder consider the input sequence while predicting the next output token. The self-attention and feed-forward layers in the decoder facilitate this process, providing rich representations and non-linear transformations.


Check out this link: https://www.tensorflow.org/text/tutorials/transformer
Training and Inference:
During training, the Transformer model is optimized using a cross-entropy loss function. The model is trained to minimize the negative log-likelihood of the correct output sequence given the input sequence. In inference, the model generates the output sequence token by token, utilizing beam search to explore multiple possible sequences and select the most likely one. Beam search helps the model make informed decisions during decoding by considering a set of promising paths.

Extensions and Variations:
The paper also discusses various extensions and variations of the Transformer model. It suggests incorporating additional convolutional layers in the encoder to capture local patterns efficiently. Multiple attention heads are proposed to enable the model to simultaneously attend to different sequence parts, enhancing its symbolic power. The authors also mention the importance of adjusting hyperparameters, such as dropout rates and layer normalization, to improve performance and stability.

By leveraging self-attention mechanisms, the Transformer achieved remarkable results in machine translation tasks, outperforming traditional recurrent and convolutional networks. Its ability to capture long-range dependencies efficiently has made it a foundational model in various NLP applications. Understanding the key components, such as the self-attention mechanism, encoder-decoder structure, and training/inference processes, provides a solid foundation for grasping the advancements and potential of the Transformer model.
The Transformer model has significantly impacted the NLP landscape, inspiring subsequent research and improvements. With its attention-based approach, the Transformer is a powerful tool for processing sequential data, opening new doors for language understanding, generation, and other related tasks.

This is the first paper I had to read and summarize as part of my Research Internship at the University College of Dublin — As part of my learning, I wanted to write and share this post.
I will continue to write about each of the components of the Transformer model in further detail. Before that, I wanted to get this overall summary post out of the way so it is easily understandable to everyone who comes across it.
Until next time! Adios!!
