Understanding BERT
Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. The paper has had a major impact on the field of NLP, and some of its findings are still being applied to current language models. It has been cited over 60,000 times and although it was published more than three years ago, I think it is essential to understand BERT if you want to keep up with current NLP research. This blog post promises to be easier to understand than the underlying research paper, especially for readers not that familiar with the field. Still, it aims to cover all relevant aspects of the paper (excluding exact details on benchmarks and ablation studies). Moreover, the most important theoretical foundations for BERT are explained and additional graphics are provided for illustration purposes. Finally, the impact of the paper and applications of BERT are evaluated from today’s perspective.
Outline
I. Importance of Understanding BERT Today
II. Preliminaries: Transformers and Unsupervised Transfer Learning
II.1 Transformers and Attention
II.2 Unsupervised Transfer Learning: Feature-based vs. Fine-tuning Approach
III. BERT Architecture and Training
III.1 Architecture
III.2 Input Representation
III.3 Pre-Training
-III.3.1 Masked Language Model
-III.3.2 Next Sentence Prediction
-III.3.3 Training Data
III.4 Fine-Tuning
IV. Benchmark Results
V. Contributions of BERT
V.1 Impact
V.2 Follow-up Publications: ALBERT, RoBERTa, BEiT, and Co.
V.3 Applications
VI. Conclusion: BERT as Trend-Setter in NLP and Deep Learning
References
I. Importance of Understanding BERT Today
The importance of language models has never been higher with ChatGPT and co. The latest achievements regarding the capabilities of modern chat systems still go back to the invention of transformers in 2017. One of the most important transformer reference models is BERT from 2019 [1], which achieved state-of-the-art results for various NLP tasks at the time and is still a respected benchmark for some today. BERT stands for Bidirectional Encoder Representations from Transformers and in contrast to classical transformers, is less focused on natural language generation and more on natural language understanding. It has shown that language model pre-training followed by fine-tuning can be effective for a variety of downstream tasks by learning both, token and class embeddings. Reducing the need for task-specific architectures, it became standard to pre-train and use the same language model for different NLP tasks. In addition, BERT introduced bidirectionality in pre-trained transformers, which has advantages over classical left-to-right approaches, especially for language understanding. Because of so many innovations that BERT brought, and because the model is still being used and modified for various applications, even beyond the field of NLP, it is essential to understand BERT.
I would like to help you with this in the following by describing important theoretical basics, explaining the full methodology behind BERT, presenting benchmark results, and evaluating the contributions of the paper.
II. Preliminaries: Transformers and Unsupervised Transfer Learning
This section presents the most important theoretical background to understand BERT. Of course, there are several basics required to delve deeper into current NLP research, such as deep learning basics, tokenization of input data, and RNNs, especially LSTMs — however, these things would go beyond the scope of this blog post and therefore a basic understanding of NLP is assumed.
In contrast, more recent developments in NLP, which are direct foundations for BERT, are described below, so that the methodology behind BERT can be better understood. In particular, the architecture of transformers and the attention mechanism, as well as the idea behind unsupervised transfer learning, especially with fine-tuning, are explained.
II.1 Transformers and Attention
Transformers and the attention mechanism were introduced about two years earlier than BERT by Google AI [2] and represent still one of the most important foundations for modern language models. Before transformers, LSTMs were the state-of-the-art methodology in NLP. However, since each token (and the previous hidden state) is fed consecutively into the same neural network (also referred to as cell), a long chain of operations must be computed during forward pass, which also leads to long gradient computation chains during optimization, also called multi-step backpropagation. This results in information loss and limits the memory of the model.
Attention, the underlying mechanism of transformers, solves these problems by letting the decoder attend to certain input tokens during output creation using an addressing scheme with key/value vectors. Thus, the backpropagation happens in less steps and the attention span (i.e., the context) is unlimited. Attention is calculated by taking the softmax of the dot product of the query and the keys and multiplying it with the values (there is an additional normalization factor).
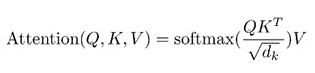
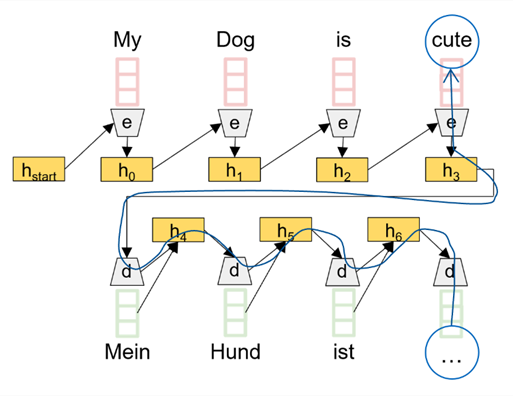
Based on this mechanism, transformers use an encoder-decoder architecture that is particularly designed for natural language generation tasks. The respective input data is represented by classical embeddings with additional positional encoding.
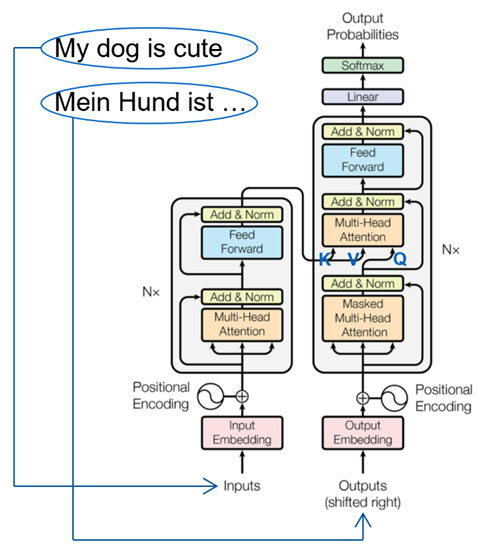
The task input (e.g., the sentence to be translated) is forwarded to the encoder where it is passed through a self-attention layer. The queries, keys, and values are each the input embeddings themselves (therefore “self-attention”) whereby relationships between them are learned, i.e., each token learns which tokens it should pay more attention to.
Similar to the encoder there is also a self-attention layer in the decoder. This takes the previous transformer output as input and learns relationships between these tokens. Since a token should not be able to attend to tokens created in the future, masked self-attention is used in the decoder. This is realized by simply overwriting future tokens (all right above the matrix diagonal) with zeros.
The final attention mechanism then uses the output of the encoder as keys and values and the output of the previous masked self-attention as queries and thus combines input and target. The results are forwarded to linear output layers and finally to a softmax in order to generate an output probability over all tokens.
This describes the basic architecture behind transformers. In addition, there are typically several layers of the described encoder and decoder blocks to form a deep neural network. Furthermore, due to a mostly high number of input tokens, the attention computation is usually parallelized in several so-called attention heads. I.e., each attention head gets only a fraction of the input tokens as input, which reduces the size of the matrices to be computed. Afterwards, the outputs of each head are concatenated to calculate the required total output of the attention layer. Moreover, transformers use several residual connections, normalization layers, and simple feed forward layers to create a stable deep neural network. These are not described in detail and can be found in the original publication.
The transformer architecture has many advantages over previously used LSTMs and, despite minor modifications, still forms the basis for modern language models such as ChatGPT. As described in more detail below, BERT also uses attention and parts of the transformer architecture.
II.2 Unsupervised Transfer Learning: Feature-based vs. Fine-tuning Approach
Unsupervised transfer learning is a technique to gain knowledge through pre-training a neural net based on large amount of unlabeled input data, and then applying (“transferring”) that knowledge to a downstream task. Because of the vast amount of textual data available on the internet and the state-of-the-art results that the technology enabled, transfer learning became increasingly popular in the field of NLP in the years leading up to the publication of BERT. There are two main approaches to transfer learning: the feature-based and the fine-tuning one.
The feature-based approach has been already used for a longer time and was also applied in publications shortly before BERT, such as ELMo [3]. The idea behind this approach is to extract features from the pre-training model and then to apply those features in another model that solves the downstream task. An example of extracted features would be word or sentence embedding vectors.
The fine-tuning approach was becoming more popular immediately before the release of BERT and used by various teams such as OpenAI in GPT [4] about a year before BERT. With fine-tuning, the exact same model is first pre-trained and subsequentially further trained (“fine-tuned”) on the downstream task. In doing so, the model keeps the parameters learned during pre-training — either only for weight initialization or it freezes the parameters (or some of them) and lets the model learn only the weights of the last and/or additional output layers. The graphic below visualizes the difference between the two approaches.
BERT utilizes the fine-tuning approach for pre-training a transformer encoder. Its fine-tuning procedure is therefore described in more detail in section 3.
III. BERT Architecture and Training
In the following, I explain the core idea behind BERT by first describing the architecture and input representation, and subsequentially the pre-training and fine-tuning procedure.
III.1 Architecture
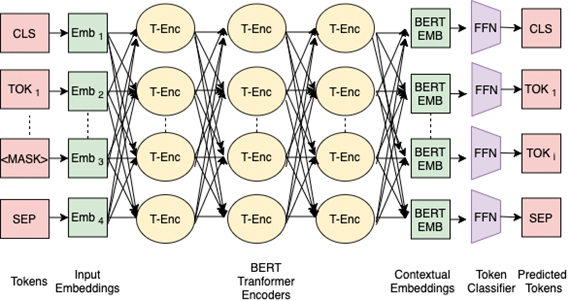
The overall architecture builds on the concept behind transformers and the attention mechanism. However, BERT just has the encoder part and omits the decoder part of classical transformers. To be more precise, the input embeddings are fed into the BERT model which processes them through the layers of the neural net to generate the final hidden vectors. Those final representations are then simply forwarded to an output softmax without any decoding to receive the predicted tokens (see graphic in III.3.1).
Regarding the specific architectural design, the researchers present two standard BERT models, BERT_BASE and BERT_LARGE, which have the following specifications:
· BERT_BASE: 12 layers à 768 hidden tokens and 12 attention heads à resulting in ~110M total parameters
· BERT_LARGE: 24 layers à 1024 hidden tokens and 16 attention heads à resulting in ~340M total parameters
III.2 Input Representation
The input data is represented as a sequence of embedding vectors, using Google’s WordPiece embeddings [6] and a 30,000 token vocabulary. To apply BERT on both, token- and sentence-level tasks, an additional classification token (<CLS>) is added at the beginning of every input sequence, that can be used as an aggregate sequence representation (e.g., for classification tasks).
Moreover, each input sequence can consist of one or two input sentences. For this there is another special token (<SEP>), that separates the sentences, as well as an additional segment embedding, which indicates whether the respective token belongs to input sentence A or B. Thus, tasks requiring a sentence pair (e.g., question-answering) can also be represented for BERT. For one-sentence tasks, the <SEP> token as well as the additional embeddings for sentence B are simply omitted.
Last but not least, there is standard positional encoding applied to differentiate between the exact position of individual tokens in an input sequence.
Overall, the input sequence is represented by summing the token, segment, and position embedding for each token as depicted in the graphic above.
III.3 Pre-training
The core idea behind BERT is excessive pre-training, which allows the model to be fine-tuned for various tasks. There are two unsupervised resp. self-supervised pre-training tasks, one at token level (masked language model) and one at sentence level (next sentence prediction).
III.3.1 Masked Language Model
In contrast to traditional left-to-right (or right-to-left) language model pre-training, BERT tries to train a bidirectional representation of the input. Instead of letting the model predict the next word, it uses the idea of randomly masking a certain percentage of the input tokens and predicting those. More specifically, 15% of the input tokens are randomly replaced with a <MASK> token and the final hidden vectors of those masked tokens are then directed into an output softmax to predict the corresponding input token.
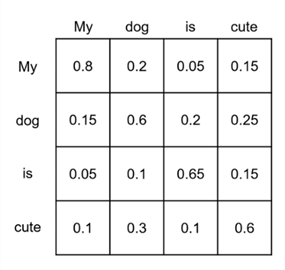
Through this process, BERT learns a bidirectional representation of the input data, since each token can attendee any other token and not just previous or following ones as in left-to-right or right-to-left approaches. Unlike in ELMo which concatenates independently trained left-to-right and right-to-left models, BERT’s representations are truly bidirectional, i.e., they are conditioned on left and right context in all layers (see the graphic below). In the ablation studies, the authors can demonstrate that this approach yields performance improvements over classical ones.
Experienced machine learning researchers or practitioners might have already noticed a weakness of this method — masking tokens causes a mismatch of input data between the pre-training and the fine-tuning for the downstream task. This usually weakens the ability of models to generalize what they have learned and apply it to unseen data. To mitigate this risk, the 15% randomly chosen tokens to be masked are not always replaced with the <MASK> token. The researchers have conducted some empirical comparisons to find out the most successful method. Replacing only 80% of the 15% randomly chosen tokens (i.e., 12% of all input tokens) with the <MASK> token, 10% (1.5% of all) with a random other token and not to mask the remaining 10% (1.5% of all) yielded the best results.
III.3.2 Next Sentence Prediction
For downstream tasks that also require an understanding of the relationship between two sentences, the researchers additionally introduced the pre-training task next sentence prediction. For this, the input sequences are chosen in such a way that in 50% of the cases sentence B really follows sentence A and in the other 50% B is simply a random sentence from the input data. The input sequences are labeled with IsNext or NotNext respectively and the <CLS> token is used to predict this accordingly. Although this pre-training task is very simple and was not typical before BERT, the authors were able to show it significantly increases performance for tasks such as question-answering and natural language inference (improvements in the benchmarks MNLI-m, QNLI, and SQuAD v1.1).
III.3.3 Training Data
In terms of the training data, BERT requires a document-level corpus instead of a shuffled sentence-level corpus so that continuous sequences can be extracted which is important for next sentence prediction. For this purpose, the authors used the BookCorpus with ~800M words [8] and the entire English Wikipedia corpus (except for lists, tables, and headers) with ~2,500M words.
III.4 Fine-tuning
To apply BERT in actual downstream tasks, the model is fine-tuned for a specific task after the pre-training described above. In each case, the task-specific inputs and outputs are connected to the pre-trained BERT model and then all parameters are further trained (“fine-tuned”) end-to-end for the downstream task. Practitioners have also had success with fine-tuning strategies that freeze some layers from the pre-trained BERT during fine-tuning — in the original publication, however, all parameters are fine-tuned end-to-end.
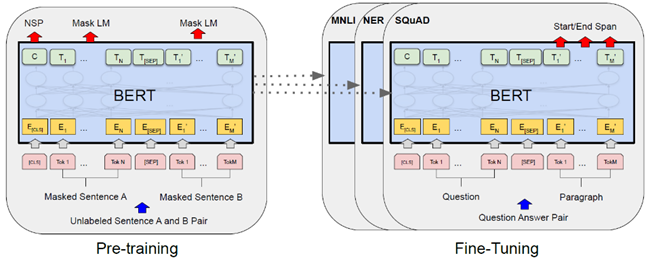
For the wide range of NLP tasks that BERT covers, the task-specific inputs and outputs must be represented appropriately. In terms of input, sentences A and B of the pre-training sequences resemble…
· sentence pairs for paraphrasing tasks,
· hypothesis-premise pairs for entailment (resp. natural language inference) tasks,
· question-passage pairs for question-answering tasks, and
· degenerate text-∅ pairs (without a sentence B) for text classification tasks.
Regarding the output, for…
· token-level tasks (e.g., question-answering or sequence tagging) the token representations are forwarded to the output layer, and for
· classification tasks (e.g., entailment or sentiment analysis) the class representation (<CLS>) is forwarded to the output layer.
A significant advantage this fine-tuning approach has for practitioners is that once the model is pre-trained, it can be fine-tuned for specific tasks relatively inexpensively and quickly. For example, the authors describe that fine-tuning for each task presented in the paper can be replicated in an hour or less on a single cloud TPU (equivalent to a couple of hours on a GPU).
IV. Benchmark Results
This section presents the benchmark results of BERT reported in the paper. Since the focus of this blog post is rather to understand the methodology behind BERT and to classify its contributions in terms of impact and applications of the model, it is kept comparatively short and gives only a rough overview in which NLP tasks BERT could achieve state-of-the-art results. Details on all benchmark scores, the fine-tuning procedure, and hyperparameters are described in the original paper. In total, the researchers applied BERT on eleven well-known natural language understanding tasks: eight from the GLUE benchmark [9], SQuAD v1.1 [10], SQuAD v2.0 [11], and SWAG [12].
GLUE
BERT is evaluated for all GLUE tasks except for WNLI (problematic dataset), thus on a wide variety of NLP tasks including sentiment analysis, linguistic acceptability, paraphrasing, textual similarity, and natural language inference. Overall BERT_LARGE obtains an official GLUE score of 80.5 and thus significantly outperforms OpenAI’s GPT which obtained 72.8.
SQuAD v1.1 and SQuAD v2.0
The authors evaluated different versions of BERT on the Stanford question answering task v1.1 and v2.0. Even simpler systems such as a single BERT_LARGE model without additional public data achieve state-of-the-art results on both benchmarks. For v1.1, the researchers tried out more complex BERT applications that adopt methods from previous state-of-the-art models such as ensembling and adding additional public data and thereby, outperform them significantly.
SWAG
SWAG is a dataset for a special form of natural language inference, in which BERT_LARGE could also achieve state-of-the-art results. It outperforms the best previous systems significantly, i.e., ESIM+ELMo by 27% and OpenAI’s GPT by 8%.
Overall, BERT achieves state-of-the-art results in various natural language understanding tasks, outperforming the best previous models. Through comparing the results of BERT_BASE and BERT_LARGE, the authors additionally found that scaling to extreme model size leads to large improvements, given that the model has been pre-trained sufficiently.
V. Contributions of BERT
In the following, I discuss BERT’s contributions from today’s perspective. I first evaluate the impact of the paper on the field of NLP, then introduce some follow-up publications, and finally describe applications of the model, some of which still take place today.
V.1 Impact
In terms of his impact, many would say that BERT revolutionized the NLP field. In particular, the paper demonstrated the power of pre-training general language models and then fine-tuning them for specific downstream tasks. By using complex representations (both token and class embeddings), the pre-trained model could be used for both token- and sentence-level tasks. This reduced the need to design task-specific architectures and yet BERT achieved state-of-the-art results in eleven different NLP tasks at the time. Thus, the fine-tuning approach became the de-facto standard in the field of NLP and found application beyond. In addition, BERT introduced bidirectionality in transformers for the first time, which brings performance improvements to natural language understanding tasks and is partly still used today. By comparing BERT_BASE and BERT_LARGE, the paper also provided the first evidence that massive scaling of the parameters of a language model with appropriate pre-training causes significant performance increases.
All in all, BERT left its mark on the field with various valuable contributions that are still used in state-of-the-art models today. This impact is underlined by more than 60,000 citations.
V.2 Follow-up Publications: ALBERT, RoBERTa, BEiT, and Co.
Furthermore, BERT brought with it a rat’s tail of follow-up publications that have a variation of “BERT“ in their name. There are for example ALBERT, RoBERTa, DistilBERT, CamemBERT, BEiT, and ClipBERT [13, 14, 15, 16] to name just a few. These publications either present small improvements of BERT, such as ALBERT and RoBERTa, or apply the principles behind BERT in other application areas, such as BEiT and ClipBERT in computer vision. The high number of follow-up publications in various disciplines again confirms the relevance of BERT.
V.3 Applications
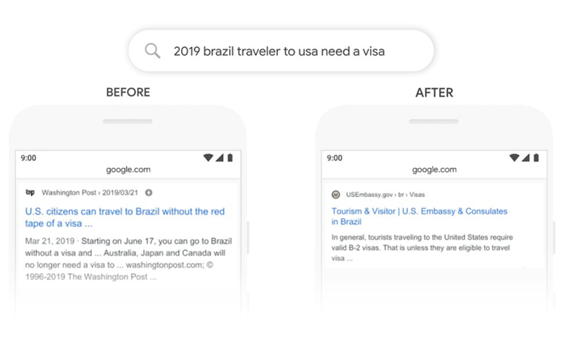
Since BERT achieved various state-of-the-art results and was also made open source by Google, it was widely used, especially in the period after its release. Furthermore, BERT is still used today for some applications. On the one hand, BERT is still used by many companies in production, which can be explained by the fact that application development often takes longer than research produces new language models. In addition, it is known that Google has integrated BERT into its search algorithm to better understand search queries [17]. BERT is also often used for systems with certain requirements, such as FPGAs, because it uses fewer parameters than more current models. In addition, there are the follow-up publications just described, which are of course also applications of BERT in a certain form. All in all, BERT has been applied in many different scenarios and is still applied in specific ones.
VI. Conclusion: BERT as a trend-setter in NLP and Deep Learning
Overall, BERT is a language model that can be seen as a trend-setter in the field of NLP and deep learning in general. In particular, the principle of pre-training large general-purpose models and then fine-tuning them for specific downstream tasks has become standard in NLP and a popular approach in other disciplines. The principle of fully bidirectional transformers was first introduced in the paper as well. Moreover, BERT achieved state-of-the-art results in eleven NLP tasks, spawned a long tail of direct follow-up publications, and is still used for some applications today. Therefore, you should make sure to have a good understanding of BERT when engaging with current NLP research — I hope this blog post could help you with that.
References
[1] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv:1810.04805.
[2] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
[3] Peters, M. E., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., & Zettlemoyer, L. (2018). Deep contextualized word representations. arXiv:1802.05365.
[4] Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding with unsupervised learning. Technical Report, OpenAI.
[5] Yang, A. (2022). Feature-based Transfer Learning vs. Fine-Tuning. https://medium.com/@angelina.yang/feature-based-transfer-learning-vs-fine-tuning-bc8fc348a33d
[6] Song, X. (2021). A fast WordPiece Tokenization System.
https://ai.googleblog.com/2021/12/a-fast-wordpiece-tokenization-system.html
[7] Banerjee, P., Pal, K., Wang, F., & Baral, C. (2021). Variable Name Recovery in Decompiled Binary Code using Constrained Masked Language Modeling. https://doi.org/10.48550/arXiv.2103.12801
[8] HuggingFace. (2023) BookCorpus. https://huggingface.co/datasets/bookcorpus
[9] Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., & Bowman, S. R. (2018). GLUE: A multi-task benchmark and analysis platform for natural language understanding. arXiv:1804.07461.
[10] Rajpurkar, P., Zhang, J., Lopyrev, K., & Liang, P. (2016). Squad: 100,000+ questions for machine comprehension of text. arXiv:1606.05250.
[11] Rajpurkar, P., Jia, R., & Liang, P. (2018). Know what you don’t know: Unanswerable questions for SQuAD. arXiv:1806.03822.
[12] Zellers, R., Bisk, Y., Schwartz, R., & Choi, Y. (2018). SWAG: A large-scale adversarial dataset for grounded commonsense inference. arXiv:1808.05326.
[13] Kotamraju, S. (2022). Everything you need to know about ALBERT, RoBERTa, and DistilBERT. https://towardsdatascience.com/everything-you-need-to-know-about-albert-roberta-and-distilbert-11a74334b2da
[14] HuggingFace. (2023). CamemBERT. https://huggingface.co/docs/transformers/model_doc/camembert
[15] Bao, H., Dong, L., Piao, S., & Wei, F. (2021). BEiT: Bert pre-training of image transformers. arXiv:2106.08254.
[16] Lei, J., Li, L., Zhou, L., Gan, Z., Berg, T. L., Bansal, M., & Liu, J. (2021). Less is more: ClipBERT for video-and-language learning via sparse sampling. arXiv:2102.06183.
[17] Roy, J. (2022). Everything you need to know about Google BERT. https://seositecheckup.com/articles/everything-you-need-to-know-about-google-bert
