Distilling with LLM-Generated Rationales Yields Outperformance in Task-Specific Fine-tuning!

Large Language Models are challenging to serve in practice making implementers gravitate towards distilled models. Distillation yields smaller models (700x smaller, in some cases) with lower latency (at inference time), and makes for practical deployable scenarios.
In the paper, Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes the authors show that, in addition to smaller models, their scheme also leads to outperformance for specific tasks!
Practitioners prefer to deploy smaller specialized models. Before proceeding with Distilling Step-By-Step, let’s recap how smaller models are created. Smaller models are trained using one of two common approaches, (1) finetuning and (2) distillation.
Standard Finetuning (with labels)
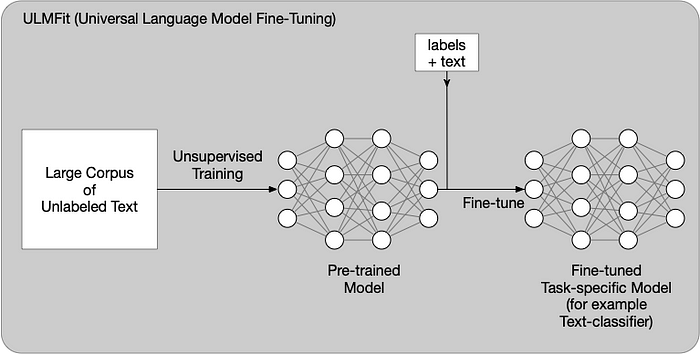
A common practice to train a task-specific model is to finetune a pre-trained model with supervised data (ala ULMFiT). In this case, labels are available.
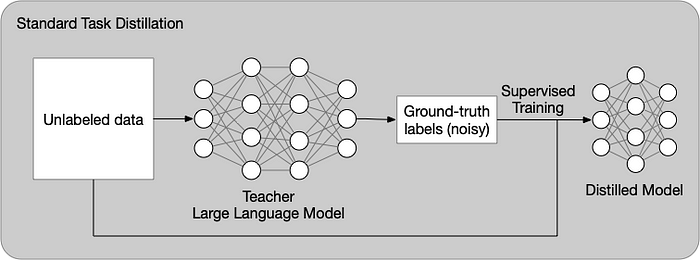
Standard Task Distillation (without labels)
When no human-annotated labels are available, task-specific distillation uses LLM teachers to generate pseudo-noisy training labels and subsequently uses them in a supervised scenario.
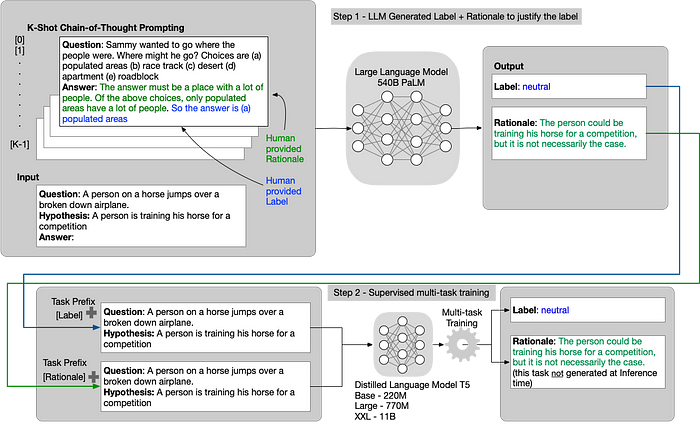
The “Distilling Step-By-Step!” Paper
Now we proceed to summarize the Distilling Step-by-Step Paper. The procedure first extracts rationales from LLMs as informative task knowledge. Next, it uses the rationale for training small models in a supervised manner. This approach reduces both the deployed model size as well as the data required for training. In this post, we focus on the model size reduction (and not the training data reduction) as model size is critical to deployment.
Core Tenet of the Distillation
The core tenet of the paper reframes viewing LLMs as more than a source of noisy labels (as is the case in standard task distillation above) to viewing them as agents that can reason. The paper exploits that in two steps: (1) From an unlabeled dataset, prompt the LLM to generate outputs labels along with rationales to justify the labels. (2) Leverage these rationales and the task labels to train smaller downstream models. There’s a twist; the approach frames supervised learning with rationales as a multi-task problem. The supervision not only predicts the task labels but also generates the corresponding rationales given the text input (and the ground truth). The rationale generation enables the model to learn to generate the intermediate reasoning steps for the prediction, and could therefore guide the model in better predicting the resultant label. Note, generating Rationale is not required at inference time (just labels), and that removes the need for an LLM at inference time.
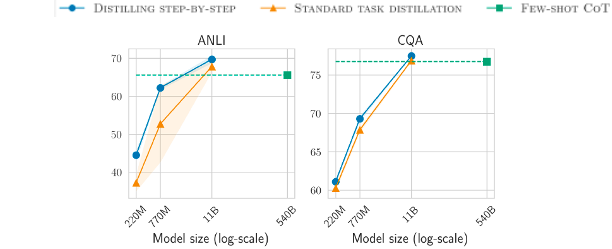
Task-Specific Fine-Tuning (Step 2) Losses Summarized
The distilled model f is trained to minimize the label prediction (cross-entropy) loss:
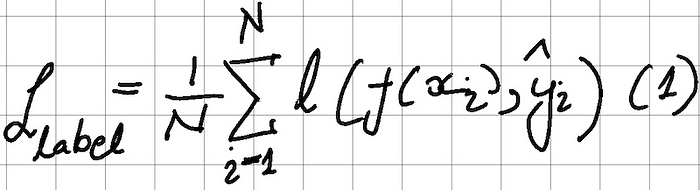
To the label prediction loss function above, we add a rationale prediction loss where r is the rationale.

Together, they yield the total loss function below:

Below is a guide to the equations above.
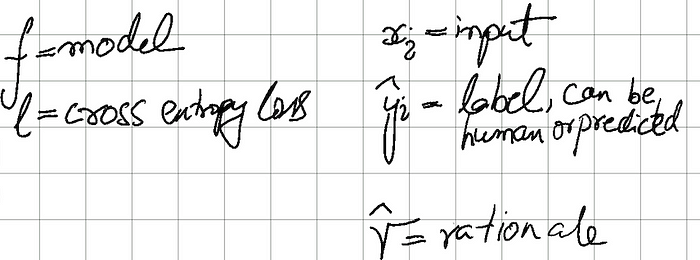
Select Results
Using a full human-labeled dataset
Distilling step-by-step is able to outperform Few-shot chain-of-thought (CoT) LLM baselines by using much smaller models (700x smaller) model on the Adversarial Natural Language Inference (ANLI) benchmark.
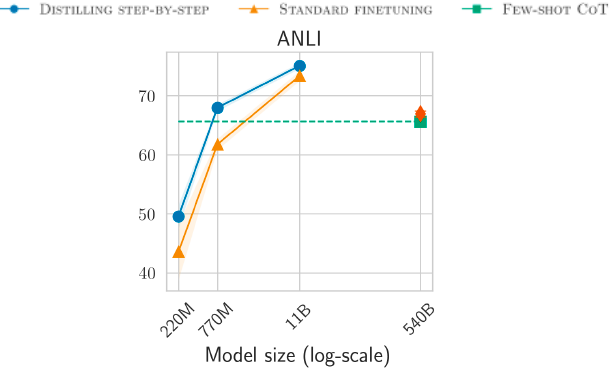
Using Unlabeled Datasets
Distilling step-by-step outperforms Few-shot CoT by using 45x smaller T5 models on ANLI and Common Sense Question and Answer (CQA) benchmark.
Conclusion
The authors show that by extracting rationales from LLMs and then using them (as informative supervision) in supervised multi-task training, small task-specific models can outperform LLMs by a huge factor (770x in a labeled scenario and 45x in an unlabeled scenario).
References
Universal Language Model Fine-tuning for Text Classification (ULMFiT)
Language Models in the Loop: Incorporating Prompting into Weak Supervision
