Build an ML Inference Data Pipeline using SageMaker and Apache Airflow
Automate and streamline our ML inference pipeline with SageMaker and Airflow
Building an inference data pipeline on large datasets is a challenge many companies face. There are several architectural patterns and approaches to help us tackle this problem. But only some solutions may deliver the desired results for efficiency and cost-effectiveness.
🤔Problem statement
Let’s say we need to classify a large number of tweets twice a day, so we will build an inference data pipeline at scale by triggering the SageMaker batch inference job and creating an end-to-end workflow using Apache Airflow on the Tweets dataset.
Let’s look at some of the real-world batch inference use cases.
Real-world batch inference use cases
- NLP: Batch inference can be used in applications such as text classification, sentiment analysis, language translation, and text summarization. For example, a company may enrich documents in bulk to translate documents, identify entities and categorize those documents, etc.
- Image and video processing: Batch inference can be used in object detection, image segmentation, and video analysis applications. For example, a security camera system may process hours of footage at once to detect any potential security threats.
SageMaker Batch Job
Allows you to run batch inference on large datasets and generate predictions in a batch mode using machine learning (ML) models hosted in SageMaker.
The Batch job automatically launches an ML compute instance, deploys the model, and processes the input data in batches, producing the output predictions. Once the job is complete, the results can be retrieved from the output location specified when the job was created.
🎯Goal
Kaggle competition dataset, which consists of fake and real Tweets about disasters. The task is to classify the tweets in batch mode.
🏛️Tweets inference data pipeline architecture
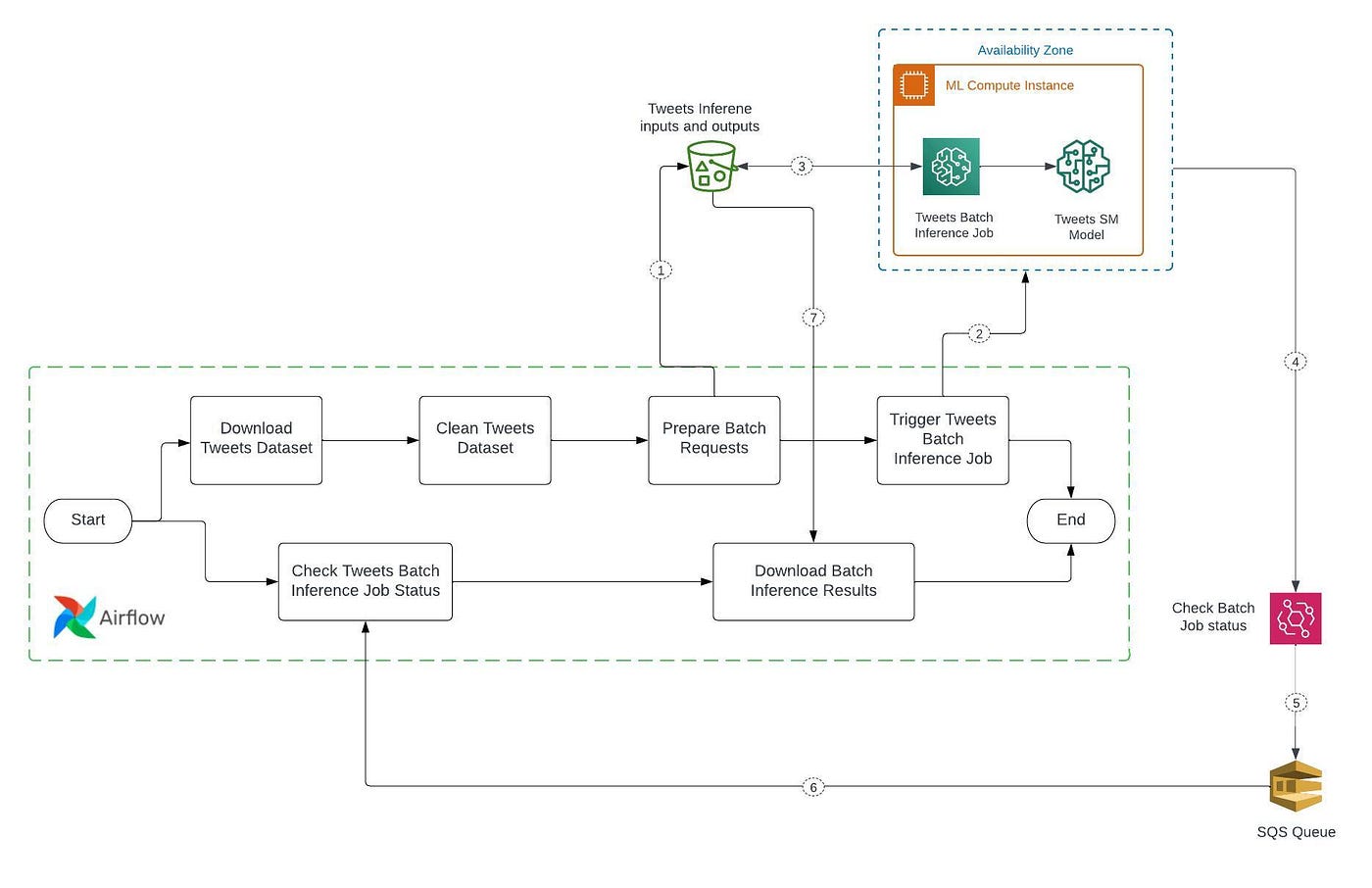
The workflow performs the following tasks:
- Download Tweets Dataset: Download the tweets dataset from the S3 bucket.
- Clean Tweets Dataset: Remove special characters like “@” from the tweets and save them in JSON format.
- Prepare Batch Requests: Upload the Tweets JSON file to the S3 bucket, the input reference for the SageMaker Batch job.
- Trigger Tweets Batch Inference Job: Define and trigger a Batch inference job with S3 input and output paths, data type, and inference job resources like instance type and instance count.
Depending on the model type, compute resources, and input size, the batch inference job might take some time to complete.
So we have to create an event rule on AWS EventBridge that monitors the SageMaker batch inference job and will push the message to the SQS after completing the batch inference job. - Check Tweets Batch Inference Job Status: Create an SQS listener that reads a message from the queue when the event rule publishes it.
- Download Batch Inference Results: Download batch inference results after completing the batch inference job and message received by SQS.
🚀Create a Tweets Classifier model
A prerequisite to executing the SageMaker batch job is to create a Tweets classifier (HuggingFace BERT) model on SageMaker.
In my previous post, I discussed how to fine-tune a HuggingFace BERT model with two epochs on the disaster tweets classification dataset using on-demand and spot instances, deploy that model on a real-time endpoint, and update that endpoint.
import os
import sagemaker
import boto3
from time import gmtime, strftime
sagemaker_session = sagemaker.Session()
bucket = sagemaker_session.default_bucket()
region = sagemaker_session.boto_session.region_name
sm_boto3 = boto3.client("sagemaker")
def name_with_timestamp(name):
return '{}-{}'.format(name, strftime('%Y-%m-%d-%H-%M-%S', gmtime()))
tweet_cls_v1_model_name = name_with_timestamp('tweet-classifier-v1-model')
# Fine-tuned model with 2 epochs
model_v1_path = "s3://sagemaker-xx-xxxx-x-xxxxxxxxxxxx/sagemaker/social-media/models/model_v1/model_v1.tar.gz"
production_variant_name = "AllTraffic"
# Create a tweet-classifier-v1 model as production variant
from sagemaker import get_execution_role
image_uri = sagemaker.image_uris.retrieve(
framework="pytorch",
region=region,
py_version="py38",
image_scope="inference",
version="1.9",
instance_type="ml.m5.xlarge",
)
primary_container = {'Image': image_uri, 'ModelDataUrl': model_v1_path,
'Environment': {
'SAGEMAKER_PROGRAM': 'train_deploy.py',
'SAGEMAKER_REGION': region,
'SAGEMAKER_SUBMIT_DIRECTORY': model_v1_path
}
}
create_model_response = sm_boto3.create_model(ModelName = tweet_cls_v1_model_name, ExecutionRoleArn = get_execution_role(), PrimaryContainer = primary_container)
print('ModelArn= {}'.format(create_model_response['ModelArn']))🛠️Airflow setup
Apache Airflow is an open-source tool for orchestrating workflows and data processing pipelines. Airflow allows you to configure, schedule, and monitor data pipelines programmatically in Python to define all the stages of the lifecycle of typical workflow management.
We use DAG (Directed Acyclic Graph) in Airflow, DAGs describe how to run a workflow by defining the pipeline in Python, that is configuration as code.
Prerequisites
- Create an AWS EC2 instance with ubuntu AMI, for example, ml.m5.xlarge instance with 4 CPU cores and 16 GB RAM sufficient for Airflow installation.
- Create an IAM role that has the following privileges and attach it to our EC2 instance.
AmazonEC2FullAccessAmazonSQSFullAccessAmazonS3FullAccessAmazonSageMakerFullAccess
Note: We can restrict the access policy based on our requirements. - Install a few packages by using the below commands
sudo apt-get update
sudo apt install python3-pip
sudo pip install pandasInstall Apache-Airflow
We can install Airflow on AWS EC2 (ubuntu) instances in multiple ways like using PyPI, docker images, and Airflow helm chart, etc.
In this blog post, we will install Apache-Airflow using the Python package.
sudo pip install apache-airflowRunning Airflow
We need to execute the command below to run the entire Airflow server, including the airflow web server, scheduler, workers, etc.
airflow standaloneWe will get the airflow user Id and password to log into Airflow UI.

We can see the airflow web UI by using this URL and will get Public IPV4 DNSfrom EC2 instance details.
http://<Public IPv4 DNS>:8080/home
Apache-Airflow setup is ready, as depicted in the Tweets inference data pipeline architecture let’s start building the Tweets inference data pipeline.
👨💻Build a Tweets inference data pipeline
This section will create an Inference data workflow using Airflow operators such as Python operators.
We can also use Amazon SageMaker operators which are custom operators available with Airflow installation allowing Airflow to talk to Amazon SageMaker and perform the ML tasks such as model training, hyper-parameter tuning, creating SageMaker model, endpoint config and endpoint, etc.
Download tweets dataset
Let’s assume that tweet_data.csv inference dataset will be uploaded in the S3 bucket to classify the tweets so we have to download the tweets dataset from S3 to preprocess it before classifying tweets.
def download_tweets_dataset(local_file_path: str, s3_bucket: str, s3_key: str):
# Create an S3 client with the access key and secret key
s3 = boto3.client('s3')
if not os.path.exists(local_file_path):
os.makedirs(local_file_path)
# Download the file from S3
s3.download_file(s3_bucket, s3_key, os.path.join(local_file_path, 'tweet_data.csv'))
print(f'{s3_bucket}/{s3_key} downloaded to {local_file_path}')
# Download Tweets Dataset
download_tweets_dataset = PythonOperator(
task_id='Download_Tweets_Dataset',
python_callable=download_tweets_dataset,
op_kwargs={
'local_file_path': '/home/ubuntu/airflow/data',
's3_bucket': 'sagemaker-xx-xxxx-x-xxxxxxxxxxxx',
's3_key': 'sagemaker/social-media/dataset/tweet_data.csv'
}
)Clean tweets dataset
Remove special characters like “@” from the tweets and save them in JSON format.
def clean_tweets_dataset(local_file_path: str):
csv_file = os.path.join(local_file_path, 'tweet_data.csv')
json_file = os.path.join(local_file_path, 'tweet_data.json')
with open(csv_file, "r+") as infile, open(json_file, "w+") as outfile:
reader = csv.reader(infile)
for row in reader:
data = [row[0].replace("@","")]
outfile.write(json.dumps(data))
outfile.write('\r\n')
# Clean Tweets Dataset
clean_tweets_dataset = PythonOperator(
task_id='Clean_Tweets_Dataset',
python_callable=clean_tweets_dataset,
op_kwargs={
'local_file_path': '/home/ubuntu/airflow/data'
}
)Prepare batch requests
Upload the cleaned tweet_data.json file to the S3 bucket, the input reference for the SageMaker Batch job.
def prepare_batch_request(local_file_path: str, s3_bucket: str, s3_key: str):
# Create an S3 client with the access key and secret key
s3 = boto3.client('s3')
# Set the path to your local file
local_file_path = os.path.join(local_file_path, 'tweet_data.json')
# Upload the file to S3
s3.upload_file(local_file_path, s3_bucket, s3_key)
print(f'{local_file_path} uploaded to {s3_bucket}/{s3_key}')
# Prepare Batch Requests
prepare_batch_request = PythonOperator(
task_id='Prepare_Batch_Request',
python_callable=prepare_batch_request,
op_kwargs={
'local_file_path': '/home/ubuntu/airflow/data',
's3_bucket': 'sagemaker-xx-xxxx-x-xxxxxxxxxxxx',
's3_key': 'sagemaker/social-media/batch_transform/input/tweet_data.json'
}
)Trigger tweets batch inference job
Let’s define a Batch inference job with S3 input and output paths, data type, and inference job resources like instance type and instance count.
def trigger_tweets_batch_inference_job(batch_input: str, batch_output: str, model_name):
sm_boto3 = boto3.client('sagemaker', region_name='xx-xxxxx-x')
batch_job_name = "tweets-batch-inference-job-" + time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime())
request = {
"ModelClientConfig": {
"InvocationsTimeoutInSeconds": 3600,
"InvocationsMaxRetries": 3,
},
"TransformJobName": batch_job_name,
"ModelName": model_name,
"MaxPayloadInMB": 1,
"BatchStrategy": "SingleRecord",
"TransformOutput": {
"S3OutputPath": batch_output,
"AssembleWith": "Line",
"Accept": "application/json",
},
"TransformInput": {
"DataSource": {"S3DataSource": {"S3DataType": "S3Prefix", "S3Uri": batch_input}},
"SplitType": "Line",
"ContentType": "application/json",
},
"TransformResources": {"InstanceType": "ml.c5.9xlarge", "InstanceCount": 1},
}
response = sm_boto3.create_transform_job(**request)
print("response:", response)
# Trigger a Batch Inference Job
trigger_tweets_batch_inference_job = PythonOperator(
task_id='Trigger_Tweets_Batch_Inference_Job',
python_callable=trigger_tweets_batch_inference_job,
op_kwargs={
'batch_input': 's3://sagemaker-xx-xxxx-x-xxxxxxxxxxxx/sagemaker/social-media/batch_transform/input',
'batch_output': 's3://sagemaker-xx-xxxx-x-xxxxxxxxxxxx/sagemaker/social-media/batch_transform/output',
'model_name': 'tweet-classifier-v1-model-2023-03-26-12-10-53'
}
)Now, we will create a queue tweets-batch-inference-job-queue in AWS SQS with default settings.
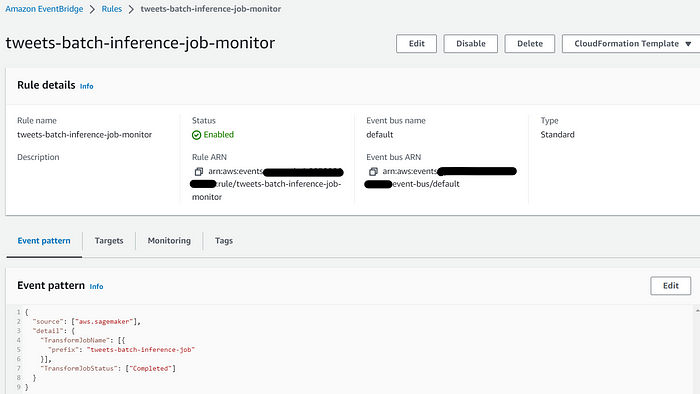
Also, create an event rule tweets-batch-inference-job-monitorin the AWS event bridge by defining tweets-batch-inference-job-queue as a target.
The event rule will monitor the SageMaker batch inference job and will push the message to the tweets-batch-inference-job-queue after the completion of the batch inference job.
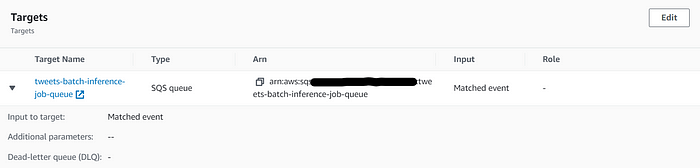
Check tweets batch inference job status
Create an SQS listener that reads a message from the tweets-batch-inference-job-queue when the event rule publishes batch inference job completion status.
# Read an SQS message that contains Batch job completion details
check_batch_inference_job_status = PythonOperator(
task_id='Check_Tweets_Batch_Inference_Job_Status',
python_callable=check_batch_inference_job_status,
op_kwargs={
'queue_name': 'tweets-batch-inference-job-queue'
}
)Download batch inference results
Download batch inference results that may be required to integrate into further pipeline steps or present them to customers.
# Download batch inference results
download_batch_inference_results = PythonOperator(
task_id='Download_Batch_Inference_Results',
python_callable=download_batch_inference_results,
op_kwargs={
'local_dir': '/home/ubuntu/airflow/data'
}
)Putting it all together
Let’s define the Airflow DAG that integrates all the above steps and we can run DAG at scheduled intervals.
with DAG(
dag_id="Tweets_Data_Pipeline",
start_date=datetime(2023, 3, 26),
schedule_interval=timedelta(days=1),
catchup=False,
) as dag:
start_task = DummyOperator(task_id='start')
end_task = DummyOperator(task_id='end')
start_task >> download_tweets_dataset >> clean_tweets_dataset >> prepare_batch_request >> trigger_tweets_batch_inference_job >> end_task
start_task >> check_batch_inference_job_status >> download_batch_inference_results >> end_taskNow DAG is ready, let’s look at Airflow web UI.

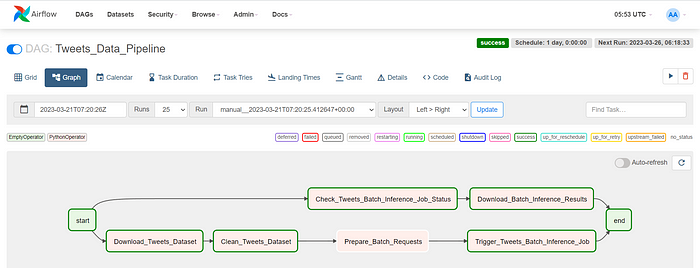
We can notice that two flows execute in parallel, first flow takes care of downloading, cleaning the tweets dataset, preparing batch requests, and triggering batch inference job. The second flow waits for the message to be available in SQS which is triggered by the batch inference job monitoring event and then downloads the batch inference results.
Finally, we can verify tweets batch inference results — tweet_data.json.out placed in the /home/ubuntu/airflow/data directory.
{"prob_score": "0.7765", "label": "Not a disaster"}
{"prob_score": "0.7510", "label": "Not a disaster"}
{"prob_score": "0.8512", "label": "Not a disaster"}
{"prob_score": "0.7282", "label": "Not a disaster"}
{"prob_score": "0.8260", "label": "Not a disaster"}
{"prob_score": "0.6551", "label": "Not a disaster"}🎉Conclusion
In this blog post, we have seen that building an ML inference data pipeline involves quite a bit of preparation but it helps to improve the rate of NLP document enrichment at scale, data engineering productivity, and maintenance of the data pipeline.
We can also leverage Apache Airflow and Amazon SageMaker to build ML workflows such as data collection, data preparation, model training, model evaluation, model provisioning, model deployment, etc.
📚References
- Build end-to-end machine learning workflows with Amazon SageMaker and Apache Airflow
- Apache Airflow installation
- Airflow documentation for additional details on the Airflow Amazon SageMaker operators.
I hope you enjoyed this blog post, if you have any questions, feel free to contact me on LinkedIn and share your experience in the comment section.
The complete source code for this post is available in the following link.
