Swin Transformer: A Novel Hierarchical Vision Transformer for Object Recognition

Introduction
The impact of the digital world is vast and far-reaching, shaping various aspects of our daily lives, and as time passes, humans are getting surrounded by more digital stuff. The ability to detect and recognize objects in images and videos is a crucial step toward creating intelligent systems that can interact with the world around them.
The process of locating and identifying objects of interest in an image or video is part of the object detection method, a popular computer vision technique. Object detection is typically achieved through the use of deep learning models, particularly Convolutional Neural Networks (CNNs). CNNs are capable of learning features that are robust to variations in object appearance, lighting, and orientation, and can be trained to identify specific object categories such as people, cars, animals, and other objects.
In this article, you will learn about object detection through the SWIN Transformer.
What is the Swin Transformer?
The Swin Transformer is a deep learning model architecture that uses a hierarchical approach to perform object recognition in computer vision. It was introduced in a paper called “Swin Transformer: Hierarchical Vision Transformer using Shifted Windows” by Microsoft Research Asia. in 2021.
At a high level, the Swin Transformer is based on the transformer architecture, which was originally developed for natural language processing but has since been adapted for computer vision tasks. The transformer architecture uses self-attention and multi-layer perceptron (MLP) layers to process input data and learn useful representations for downstream tasks.
How does the team at Uber manage to keep their data organized and their team united? Comet’s experiment tracking. Learn more from Uber’s Olcay Cirit.
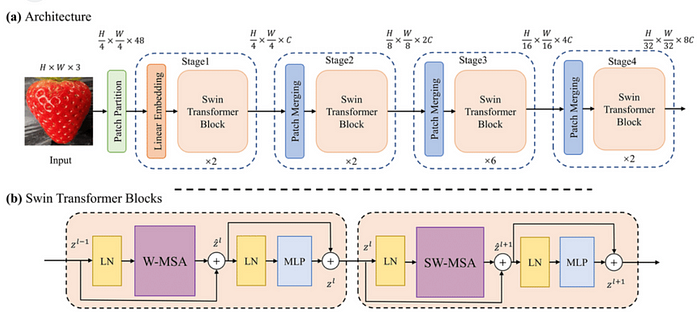
The architecture of Swin Transformer
The swin Transformer architecture model is able to capture both local and global image features. It divides an input image into several discrete, non-overlapping patches, which are then processed by various transformer layers. There are several attention heads on each transformer layer that pay attention to different areas of the incoming image.
- Patch Embedding: It is a critical component of the Swin Transformer architecture that enables the model to process input images in a scalable and efficient manner. The input image is first divided into a set of non-overlapping patches, with each patch consisting of a fixed number of pixels. Each patch is then linearly embedded into a high-dimensional vector using a convolutional layer, producing a set of patch embeddings.
- Shifted Window Self-Attention: The transformer layers apply a self-attention mechanism to the patch embeddings, which allows the model to attend to different parts of the image while maintaining spatial relationships between the patches. In the Swin Transformer, a shifted window attention mechanism is used, which means that the attention is applied to overlapping patches with a shift. This allows the model to capture more fine-grained spatial relationships between the features.
- MLP Block: After the self-attention mechanism, the patch embeddings are processed through a Multi-Layer Perceptron (MLP) block, which applies a series of linear transformations followed by non-linear activation functions to the patch embeddings.
- Down-Sampling: To process the image at multiple scales, the Swin Transformer uses a down-sampling mechanism that reduces the resolution of the patch embeddings. This is achieved by grouping the patches into non-overlapping tiles and applying another set of MLPs to each tile.
- Up-Sampling: To recover the spatial resolution of the features, the Swin Transformer uses an up-sampling mechanism that combines the low-resolution tiles with the high-resolution patch embeddings from the previous layer.
- Classification Head: Finally, the Swin Transformer applies a linear projection to the patch embeddings from the last layer and uses them to classify the input image into different categories.
Advantages of using Swin Transformer
- Improved computational efficiency: The Swin Transformer architecture is designed to reduce the computational complexity of the traditional Transformer architecture, making it more efficient to train and use.
- Better performance on large-scale image recognition tasks: Swin Transformer has shown superior performance over other models like ResNet and EfficientNet in large-scale image recognition tasks like ImageNet, CIFAR-100, and COCO.
- Hierarchical feature extraction: Swin Transformer uses a hierarchical feature extraction approach, where it first extracts low-level features from the image and then gradually refines them to higher-level features. This approach has been shown to be effective in capturing both local and global features of the image.
- Scalability: Swin Transformer can be easily scaled to accommodate larger datasets and more complex image recognition tasks without sacrificing performance.
- Transfer learning: Swin Transformer can be pre-trained on large datasets like ImageNet and then fine-tuned on smaller datasets for specific image recognition tasks, which can significantly reduce the amount of labeled data required for training.
Implementation
A sample code for object detection using the Swin Transformer in Python is written below. This code assumes that you have a dataset that is properly annotated with object labels.
Step 1: Import the required libraries
import torch
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from torchvision.models.detection import FasterRCNN
from torchvision.transforms import transforms
from torch.utils.data import DataLoader
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
import requests
from io import BytesIOStep 2: Define the Swin Transformer model and the number of classes that you want to detect.
# Define the model here
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained = True)
number_classes = 3
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, number_classes)Step 3: Define the transformations that you want to apply to the input image
transform = transforms.Compose([transforms.ToTensor()])Step 4: Load the image that you want to detect objects in
img_url = './Image_path/..'
response = requests.get(img_url)
img = Image.open(BytesIO(response.content)).convert('RGB')Step 5: Apply the transformations to the input image
img = transform(img)Step 6: Add a batch dimension to the image
img = img.unsqueeze(0)Step 7: Set the model to evaluation mode and pass the image through the model.
model.eval()
with torch.no_grad():
predictions = model(img)Step 8: Visualize the predicted bounding boxes on the input image
boxes = predictions[0]['boxes'].cpu().numpy()
scores = predictions[0]['scores'].cpu().numpy()for box, score in zip(boxes, scores):
if score > 0.8:
x1, y1, x2, y2 = box
x1, y1, x2, y2 = int(x1), int(y1), int(x2), int(y2)
img = np.array(img.permute(1, 2, 0))
img = cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
plt.imshow(img)
plt.show()Conclusion
The Swin Transformer is a recent development in the field of computer vision, and it has already shown promising results in various tasks such as image classification, object detection, and semantic segmentation. Due to its success and potential, it is likely that the Swin Transformer will continue to be an active area of research in the coming years.
The Swin Transformer is part of a larger trend in deep learning towards attention-based models and self-supervised learning. Overall, it’s future looks promising, and it will likely continue to be a topic of research interest and a useful tool for various computer vision applications.
Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for data science, machine learning, and deep learning practitioners. We’re committed to supporting and inspiring developers and engineers from all walks of life.
Editorially independent, Heartbeat is sponsored and published by Comet, an MLOps platform that enables data scientists & ML teams to track, compare, explain, & optimize their experiments. We pay our contributors, and we don’t sell ads.
If you’d like to contribute, head on over to our call for contributors. You can also sign up to receive our weekly newsletter (Deep Learning Weekly), check out the Comet blog, join us on Slack, and follow Comet on Twitter and LinkedIn for resources, events, and much more that will help you build better ML models, faster.
