Named Entity Recognition With SpaCy

Introduction
Machine learning (ML) focuses on developing algorithms and models that can learn from data and make predictions or decisions. One of the goals of ML is to enable computers to process and analyze data in a way that is similar to how humans process information.
Human brains are capable of processing vast amounts of information from the environment and making complex decisions based on that information. In the same way, ML algorithms can be trained on large datasets to learn patterns and make predictions based on that data.
What is Named Entity Recognition (NRE)?
Named entity recognition (NER) is a subtask of natural language processing (NLP) that involves automatically identifying and classifying named entities mentioned in a text. It helps to extract structured information from unstructured text, which is useful in many applications, such as information extraction, text mining, sentiment analysis, and question-answering.
In this article, we will discuss how to perform Named Entity Recognition with SpaCy, a popular Python library for NLP.

How does NRE Work?
NRE is a complex task that involves multiple steps and requires sophisticated machine learning algorithms like Hidden Markov Models (HMMs), Conditional Random Fields (CRFs), and Support Vector Machines (SVMs) be present. The choice of an algorithm often depends on the specific task and the available data, and most of them have the common steps listed below.
- Pre-processing: The text is first pre-processed by removing any unnecessary information, such as stop words, and tokenizing the text into individual words.
- Part-of-speech (POS) tagging: Each word in the text is tagged with its part-of-speech (e.g., noun, verb, adjective). This is important because named entities are often nouns or proper nouns.
- Chunking: The text is then chunked into phrases that correspond to named entities. This involves identifying contiguous groups of words that belong together, based on their part-of-speech tags.
- Classification: Each phrase is then classified into specific named entity categories, such as a person, organization, location, date, or numerical expression. This is done using machine learning algorithms, such as decision trees, support vector machines, or neural networks, which are trained on annotated text data.
- Post-processing: Finally, the results are post-processed to handle cases where multiple named entities are detected in the same sentence, or where the same named entity is referred to by different names (e.g., synonyms). The output is a list of named entities and their corresponding categories.
An example of how an NER algorithm can highlight and extract specific entities from a text document is shown in the image below.
What is SpaCy?
SpaCy is a Python-based, open-source Natural Language Processing (NLP) library that was created to be quick, effective, and simple to use. It offers a variety of Natural Language Processing (NLP) features, such as text classification, named entity recognition, part-of-speech tagging, and dependency parsing. It is built using Python and is designed to be fast, efficient, and scalable.
SpaCy’s effectiveness and quickness are two of its standout qualities. It uses streamlined algorithms and data structures in order to process vast amounts of text quickly. This makes it a strong option for real-time applications or analyzing huge datasets when performance is crucial.
Advantages of Using SpaCy
It provides a fast, efficient, and user-friendly way of processing and analyzing text data. Some advantages are listed below:
- High Performance: SpaCy is optimized for performance, and its processing speed is faster than many other NLP libraries. It is designed to be scalable and can handle large volumes of text data efficiently.
- Pre-trained Models: It provides pre-trained models for Named Entity Recognition (NER), Part-of-Speech (POS) tagging, Dependency Parsing, and other NLP tasks. These models are trained on large corpora of text and can be fine-tuned on specific domains.
- Easy-to-use API: Provides a user-friendly and intuitive API that makes it easy to use and understand. It follows a simple and consistent interface, making it easy to learn and use for both beginners and experienced users.
- Customization: It allows for the customization of its models, which makes it possible to train models for specific domains or tasks. Users can also add their custom components to the pipeline for more specific processing.
- Active Development: It is an actively developed library, with a large community of contributors and users. This means that bugs are quickly fixed, and new features are regularly added, making it a reliable and up-to-date library for NLP tasks.
Use Comet to track your metrics, hyper-parameters, and models for your spaCy project!
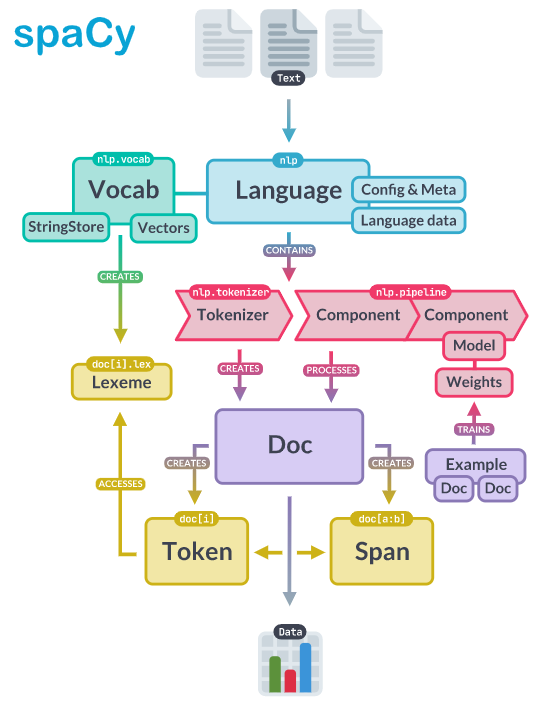
Architecture of SpaCy
The architecture is divided into three main components:
- Language model: This component provides the core NLP functionality of SpaCy. It is responsible for tokenization, part-of-speech tagging, dependency parsing, and named entity recognition. The language model is trained on large corpora of text data, and the resulting model is used to analyze new text.
- Pipeline: This component is a series of processing steps that the text goes through. Each processing step is implemented as a component in the pipeline, and the output of one component becomes the input of the next. The pipeline can be customized to include or exclude specific components, depending on the specific NLP task at hand.
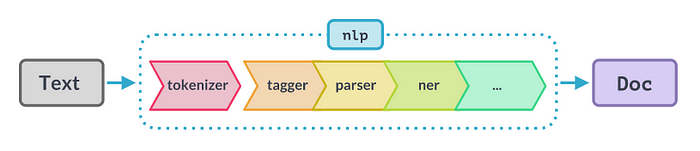
3. Vocabulary: This component is responsible for storing the mapping between the words in the text and their numerical representations. The vocabulary is built by the language model during training, and it is used during inference to convert the text into a format that can be processed by the model.
The overall architecture image of the SpaCy model is shown below.
Installing and downloading the SpaCy Library
Before using SpaCy, you need to install it. You can do this using pip, a package manager for Python
pip install spacyAfter installing SpaCy, you need to download a language model. SpaCy provides several pre-trained models for different languages. In this example, we will be using the English language model.
python -m spacy download en_core_web_smNow that you have installed and loaded the English language model, you are ready to start implementing NER.
Implementing NER with SpaCy
The first step in implementing NER with SpaCy is to load the text that you want to analyze. For example, let’s say you have the following news headline text:
# Example text
text = "Apple is looking to buying a U.S.A startup for $5 billion"Loading the Language Model
Once the language model is downloaded, we can load it into our Python program using the spacy.load() function. We will use the en_core_web_sm model, which is a small English model that includes word vectors, syntax, and named entities. Here is an example of how to load the language model:
To analyze this text with SpaCy, we first need to create a nlp model and pass the text to it as coded below.
import spacy
#Loading the language Model
nlp = spacy.load("en_core_web_sm")
text = "Apple is looking to buying a U.S.A startup for $5 billion"
doc = nlp(text)Next, you can access the named entities in the text using the ents property of the doc object. This property returns an iterator of Span objects, where each Span object represents a named entity in the text.
# Iterate over the entities in the text
for ent in doc.ents:
# Print the text of the entity and its label (e.g. "Apple" and "ORG")
print(ent.text, ent.label_)The text property of the Span object returns the actual text of the named entity, and the label_ property returns the category of the named entity. SpaCy supports several categories of named entities, including PERSON, ORG, GPE, DATE, TIME, and MONE.
Output
Apple ORG
U.S.A GPE
$5 billion MONEYHere, ORG stands for organization, GPE stands for a geopolitical entity, and MONEY stands for monetary expression. Note that SpaCy automatically recognizes and labels the named entities in the text based on its pre-trained models. You can also train custom models using SpaCy if you want to recognize specific named entities for your application.
Conclusion
This piece taught you how named entity recognition (NER) operates when it can be applied, and how to train a special NER model to extract medical terms from journal text. To build a customized NER model for your applications, you can use the same procedure; all you need is some annotated data. If you are unable to locate any pre-existing datasets that fit your use case, you can create your own using one of these data annotation tools.
Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for data science, machine learning, and deep learning practitioners. We’re committed to supporting and inspiring developers and engineers from all walks of life.
Editorially independent, Heartbeat is sponsored and published by Comet, an MLOps platform that enables data scientists & ML teams to track, compare, explain, & optimize their experiments. We pay our contributors, and we don’t sell ads.
If you’d like to contribute, head on over to our call for contributors. You can also sign up to receive our weekly newsletter (Deep Learning Weekly), check out the Comet blog, join us on Slack, and follow Comet on Twitter and LinkedIn for resources, events, and much more that will help you build better ML models, faster.
